iOS12 Kernelcache Laundering
iOS12 is no exception to the rule and comes with an other surprise: Pointer Authentication Code (PAC) for the new A12 chip.
This blogpost shows you how to deal with both by enhancing IDA. IDA 7.2 beta future release might add PAC and iOS12 kernelcache support but it will only be released in a few weeks and we think it will always be interesting to illustrate how to do it by ourselves.
Looking to improve your skills? Discover our trainings sessions! Learn more.
TL;DR: support of the PAC instructions and the iOS12 kernelcache relocations via two IDAPython plugins.
PAC
We will not present PAC, if you want to know more, you can read this presentation by Mark Rutland or directly the documentation. Despite all the bragging and the obvious fact that PAC is not perfect, it is still a major step in the good direction. It makes some vulnerabilities unexploitable (particularly in constrained environment), others become significantly harder to exploit and may require additionnal vulnerabilities.
{kind=link}
For example, a stack based buffer overflow resulting in a direct control of PC in a service exposed on USB (that could be used to develop a GrayKey like device) is likely to become unexploitable but a vulnerability in JavaScriptCore giving arbitrary RW access is likely to be exploitable... Anyway, Apple can really take pride in this feature that, once again, places it a step ahead its competitors.
We will not present IDA neither, as you may know, IDA doesn't support PAC instructions yet (but should in the next version). @xerub already provided a plugin to deal with it but it has several drawbacks:
- the display is not perfect (operand alignment is not respected, yes, it's important!)
- it's in C++ (fast but hard to tweak)
- it doesn't work well with Hex-Rays Decompiler
The last point is obviously the most important one. Under the hood, xerub translates the PAC instructions into their non-PAC equivalent, RETAA is translated into a RET for example, the plugin then just makes sure that they are correctly displayed by putting an identifier in the insn insnpref field. Thanks to this, Hex-Rays Decompiler sees only classic ARM instructions and is able to decompile functions that use the authenticated versions of RET, BLR, BR, ERET and LDR.
However, PACXXX instructions (like PACIA) don't have any non PAC equivalents. xerub translates them as HINT (which they are on ARMv8 processors that don't support PAC). The problem is that Hex-Rays Decompiler doesn't know how to translate HINT instructions into microcode and puts __asm {...} blocks. When Hex-Rays Decompiler puts __asm blocks, it tries to glue the C code with them by detecting what's used and modified by the __asm block. Hex-Rays Decompiler next creates new variables with register-like names that make the code easily understandable:
// the code we would like to have
void sub_XXX()
{
__asm { PACIBSP }
_X8 = qword_XXXX;
_X9 = 0x1234;
__asm
{
AUTIZA X8
PACIA X8, X9
}
qword_YYY = _X8;
return 1;
}
To know what registers are read, Hex-Rays uses the instruction feature bits, those bits are defined per instruction definition, are specific to a processor_t object and cannot be edited by a plugin (see the instruc_t, feature bits and processor_t documentation).
Among other things, those bits define which operands are used or changed by the instruction. You can add a user-defined instruction to a processor by specifying an insn itype greater or equal to CUSTOM_CMD_ITYPE but this instruction would have its feature bits set to 0 (see has_insn_feature code). The problem is that the HINT feature bits have only the CF_USE1 bit.
This means that Hex-Rays Decompiler will consider that the PAC* instructions only use their first operand and will optimize the code according to this, removing important statements and making wrong assumptions:
// the code we get
void sub_XXX()
{
__asm { PACIBSP }
_X8 = qword_XXXX;
__asm
{
AUTIZA X8
PACIA X8, X9
}
qword_YYY = qword_XXXX;
return 1;
}
A solution could be to patch the ARM processor plugin to modify the HINT feature bits but that would be inelegant. An other, much more elegant, solution would be to develop an Hex-Rays Decompiler plugin to add PAC intrinsics, like the one Dougall J did for VMX, but the microcode API is not exposed to IDAPython (yet?) and we don't want to force people to compile our tool.
Instead, we decided to use an instruction already present in IDA's ARM64 processor_t that has the following properties:
- has two operands
- uses both of them
- changes only the first one
- not decompiled by Hex-Rays Decompiler
A little Python one liner gives us the instructions fulfilling the three first conditions:
print "\n".join(n for n,v in idaapi.ph_get_instruc() if v == idaapi.CF_CHG1 | idaapi.CF_USE1 | idaapi.CF_USE2)
The problem is that no instructions match... This isn't surprising given that most of ARM instructions use three operands, the first being the destination and the two others the sources. We decided to search for all instructions that match this behavior with the following line:
print "\n".join(n for n,v in idaapi.ph_get_instruc() if v == idaapi.CF_CHG1 | idaapi.CF_USE2 | idaapi.CF_USE3)
To our surprise, the instruction HLT matched (along with ERET, HVC and others). This instruction doesn't even have three operands, it only has one which is an immediate and isn't modified (obviously) but used. This is probably a copy/paste error or, this error having no consequences, just the developer being lazy. HLT is not decompiled by Hex-Rays Decompiler so it's a perfect candidate! We just have to add an hidden third operand to our instruction, equal to the first, to achieve our goal.
We developed an IDAPython script, available on our Github repository, that does just that. Surprisingly, although being coded in Python, the plugin doesn't noticeably slow down the analysis.
As a bonus, we also added an ev_emu_insn callback to force IDA to consider BRK as a breaking instruction (if you want to know more about this, you can read this article).
Below is a screenshot of the kernelcache relocation function, with PAC instructions, correctly decompiled by Hex-Rays Decompiler thanks to our plugin:
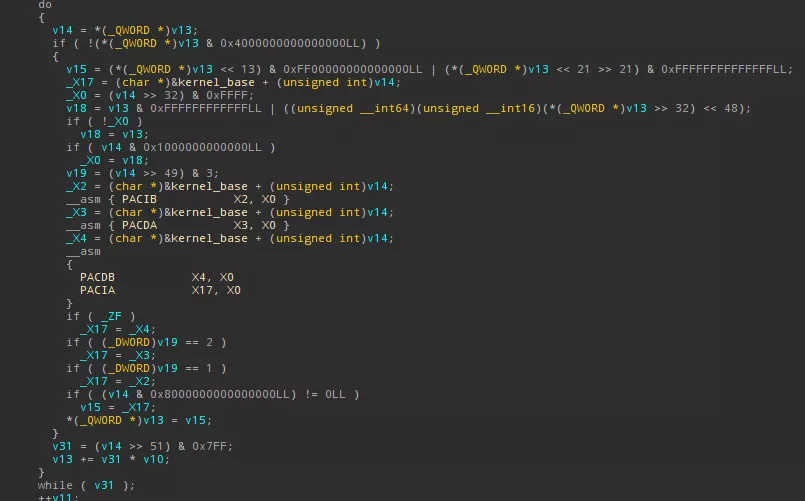
Kernelcache
Because of the ASLR, pointers in the kernelcache need to be relocated and because of PAC, some needs to be authenticated. To do that, the iOS12 kernelcache uses a new relocation mechanism, very similar to the userland dyld_shared_cache mechanism. Brandon Azad already had this intuition and coded something to clean the kernelcache however his code is incomplete and a lot of pointers are not correctly cleaned. Moreover, by cleaning the pointers you lose the relocation and PAC infos as they are stored in the pointer unused high bits.
By searching PACIA instructions in the kernelcache, you quickly find both the kernelcache and dyld_shared_cache relocation handling codes. We reversed and reimplemented this code for the kernelcache in an IDAPython plugin, we also add an auto-comment for each pointer to tell if and how it is signed and we transform it into an offset. This is done transparently and automatically when you load an iOS 12 kernelcache in IDA.
Again, the code is available on our Github repository. The mechanism is not really interesting and the code is self-explanatory, so we won't bother our reader by detailing them. The dyld_shared_cache code is left as an exercise for the reader but it is quite similar to the kernelcache one and easy to implement.
Below is a screenshot of a vtable with protected pointers, these are automatically decoded and annotated by our plugin:
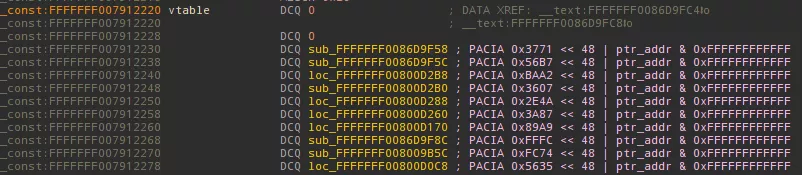
Outro
We finish this blogpost with a quote from Rolf Rolles that our blogpost illustrates well:
I think Hex-Rays doesn't get enough credit. Their products may be proprietary, expensive, and idiosyncratic, but they're robust, powerful, work well by default, and are endlessly configurable/customizable. At the end of the day, I've got stuff to do and my tools need to work now.