AWS Forensics : What you need to know
De nos jours, il est rare de trouver une entreprise dont le système informatique ne repose pas, au moins en partie, sur les technologies cloud. Ces solutions offrent de nombreux avantages, notamment en termes de déploiement rapide des services et de l'infrastructure. Cependant, ces technologies requièrent des compétences et des connaissances spécifiques pour assurer l'administration au quotidien. La même logique s'applique à la gestion d'un incident dans ces environnements.
Si vous êtes analyste en réponse à incident ou sécurité et que vous ne connaissez peu AWS, cet article peut vous servir de point de départ pour comprendre les principes fondamentaux d'AWS dans le contexte du traitement d'un incident.
Vous souhaitez améliorer vos compétences ? Découvrez nos sessions de formation ! En savoir plus
Introduction
Contrairement à Microsoft Azure et à Entra ID, qui sont principalement utilisés comme extensions du système d'information interne et bureautique, les services Amazon Web Services (AWS) servent essentiellement à déployer des applications externes. Au cours des dernières années, AWS a publié un certain nombre de recommandations en matière de sécurité, notamment un plan complet de gestion des incidents. Cependant, ce dernier peut être difficile à mettre en œuvre pour la plupart des entreprises en cas d'incident de sécurité.
Cet article a pour objectif de fournir un point de départ clair et pratique à tout analyste peu expérimenté qui doit gérer un incident sur AWS. Il ne prétend pas se substituer à la documentation officielle ni à une formation adéquate, ni couvrir tous les aspects en détail, en particulier les sujets relatifs réseau, qui mériterait à lui seul un article complet. Il n'aborde pas non plus les coûts liés au déploiement de différents services ou composants, car ceux-ci varient considérablement en fonction du service ou de la ressource utilisée.
Gestion des identités et des accès
Organisation et Compte AWS
Un environnement AWS s'articule autour d'une organisation AWS, qui en constitue la structure de base. Elle équivaut à un tenant Azure dans l'écosystème Microsoft. Cette organisation est composée de comptes AWS, qui servent à déployer et à gérer les ressources. Un compte AWS correspond à un espace isolé ou à un conteneur au sein duquel des ressources peuvent être créées, configurées et gérées.
Le compte de gestion est le compte principal de l'organisation. Il permet d'administrer l'ensemble de l'environnement AWS, de centraliser la facturation et de « coordonner » le déploiement des autres comptes. Chaque organisation AWS ne dispose que d'un seul compte de gestion.
Les comptes membres servent à déployer et à isoler les ressources en fonction des exigences métier ou techniques. Il est courant de disposer de comptes dédiés aux environnements de test, aux environnements de production ou à différents types d'activités.
Au sein du compte de gestion, il est également possible de regrouper les comptes membres en unités organisationnelles. Ces unités permettent de regrouper plusieurs comptes AWS auxquels il est possible d'appliquer un ensemble de règles communes (structure, autorisations, configuration, etc.).
Dans certains cas, certaines ressources peuvent être déployées directement à partir du compte de gestion. Cependant, cette pratique est généralement déconseillée dans les environnements de production et peut-être le signe d’une anomalie.
Le schéma suivant présente les principaux éléments qui composent une organisation AWS :
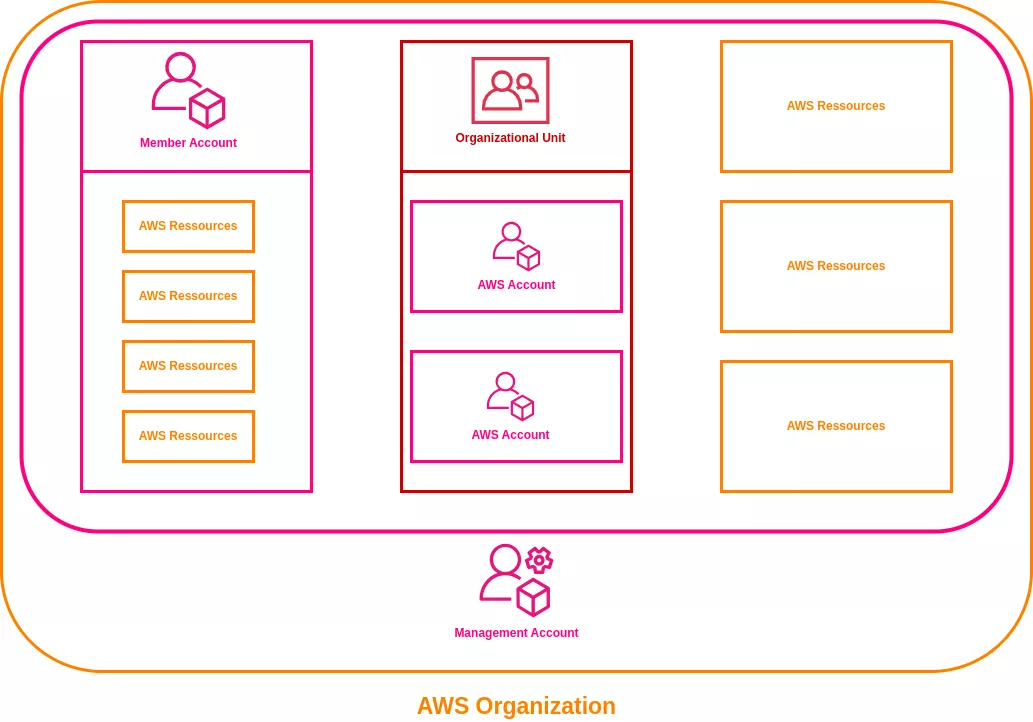
Chaque compte AWS est identifié par un numéro à 12 chiffres, tel que 012345678901, il s'agit de l'ID de compte. Il sert à distinguer les ressources d'un compte de celles d'un autre compte.
Identité
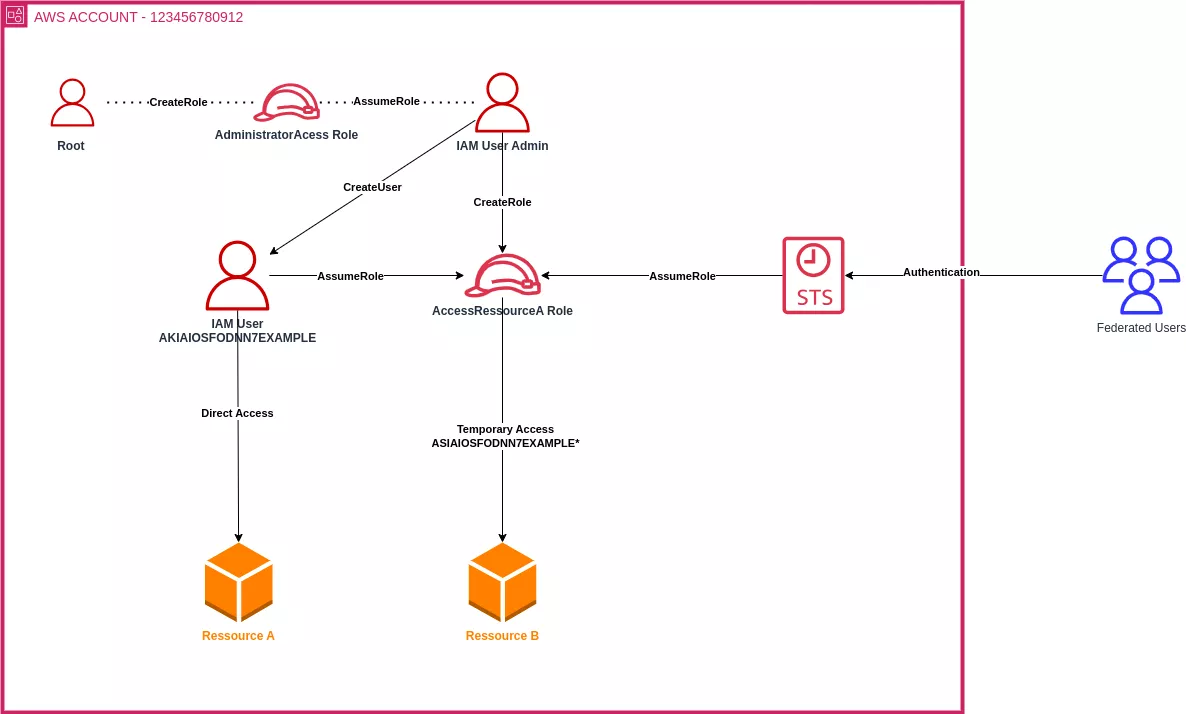
La gestion des comptes AWS repose sur des comptes utilisateur appelés « identités ». Dans AWS, le terme « identité » désigne une entité (une personne ou une ressource « programmable ») capable de s'authentifier et disposant des droits nécessaires pour accéder aux ressources et effectuer des actions. Il existe quatre types principaux d'identités : l'utilisateur root, l'utilisateur IAM, les identités fédérées et les rôles IAM.
Une ressource programmable est un service ou un composant pouvant être contrôlé par programmation à l'aide d'une API ou d'un SDK afin d'automatiser des tâches. Contrairement aux ressources statiques, elles peuvent s'authentifier, effectuer des actions à l'aide d'autorisations temporaires et interagir avec d'autres services AWS.
L'utilisateur root (compte utilisateur) est l'identité principale et unique de chaque compte AWS (une identité root par compte uniquement). Il dispose de tous les privilèges nécessaires à l'administration du compte. L'accès est accordé via l'adresse e-mail associée au compte, un mot de passe et un deuxième facteur d'authentification (généralement physique, comme le recommande AWS, mais il peut également être virtuel). Comme il s'agit de l'identité la plus sensible au sein du compte, elle est souvent réservée à la gestion de la facturation, aux actions de restauration ou à la modification des autorisations à l'échelle du compte AWS. L'administration quotidienne est généralement déléguée à une autre identité.
Un rôle IAM est une identité temporaire, une sorte de conteneur qui regroupe des autorisations permettant d'accéder à des ressources et d'effectuer des actions. Les utilisateurs ou services autorisés peuvent endosser (c'est-à-dire utiliser) ce rôle pour obtenir des privilèges temporaires. Ce mécanisme est particulièrement utile pour l'accès à plusieurs comptes ou pour déléguer les tâches administratives quotidiennes sans avoir à recourir à l'utilisateur root.
Les utilisateurs IAM sont des identités associées à un compte AWS et sont identifiés de manière unique au sein de ce compte. Ils accèdent à la console AWS à l’aide d’un nom d’utilisateur, d’un mot de passe et d’un ID de compte, ou via un accès programmatique utilisant des clés API permanentes (identifiées par le préfixe AKIA*).
Les identités fédérées permettent d'accéder à AWS via un fournisseur d'identité externe tel qu'Okta, Microsoft Entra ID (anciennement Azure AD) ou Google, à l'aide des protocoles SAML ou OIDC. Elles peuvent se voir accorder un accès temporaire à différents comptes en assumant des rôles IAM et en utilisant des clés API temporaires (identifiées par le préfixe ASIA*).
Le schéma suivant présente un aperçu simplifié des types d'identité pouvant être associés à un compte AWS :
Permissions
Pour identifier une ressource de manière univoque sur l'ensemble de l'infrastructure AWS, on utilise les noms de ressources Amazon (ARN - Amazon Resource Names). La structure d'un ARN est la suivante : arn:partition:service:region:account-id:resource-type/resource-id
Les permissions dans AWS sont gérées par le service IAM, qui définit qui peut accéder à quelles ressources et effectuer quelles actions. Ces autorisations sont décrites dans un document JSON structuré de la manière suivante :
- Version : indique la version du langage de politique utilisé. La version
2012-10-17est la plus récente ; elle définit la syntaxe et les fonctionnalités disponibles. - Statement : il s'agit du cœur de la politique. Elle contient l'ensemble des instructions qui définissent les règles d'accès.
- Effect : précise si l'action est autorisée (
Allow) ou refusée (Deny). Par défaut, tout est refusé (refus implicite), et une instruction Deny a toujours la priorité sur les autres. - Action : définit la liste des actions AWS autorisées ou refusées sur une ressource. Le niveau de granularité permet de cibler une action spécifique sur une ressource, ou au contraire toutes les actions via un caractère générique (*).
- Resource : contient l'ARN de la ressource AWS concernée. Il prend souvent la forme
arn:aws:resource_type:::my_resource/*. Le wildcard est utilisé lorsque la ressource contient plusieurs sous-éléments auxquels la politique doit s'appliquer.
Dans certains cas, d’autres champs peuvent également être présents, parfois de manière optionnelle :
- Principal : dans le cas d’une politique basée sur une ressource, il peut être nécessaire de préciser le compte AWS ou l’identité à laquelle la policy s’applique. Ce champ ne s’utilise pas dans le cas d’une policy associée à un rôle.
- Sid : identifiant facultatif permettant de différencier plusieurs instructions au sein d’un même statement.
- Condition : permet d’ajouter des contraintes spécifiques à la règle, par exemple pour limiter certaines actions à une plage d’adresses IP donnée.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3ReadWrite",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::my-bucket-prod",
"arn:aws:s3:::my-bucket-prod/*"
],
"Condition": {
"Bool": {
"aws:MultiFactorAuthPresent": "true"
},
"IpAddress": {
"aws:SourceIp": "203.0.113.0/24"
}
}
},
}
Dans cet exemple, nous définissons une politique nommée S3ReadWrite. Cette permission permet aux utilisateurs d'accéder aux fichiers, d'afficher la liste des fichiers et de créer des fichiers dans le bucket « my-bucket-prod », à condition qu'ils soient authentifiés avec l'authentification à deux facteurs et qu'ils utilisent une plage d'adresses IP spécifique.
Par ailleurs, on distingue plusieurs types de politiques (permissions) dans AWS selon la manière dont elles sont appliquées..
Les politiques basées sur les identités (Identity Based Policy) correspondent aux permissions directement accordées (ou attachées) à des utilisateurs, des rôles ou des groupes. Elles se déclinent en trois catégories, deux types de politiques gérées et les politiques inline:
- Les politiques gérées par AWS (AWS managed policies) sont créées et maintenues par AWS. Elles sont génériques et peuvent être attachées à plusieurs identités.
- Les politiques gérées par le client (Customer managed policies) sont créées par l’utilisateur. Elles permettent de créer des permissions personnalisées et peuvent également être réutilisées sur plusieurs identités.
- Les politiques inline (Inline policies), en revanche, sont associées à une seule identité et ne peuvent pas être partagées. Elles servent généralement à appliquer des restrictions spécifiques, par exemple pour gérer une identité externe à l'organisation, ou pour empêcher qu'une politique très permissive (telle que des droits d'administration délégués) ne soit appliquée par inadvertance à d'autres identités.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ReadBucketS3",
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": "arn:aws:s3:::my-bucket-example/*"
}
]
}
Dans l'exemple ci-dessus, la politique autorise un rôle IAM ou un utilisateur à télécharger des fichiers (Action : s3:GetObject) depuis my-bucket-example, mais pas à les supprimer ni à accéder à d'autres buckets.
Les politiques basées sur les ressources (Resource-based policies) correspondent à des permissions définies directement au niveau d'une ressource AWS. Elles précisent explicitement quelles identités (ou entités) sont autorisées à accéder à une ressource. Ainsi, même si une identité dispose d'autorisations étendues via des politiques basées sur les identités, elle ne pourra pas accéder à la ressource à moins d'être mentionnée dans la politique de celle-ci (à l'exception du propriétaire). Ce type de politique est couramment utilisé avec des services comme Amazon S3 et permet de contrôler l'accès directement au niveau de la ressource, indépendamment de la politique associée aux identités.
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"AWS": "arn:aws:iam::123456789012:user/JohnDoe"},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::my-bucket-example/*"
}]
}
Dans l'exemple ci-dessus, il s'agit d'une politique qui s'applique non pas à une identité, mais à une ressource. Dans ce cas, seul l'utilisateur JohnDoe (dont le principal est spécifié) peut lire les objets contenus dans le bucket.
Les limites d'autorisation constituent un mécanisme permettant de fixer une limite maximale aux autorisations accordées à une identité. Elles sont principalement utilisées pour limiter les risques liés à la délégation d'autorisations. Par exemple, une équipe de développeurs peut disposer d'autorisations lui permettant de créer des rôles IAM selon les besoins. Sans contrôle, elle pourrait créer un rôle doté d'autorisations très étendues, telles que s3:*, accordant un accès complet à tous les bucket S3. En appliquant une limite d'autorisation, il est possible d'autoriser la création de rôles tout en restreignant les actions qu'ils peuvent contenir. Dans ce cas, les autorisations pourraient être limitées à s3:GetObject afin d'empêcher des actions sensibles telles que la suppression de bucket.
Les limites d'autorisation sont généralement associées à des rôles IAM ou à des utilisateurs et peuvent être identifiées avec la condition iam:PermissionsBoundary.
Les SCP (Service Control Policies) sont des politiques qui définissent un niveau maximal d'autorisations au niveau d'une organisation AWS, d'une unité organisationnelle (OU) ou d'un compte. Elles s'appliquent à toutes les identités relevant du périmètre concerné, y compris l'utilisateur root de chaque compte. De plus, une règle de « Deny » définie dans une SCP prévaut sur toutes les autres politiques.
À ce stade, une question se pose naturellement : ces différentes politiques peuvent-elles être combinées ? La réponse est oui. Il est donc essentiel de comprendre comment elles interagissent entre elles. Le schéma ci-dessous donne un aperçu de l'ordre dans lequel les différents types de politiques sont évalués.
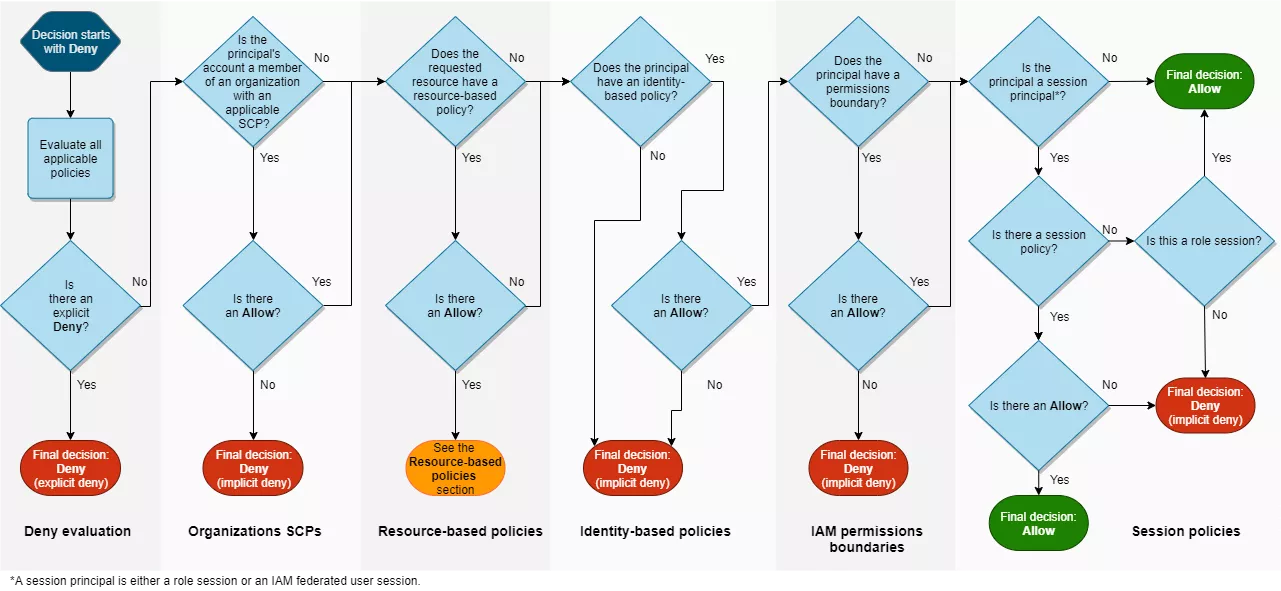
Plus rarement, il est possible de rencontrer d'autres types de politiques. Parmi celles-ci figurent les autorisations basées sur les ACL (listes de contrôle d'accès), qui sont obsolètes depuis 2023, mais qui subsistent encore dans certains environnements pour des raisons historiques. On peut également rencontrer des RCP (politiques de contrôle des ressources) ainsi que des politiques basées sur les sessions.
Les politiques de session permettent d'accorder des autorisations temporaires pour une durée limitée, par exemple une heure. Elles sont particulièrement utiles pour faciliter l'administration en fournissant un accès ponctuel, généralement basé sur un rôle existant, plutôt que de créer un nouveau rôle à chaque fois qu'un besoin se fait sentir.
Dans la pratique, les autorisations sont le plus souvent associées à des rôles IAM, car ceux-ci sont plus simples à gérer et à maintenir au fil du temps.
Landing Zones
Dans les environnements multi-comptes, le concept de « landing zone » (zone d'atterissage) est souvent mal compris. Il est fréquemment réduit à la simple existence de plusieurs comptes accessibles via le portail AWS, chacun étant associé à des rôles différents en fonction de son identité.
Si l'accès à plusieurs comptes peut effectivement résulter d'une landing zones, il est important de comprendre que ce concept ne se limite pas à cela. Une landing zone est une architecture sécurisée pensée pour centraliser la gouvernance et standardiser le déploiement des comptes. Plutôt que de créer chaque compte manuellement, avec le risque d'introduire de fortes incohérences au niveau des politiques, de l'administration et de la sécurité, un cadre commun est établi et s'applique à tous les comptes.
Dans la pratique, une « landing zone » se caractérise généralement par :
- une organisation AWS permettant de centraliser et de structurer les comptes
- des unités organisationnelles (OU) permettant de segmenter les environnements et les cas d’utilisation
- des comptes dédiés à des fonctions spécifiques, telles que la sécurité, la journalisation, les services partagés, l’administration ou les applications
- des politiques globales, telles que les SCP, appliquées à tous les comptes ou à certaines OU, ainsi que des politiques plus ciblées en fonction des types de comptes
- une gestion centralisée des identités, souvent à travers le service IAM Identity Center
- une stratégie réseau commune et prédéfinie couvrant le routage, les VPC, la gestion du trafic et les pare-feu en fonction des types de comptes
- une gestion centralisée des journaux et de la sécurité, afin d’offrir une vue d’ensemble complète de la conformité, de la supervision et des alertes.
Une landing zone comprend généralement les éléments suivants :
- Compte de gestion : utilisé pour créer et organiser les comptes et les unités organisationnelles (OU), ainsi que pour configurer les SCP
- Compte de journalisation : centralise et stocke les journaux d'audit au format brut de manière immuable
- Compte de sécurité et d'audit : héberge les outils de sécurité et permet la supervision, la détection d'événements anormaux et l'audit des ressources déployées sur les différents comptes
- Compte d'infrastructure : gère les ressources partagées et la connectivité réseau, telles que les VPC, le routage ou les pare-feu, afin d'éviter les doublons
- Compte de charge de travail : il est associé à une application, une équipe ou un environnement. Il représente le volet métier ou opérationnel de l'organisation.
Le diagramme suivant illustre l'architecture classique d'une landing zone.
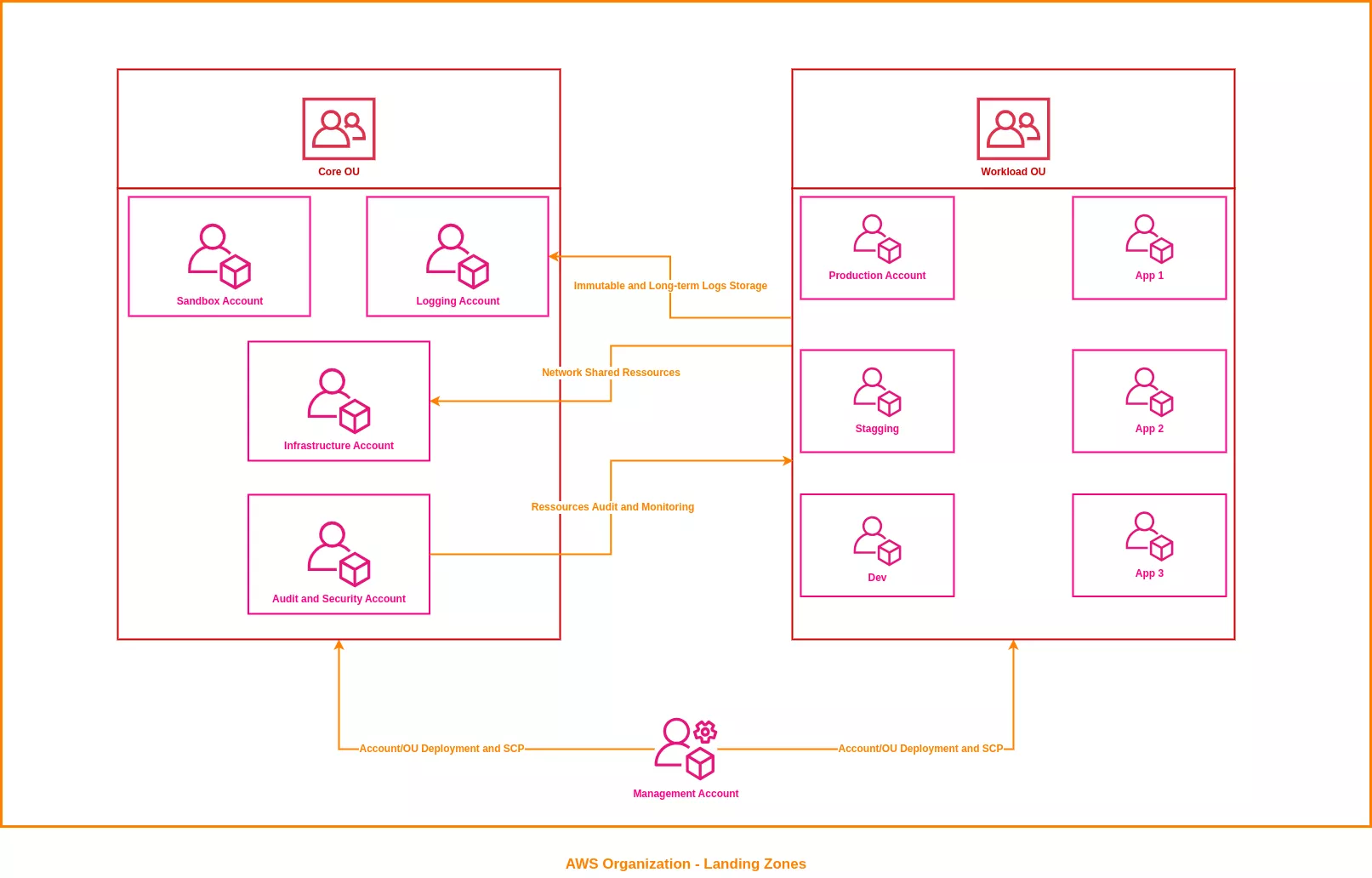
AWS Control Tower est souvent utilisé pour déployer une landing zone, car il fournit un socle de base pour structurer cet environnement.
Ressources et Services
Dans une infrastructure traditionnelle, les entreprises possèdent et gèrent directement les serveurs physiques, le stockage, les équipements réseau ainsi que tous les services et applications associés installés sur site, dont elles sont responsables. Dans un environnement cloud virtualisé, le fournisseur de cloud gère l'ensemble de la couche physique, des serveurs, du réseau et du stockage, et les fournit sous forme de services à la demande. Il s'agit du modèle de responsabilité partagée :
AWS exploite, gère et contrôle les composants, depuis le système d'exploitation hôte et la couche de virtualisation jusqu'à la sécurité physique des installations dans lesquelles le service est exploité. Le client assume la responsabilité et la gestion du système d'exploitation invité (y compris les mises à jour et les correctifs de sécurité), des autres logiciels d'application associés ainsi que de la configuration du pare-feu des groupe de sécurité fourni par AWS.
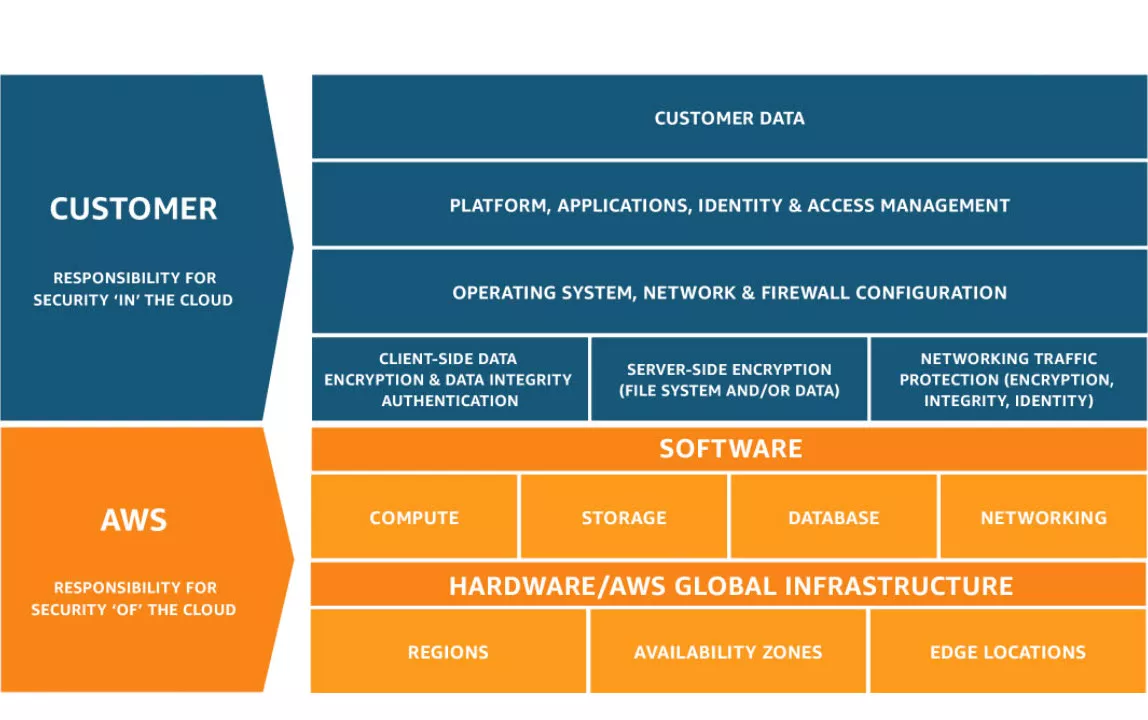
Par conséquent, tous les composants d'infrastructure sont fournis sous forme de services configurables pouvant être provisionnés à la demande. Dans ce premier chapitre, nous nous concentrons sur les services AWS de base, qui sont aujourd'hui plus de 200 au total. En particulier ceux appartenant aux catégories clés suivantes : calcul, conteneurs, bases de données, stockage, sécurité, identité et conformité, réseau et diffusion de contenu (content delivery), et le serverless. Ces catégories couvrent la plupart des composants traditionnels que l'on trouve dans un système d'information classique et sont souvent impliquées dans les incidents de sécurité ou fournissent des informations contextuelles à leur sujet.
Dans AWS, les termes « service » et « ressource » sont parfois utilisés de manière interchangeable, bien que ce soit un abus de langage. En réalité, un service désigne une capacité fonctionnelle offerte par AWS, tandis qu’une ressource désigne un objet ou une instance spécifique qui permet l’utilisation de ce service.
Les ressources AWS partagent souvent plusieurs attributs communs :
- un nom
- un identifiant unique au sein du service
- le compte AWS sur lequel elles sont déployées
- parfois une identité ou des permissions qui leur sont associées
- la région et, le cas échéant, la zone de disponibilité
- leur ARN (Amazon Resource Name), qui est, comme indiqué précédemment, l'identifiant unique de la ressource dans le contexte AWS.
Dans cette section, nous présenterons quelques exemples de ressources couramment utilisées dans AWS, en précisant pour chacune d'elles le service associé, la catégorie, le rôle et les principales caractéristiques AWS. L'objectif est de pouvoir identifier facilement les informations clés et pertinentes relatives à une ressource donnée.
Amazon EC2
- Nom : Amazon Elastic Compute Cloud
- Catégorie : Calcul (compute)
- Description : Instance de serveur virtuel (c'est-à-dire machine virtuelle) dotée de ressources dynamiques (mémoire, CPU, taille, etc.)
- Propriétés principales :
- Instance ID : identifiant alphanumérique unique (par exemple
i-0123456789abcdef0) attribué à une instance de machine virtuelle, principalement utilisé pour la gestion des opérations et le monitoring - IMDS : services REST locaux sur chaque instance EC2 qui fournissent des métadonnées dynamiques telles que l'ID d'instance, les identifiants IAM et les informations réseau
- AMI ID : identifiant alphanumérique unique (par exemple
ami-0123456789abcdef0) utilisé pour identifier le modèle d'image servant à créer une instance de machine virtuelle - AMI Name : nom de l'image utilisée pour créer une instance de machine virtuelle
- Launch time : date de création d'une instance de machine virtuelle
- Instance ARN : identifiant alphanumérique unique (par exemple
arn:aws:ec2:us-east-1:123456789012: instance/i-0123456789abcdef0) qui est une combinaison du serviceec2, de la régionus-east-1, de l'ID de compte123456789012et de l'ID d'instanceinstance/i-0123456789abcdef0. Il est principalement utilisé pour définir des droits via une politique - VPC ID : réseau global associé à l'environnement AWS
- Subnet ID : sous-réseau avec une plage d'adresses IP spécifique associé à l'instance EC2
- IAM Role : identité associée à une instance virtuelle qui fournit des informations d'identification (clé d'accès, clé secrète et jeton) définissant les autorisations sur les ressources AWS
- Owner ID : identifiant du compte (dans l'ARN de l'instance) qui possède et lance l'instance virtuelle)
- Autre information utiles : adresse IP privée, nom de l'instance, DNS
- Instance ID : identifiant alphanumérique unique (par exemple
Amazon Lambda
- Nom : Amazon Lambda
- Catégorie : Calcul (compute)
- Description : Service de calcul serverless qui exécute du code en réponse à des événements, sans nécessiter de provisionnement ni de gestion de serveurs
- Propriétés principales :
- Last modified : dernière modification du code ou de la configuration
- Function ARN : identifiant alphanumérique unique (par exemple
arn:aws:lambda:region:123456789012:function:lambda_name), l'identifiant numérique appartient au propriétaire de la fonction Lambda - Runtime : langage de programmation et version
- Code source : contenu du code source qui est exécuté
- Trigger (si défini) : événement qui déclenche l'exécution du code
- Execution role: rôle IAM accordant des autorisations d'accès aux ressources AWS
Amazon VPC
- Nom : Virtual Private Cloud
- Catégorie : Réseau and Diffusion de contenu (Content Delivery)
- Description : Réseau privé virtuel logique de l'environnement AWS (équivalent LAN dans AWS)
- Propriétés principales :
- VPC ID: identifiant alphanumérique unique (par exemple
vpc-0123456789abcdef0)attribué à une instance d'un réseau privé virtuel - DNS Resolution : permet aux instances du VPC d'interroger le serveur DNS d'Amazon (Route 53 Resolver) afin de traduire les noms de domaine en adresses IP (y compris les domaines externes et internes)
- DNS Hostname : détermine si AWS attribue automatiquement ou pas des noms d'hôte DNS publics aux instances lancées avec des adresses IP publiques, permettant ainsi l'accès via un nom plus convivial tel que
ec2-xxx-xxx-xxx-xxx.compute-1.amazonaws.com - Subnet : liste des sous-réseaux avec les blocs CIDR associés et la région du VPC
- Main Network ACL : liste de règles sans état qui contrôlent le trafic « autorisé » et « refusé » d'un sous-réseau
- VPC ID: identifiant alphanumérique unique (par exemple
Amazon S3
- Nom : Amazon Simple Storage Service
- Catégorie : Stockage
- Description : Service de stockage d'objets (fichiers et métadonnées) dans des conteneurs (bucket) qui permettent une organisation logique (à l'instar d'un système de fichiers classique)
- Propriétés principales :
- ARN : identifiant alphanumérique unique (par exemple
arn:aws:s3:::bucket_name)permettant d'identifier le bucket - Creation Date : date et heure de création du compartiment
- Block Public Access : définit la politique d'accès externe
- Bucket Policy : politique définissant les autorisations sur les objets stockés dans le bucket
- Lifecycle rules : durée de conservation des objets
- Bucket versioning: permet d'avoir plusieurs variantes d'un objet dans le même bucket
- ACL: autorisations (lecture, écriture) accordées à d'autres comptes, y compris « Everyone » (compte anonyme) sur l'objet stocké
- Source Account : ID du compte du propriétaire du bucket
- ARN : identifiant alphanumérique unique (par exemple
Amazon SNS
- Nom : Amazon Simple Notification Service
- Categorie : Intégration d'applications
- Description : Service de messagerie permettant d'envoyer des notifications et des messages
- Propriétés principales :
- ARN : identifiant alphanumérique unique (par exemple
arn:aws:sns:region:094487668201:topic_name) permettant d'identifier le sujet (topic) - Topic (sujet) : canal de communication par lequel les émetteurs (services AWS lorsqu'un événement est déclenché) envoient des messages en vue de leur diffusion
- Subscription (abonnement) : action (envoi d'e-mail, exécution de Lambda, etc.) associée au sujet
- Owner: identifiant du créateur et du propriétaire du sujet
- ARN : identifiant alphanumérique unique (par exemple
Région AWS et Zone de disponibilités
AWS dispose de nombreux centres de données répartis dans le monde entier. Une région AWS correspond à une zone géographique distincte dans laquelle AWS déploie ses services et héberge des données. Son emplacement est choisi de manière à réduire au minimum la latence, à respecter les exigences réglementaires et à permettre aux utilisateurs de choisir où leurs ressources sont hébergées.
Les régions sont indépendantes les unes des autres et isolées par défaut : une ressource déployée dans une région n'est pas accessible depuis une autre région, sauf configuration explicite. De plus, il est important de noter que tous les services AWS ne sont pas disponibles dans toutes les régions.
Chaque région est subdivisée en zones de disponibilité (AZs). Une zone de disponibilité correspond à un centre de données physiquement isolé, mais interconnecté avec d'autres zones de la même région via un réseau à faible latence. Les ressources déployées au sein d'une même région, mais dans des zones de disponibilité différentes peuvent donc communiquer entre elles si la configuration réseau le permet.
En cas d'incident, il est nécessaire de vérifier et de confirmer toutes les régions actives qui sont normalement utilisées.
Artefacts Forensiques
Dans tous les environnements, les journaux d'activité constituent la principale source d'informations analysées en cas d'incident. Ces analyses s'appuient souvent sur deux services principaux : CloudTrail et GuardDuty.
CloudTrail est le système de journalisation par défaut des services AWS. Il enregistre en détail toutes les actions effectuées via la console ou de manière programmatique (via des appels API dans les deux cas), qu'elles soient initiées par des utilisateurs, des rôles ou des services. Il s'agit principalement d'événements de gestion (management events), qui sont activés par défaut et couvrent la création, la consultation, la modification et la suppression de ressources.
Par exemple, dans Amazon S3, il existe des actions telles que CreateBucket, ListBuckets, DeleteBucket et GetBucketAcl. Amazon fournit la liste complète de ces événements ainsi que leur description.
CloudTrail propose d'autres types d'événements qui ne sont pas activés par défaut et qui doivent être explicitement activés selon les besoins :
- Événements de données (Data events) : actions effectuées directement sur les ressources. Par exemple, dans le cas des compartiments S3, la récupération, le téléchargement ou la suppression d’un objet ne sont pas enregistrés par défaut.
- Événements Insights (Insights events) : anomalies détectées par CloudTrail Insights comme des pics inhabituels d’appels API ou un taux d’erreur élevé
- Événements d’activité réseau (Network activity events) : événements liés à l’activité réseau comme les actions entre VPC. Ils ne s’appliquent qu’à un nombre limité de services.
En pratique, les analyses s'appuient principalement sur les événements de gestion, tandis que les autres types d'évènements sont souvent désactivés.
Les journaux CloudTrail sont accessibles via la console AWS, sous l'onglet « Historique des événements ».
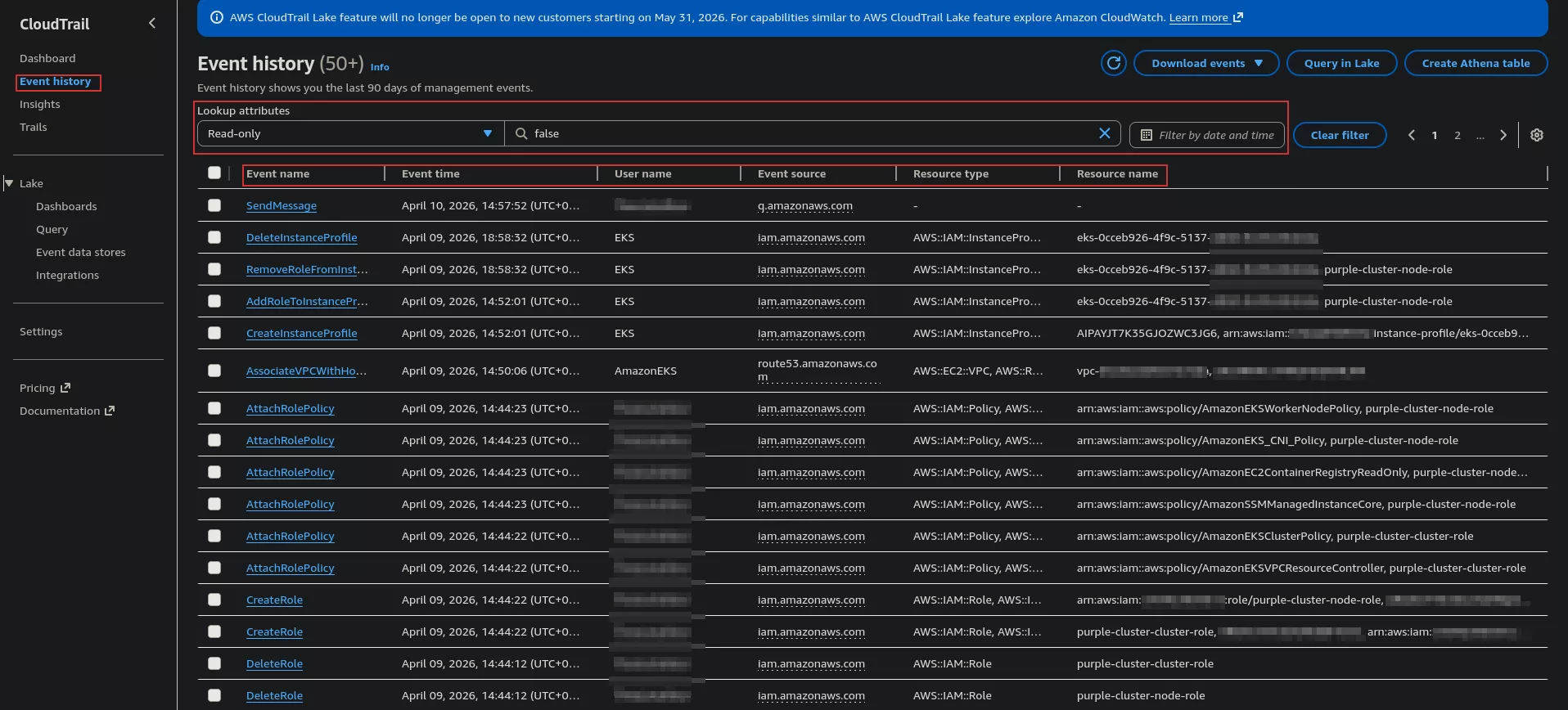
Par défaut, l'historique des événements est conservé sur les 90 derniers jours.
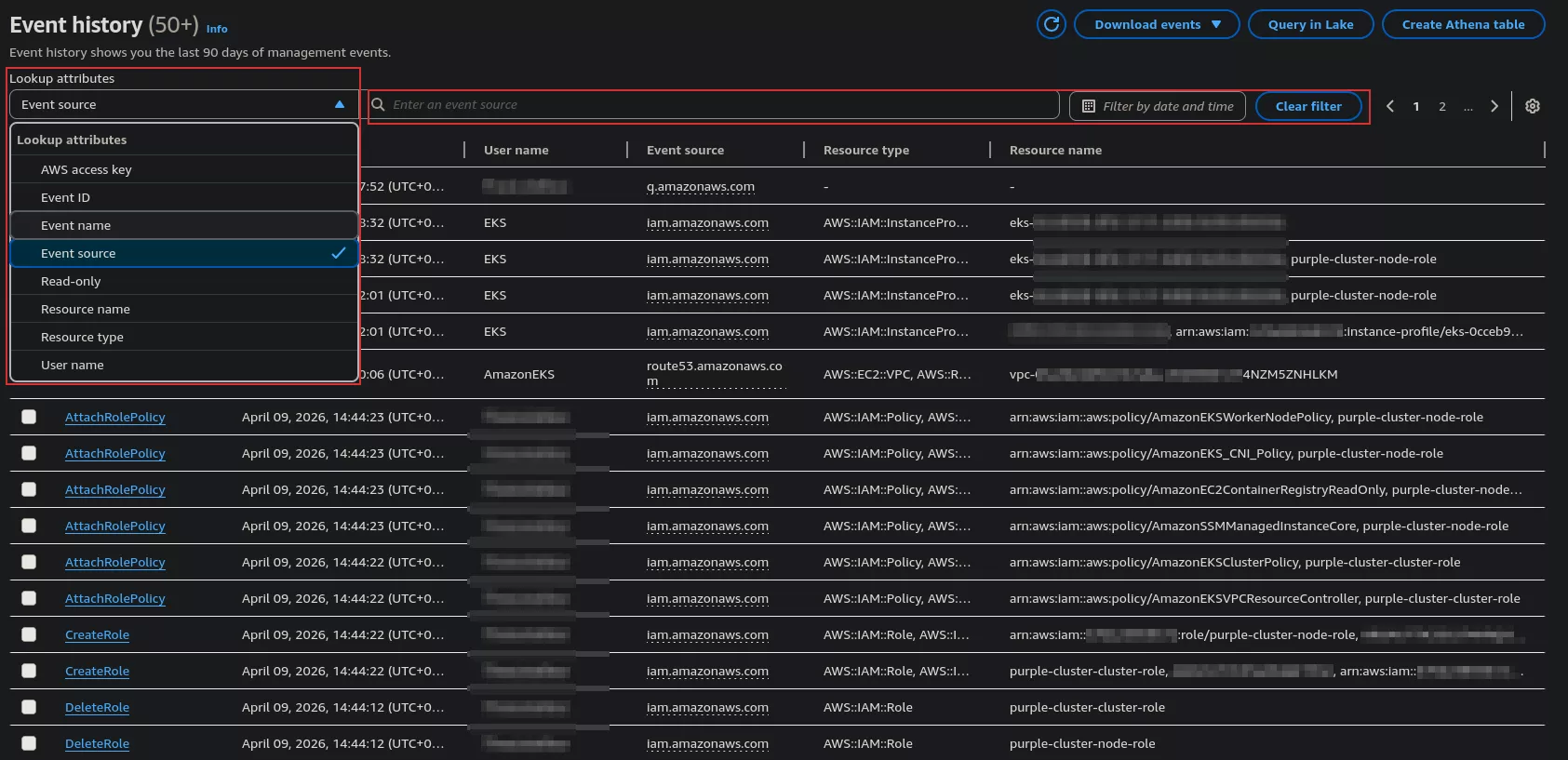
Ce filtre permet de consulter tous les événements CloudTrail et de les trier rapidement à l'aide du menu de filtrage, en fonction de critères tels que l'identité (utilisateur ou rôle), la source (service ou ressource concernée) ou le nom de l'événement lorsqu'une action spécifique est recherchée.
Il est possible de personnaliser les colonnes affichées, mais leur nombre est volontairement limité pour des raisons de cohérence et ne couvre pas toutes les informations disponibles pour chaque enregistrement.
Pour des recherches plus avancées, incluant des attributs spécifiques comme le user-agent, il est préférable d'utiliser les requêtes Data Lake. Il s'agit d'un magasin de données qui centralise les événements CloudTrail et permet de les interroger via des requêtes SQL.
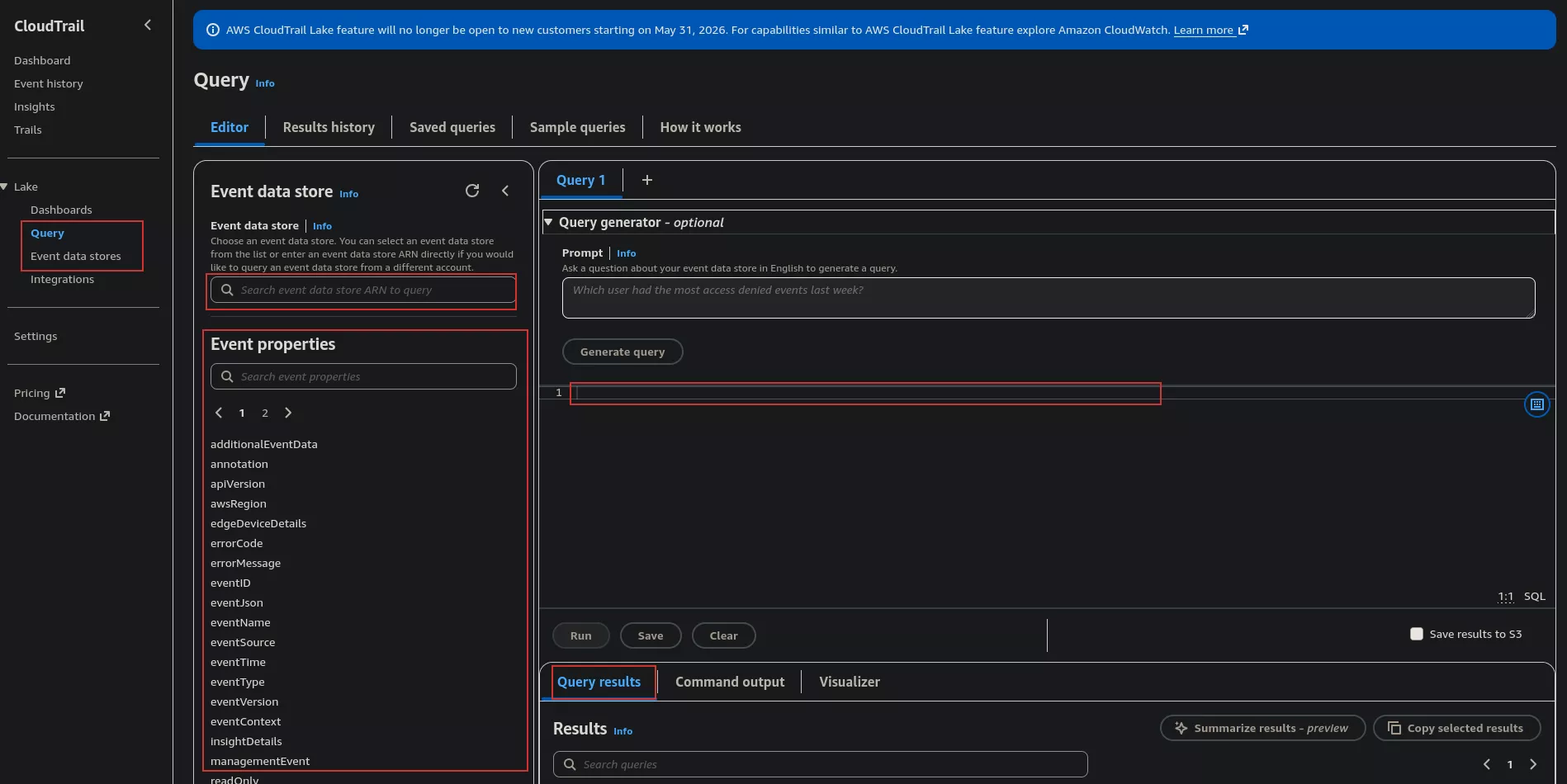
Ce datastore doit toutefois être configuré au préalable : création du datastore (avec un nom spécifique), définition de la durée de rétention (en fonction du coût souhaité), sélection des régions concernées et les types d'événements à suivre (événements de gestion, événements de données ou informations).
Il est important de noter que le magasin de données ne contiendra que les événements générés après sa création : s'il n'était pas activé avant l'incident, il ne contiendra pas d'événements antérieurs à cet incident.
Dans ce cas, il est possible d'utiliser Athena, un service AWS serverless qui permet d'exécuter des requêtes SQL directement sur les données stockées dans un bucket S3. C'est le cas des événements CloudTrail qui sont généralement stockés (au format JSON) dans un bucket S3.
En plus des journaux CloudTrail, il est possible de s'appuyer sur GuardDuty, un service de détection et de monitoring de l'environnement AWS (non activé par défaut, mais parfois déjà présent dans les environnements que nous rencontrons).
GuardDuty analyse automatiquement plusieurs sources de données, notamment les événements CloudTrail, l'activité de certains services (S3, EC2, RDS, EKS, ECS, Lambda) et les journaux spécifiques à certaines activités, en particulier l'activité réseau. Il s'appuie sur des flux de renseignements sur les menaces (listes d'adresses IP et de domaines malveillants, hachages de fichiers) et sur des modèles d'apprentissage automatique (ML) pour identifier les comportements suspects ou potentiellement malveillants. Les résultats peuvent être consultés dans l'onglet « Findings ».
La documentation officielle de GuardDuty répertorie les principales règles de détection proposées par le service. La consultation des détails de chaque alerte vous permet d'identifier les ressources affectées, ainsi que les actions spécifiques qui ont déclenché la détection.
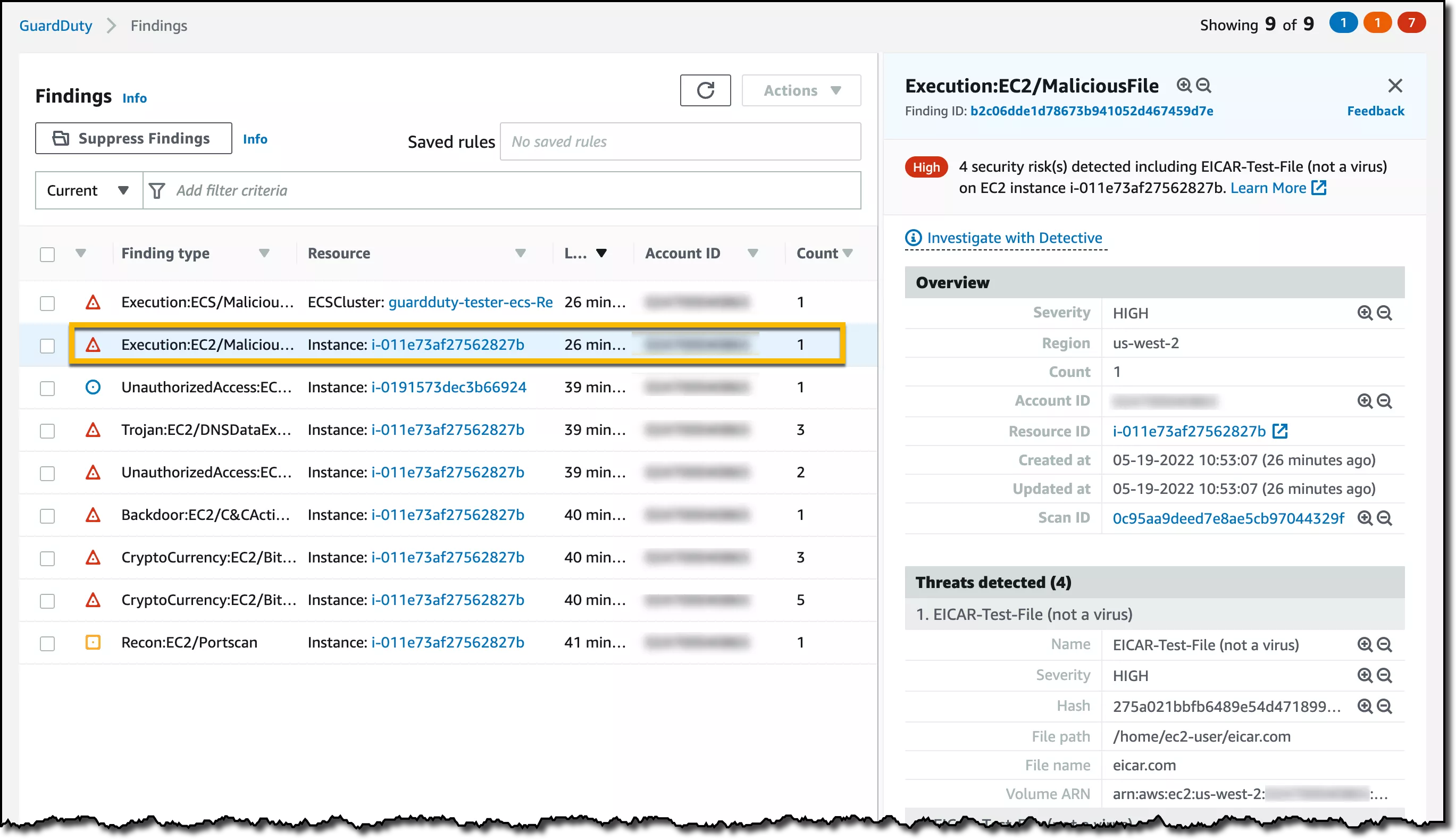
Avant toute utilisation, le service doit être configuré : sélection des protections (plans) à activer, de la durée de conservation des résultats (90 jours par défaut) et du bucket S3 pour le stockage. Contrairement à CloudTrail, GuardDuty ne conserve que les alertes relatives à une région spécifique et ne centralise pas nativement les résultats provenant de plusieurs régions. À l'instar de DataLake, la détection s'effectue uniquement sur les journaux générés après l'activation
AWS Threat : Mode opératoire
Comme expliqué précédemment, un environnement AWS fonctionne comme un système d'information classique, à la différence près que le matériel n'est pas géré directement par l'organisation.
Par conséquent, une intrusion sur AWS se déroule souvent de la même manière qu'une intrusion classique : phase de reconnaissance, élévation des privilèges, persistance, mouvement latéral et actions finales dictées par les objectifs de l'attaquant (souvent le vol de données, l'exploitation des ressources de calcul comme le minage de cryptomonnaies, ou encore les rançongiciels, comme c'est le cas avec le malware Codefinger).
Dans le contexte AWS, les principaux vecteurs d'attaque sont généralement liés à :
- une vulnérabilité dans un service exposé (par exemple, une application vulnérable s'exécutant sur EC2) ;
- l'utilisation d'identifiants obtenus en dehors de l'environnement (exfiltrés d'un poste de travail ou mal protégés dans des dépôts de code) ;
- ou à des services mal configurés (S3 accessible depuis Internet, EC2 exposant SSH/RDP sans restrictions d'adresse IP).
Le point de départ d'un incident réside souvent dans la détection d'un comportement inhabituel par les équipes d'exploitation et d'administration : pics inexpliqués de facturation, déploiements de services à grande échelle, exécutions inattendues de fonctions Lambda ou alertes déclenchées par GuardDuty. Ces indicateurs permettent d'identifier rapidement les services clés sur lesquels se concentrer lors des analyses.
La principale difficulté réside souvent dans l'identification des événements pertinents liés à une attaque, ainsi que dans leur interprétation. Dans ce contexte, nous nous concentrerons sur certaines techniques courantes, observées lors d’incidents, remontées par les équipes d’intrusion et de Red Team de Synacktiv, et largement documentées, en y associant les éléments de détection correspondants.
Événements classiques d'énumération
Cette phase regroupe les techniques utilisées par un attaquant pour collecter des informations pour identifier des utilisateurs, analyser leurs permissions et approfondir la reconnaissance de l’environnement. Elle repose souvent sur une succession d’appels de type Get / List / Describe après la récupération ou la compromission d'identifiants.
| Service | EventName | Description | Objectifs |
|---|---|---|---|
|
sts |
GetCallerIdentity |
Renvoie l'identité AWS actuelle, y compris l'ID du compte, l'ARN et l'entité principale utilisée |
Identifier le rôle ou l'utilisateur compromis |
| iam |
ListUsers |
Répertorie les utilisateurs IAM du compte |
Identifier les utilisateurs à cibler |
| iam |
ListRoles |
Répertorie les rôles IAM disponibles |
Identifier les rôles sensibles et susceptibles d'être exploités |
| iam |
ListAttachedUserPolicies |
Affiche les politiques associées à un utilisateur IAM |
Évaluer le niveau de privilèges et les possibilités d'escalade de privilèges |
| ec2 |
DescribeInstances |
Récupère des informations sur les instances EC2 |
Identifier des instances EC2 à cibler |
| s3 |
ListBuckets |
Affiche la liste des bucket du compte |
Identifier les référentiels de données susceptibles de contenir des informations sensibles |
| CloudTrail |
DescribeTrails |
Décrit la configuration de CloudTrail |
Identifier les zones les moins surveillées |
Exemples détaillés de techniques d'énumération et de découverte
Technique : Récupération de l'identifiant du compte à partir d'un bucket S3
En utilisant une identité disposant des autorisations s3:GetObject et s3:ListBucket, un attaquant peut effectuer plusieurs requêtes afin de tenter de découvrir l'identifiant du compte (Account ID). Cette technique repose notamment sur la condition s3:ResourceAccount, souvent utilisée dans les politiques limitant l'accès à certains comptes. Comme cette condition accepte le caractère générique *, il est possible de construire des requêtes permettant de déduire les différents chiffres composant l'identifiant du compte. Cette approche est documentée par Tracebit et implémentée dans l'outil s3-account-search.
Détection : Exécutions répétées de la commande s3:GetBucketAcl sur la même ressource ou sur plusieurs compartiments.
Technique : Récupération de l'identifiant du compte à partir d'une clé API
Lorsqu'un attaquant dispose d'une clé d'accès compromise, il peut récupérer l'ID de compte associé, même dans les cas où la clé a expiré. Pour ce faire, il peut utiliser la commande aws sts get-access-key-info --access-key-id, puis exploiter le résultat hors ligne.
Détection : Ce type de requête n'est généralement pas journalisé dans CloudTrail, ce qui limite considérablement la visibilité du côté d'AWS.
Technique : Énumération des rôles et des utilisateurs à partir d'un bucket S3 et d'un identifiant de compte
Lorsqu'une identité compromise est propriétaire d'un bucket, elle peut disposer des permissions nécessaires pour modifier sa politique. L'attaquant peut alors tester différentes entités (ou Principal) à partir d'une liste de mots afin d'identifier les rôles IAM et les utilisateurs existants dans le compte. C'est le principe sur lequel repose l'outil enumate_iam_using_bucket_policy de Nick Frichette.
Détection : Répétition des événements s3:PutBucketPolicy avec des variations successives des valeurs du « Principal ».
Technique : Énumération des permissions à partir d’une clé d’API
Lorsqu'un attaquant dispose d'une clé d'accès et du secret associé, même si ceux-ci ont expiré, il peut tester différentes commandes d'API afin d'identifier les autorisations effectivement disponibles. Des outils comme enumerate-iam automatisent cette vérification en exécutant une liste d'appels API et en analysant les réponses « Allow » (Autoriser) ou « Deny » (Refuser).
Détection : un volume élevé d'appels API sur plusieurs services ou ressources, indiquant un comportement anormal.
Technique : Récupération et exploitation des identifiants d'une instance EC2 compromise
Les instances EC2 exposent un service appelé Instance Metadata Service (IMDS), qui permet d'accéder à certaines informations locales concernant l'instance. Ces métadonnées comprennent notamment la configuration réseau, les rôles associés et d'autres informations sensibles..
L'accès s'effectue via des requêtes HTTP à l'adresse 169.254.169.254, par exemple http://169.254.169.254/latest/meta-data/.
Après avoir compromis une instance, un attaquant peut vérifier la présence d'un profil d'instance via http://169.254.169.254/latest/meta-data/iam/info, puis récupérer les identifiants temporaires associés à l'aide de http://169.254. 169.254/latest/meta-data/iam/security-credentials/MyRole ou http://169.254.169.254/latest/meta-data/identity-credentials/ec2/security-credentials/ec2-instance.
Détection : comme ces requêtes sont effectuées localement depuis l'instance, elles ne sont généralement pas enregistrées directement dans AWS.
Post-reconnaissance et persistance
Cette section décrit d’autres techniques couramment utilisées par les attaquants pour récupérer des secrets et établir de la persistance, généralement après les phases de reconnaissance et de découverte.
Technique : Récupération de mot de passe Windows
Une fois qu'un attaquant a compromis une instance EC2 et obtenu une identité valide, il peut tenter de récupérer le mot de passe administrateur du système. Si ce mot de passe est réutilisé sur d'autres instances, cela peut faciliter la propagation latérale et permettre au pirate d'obtenir des privilèges d'administrateur.
Détection : événements ec2:GetPasswordData et sts:AssumeRole, souvent accompagnés d'un code d'erreur indiquant que l'action n'est pas autorisée. L'analyse de l'identifiant du compte, de la clé API et du user-agent peut servir de point de départ ou de point pivot.
Technique : Récupération de secrets
Un attaquant disposant d'un compte valide et privilégié peut tenter d'extraire des secrets gérés dans AWS Secrets Manager pour poursuivre sa compromission. Ce service permet de stocker divers types de secrets, tels que des clés API, des identifiants d'application ou des jetons.
Détection : événement secretsmanager:ListSecrets pour répertorier les secrets disponibles, suivi de secretsmanager:GetSecretValue pour extraire leur contenu.
Technique : Récupération du script d’initialisation d’une instance EC2
Lorsqu'une instance EC2 est créée, elle peut exécuter un script de démarrage via les données utilisateur de l'instance (Instance User Data), généralement utilisées pour sa configuration initiale. Cette source d'informations peut présenter un intérêt pour un attaquant, car elle peut contenir des secrets codés en dur ou des paramètres sensibles.
Détection : événement ec2:DescribeInstanceAttribute, souvent suivi d'un sts:AssumeRole.
Technique : Modification du script d’initialisation d’une instance EC2
Après avoir récupéré les informations du script d'initialisation, un attaquant peut tenter de le modifier afin d'y injecter du code qui s'exécutera à chaque démarrage ou de mettre en place un mécanisme de persistance.
Détection : événements ec2:StopInstances, nécessaires pour arrêter l'instance avant toute modification, suivis de l'événement ec2:ModifyInstanceAttribute avec un paramètre requestParameters.userData non vide contenant les éléments à exécuter.
Technique: SES Enumeration
Once the AWS environment has been compromised, an attacker may seek to exploit the infrastructure for malicious purposes, such as phishing campaigns. The SES service can then be used to send emails.
Detection: Event ses:GetAccountSendingEnabled to check if the service is enabled, ses:GetSendQuota to determine the daily quota, ses:ListIdentities to identify identities capable of sending emails, and ses:GetIdentityVerificationAttributes to confirm that an email identity is active.
Technique : Exécution de commandes dans les instances EC2
Lorsqu'un attaquant obtient des privilèges suffisamment élevés, il peut tenter d'exécuter des commandes sur plusieurs instances EC2 afin de mener des opérations de reconnaissance. Cette approche s'appuie souvent sur AWS Systems Manager, un service d'administration présent sur de nombreuses instances.
Détection : événement ssm:StartSession pour lancer une session sur une ou plusieurs machines, et ssm:SendCommand pour exécuter une commande avec un paramètre requestParameters contenant la liste des instances ciblées. Pour des raisons de sécurité, la commande exécutée n'apparaît pas toujours dans les journaux AWS. Cependant, elle figure souvent dans les journaux système de l'instance EC2.
Technique : Porte dérobée dans un rôle IAM
Lorsqu'un attaquant a accès à plusieurs comptes au sein d'un environnement, il peut chercher à obtenir un accès persistant à un compte sensible. Plutôt que de créer une nouvelle identité ou un nouveau rôle, il peut modifier la politique de confiance d'un rôle existant afin de permettre son adoption depuis un autre compte moins sensible et moins surveillé.
Détection : événement iam:UpdateAssumeRolePolicy, avec une recherche du principal ou de l'identité ajoutée.
Technique : Porte dérobée dans une Lambda Function
Lorsqu'un attaquant a accès à une fonction Lambda, il peut l'utiliser pour y injecter du code qui sera exécuté à chaque invocation. Cela peut, par exemple, déclencher un reverse shell ou mettre en place un mécanisme de persistance.
Détection : événement lambda:UpdateFunctionCode20150331v2. Une vérification manuelle du code reste nécessaire, car les journaux ne précisent pas la nature exacte des modifications.
Toolbox : Journalisation, Audit et Analyse
Consolidation et amélioration de la journalisation
Bien que les journaux CloudTrail et l'activation par défaut de GuardDuty permettent de retracer la plupart des actions d'un attaquant, ces journaux sont souvent incomplets.
Par exemple, ils n'enregistrent pas les téléchargements massifs de données à partir d'un bucket S3 (signe d'une exfiltration de données) ni l'activité au sein d'une instance EC2. D'autres sources de journaux et des ajustements de configuration peuvent améliorer la couverture et la visibilité. Vous trouverez ci-dessous une liste de journaux et de configurations supplémentaires.
CloudTrail
Data events
Contrairement aux événements de gestion, qui enregistrent les actions de gestion sur les ressources (création, modification, suppression), les événements liés aux données (data events) enregistrent les actions effectuées directement sur les données elles-mêmes. Par exemple, pour un bucket S3, les événements de gestion documentent la création ou la suppression d'un bucket, mais l'accès aux objets (GetObject, PutObject) reste désactivé par défaut. Lors de l'exfiltration ou du chiffrement de données, ces actions deviennent invisibles sans activation explicite.
Insights Events
Détectent les anomalies dans le volume des appels API (pics de requêtes par minute ou d'erreurs). Particulièrement efficace pour identifier les attaques par force brute ou les attaques de reconnaissance.
Network Activity Events
Enregistrent les appels API transitant par des points de terminaison VPC (interfaces réseau permettant d'accéder aux services AWS sans passer par le réseau interne) depuis un VPC privé (sous-réseau interne sans accès à Internet) vers les services AWS (S3, KMS, Secrets Manager, etc.). Équivalent au trafic réseau interne d'un système d'information classique (i.e : on-premise), ces évènements permettent d'identifier les accès anormaux (par exemple, un compte suspect accédant à un bucket sensible via un point de terminaison privé) qui ne sont pas capturés dans les événements de gestion standard.
Rétention : 90 jours par défaut. Configuration recommandée : enregistrer les journaux dans un bucket S3 avec une période de conservation de 6 à 12 mois via la politique de cycle de vie.
GuarDuty
GuardDuty est un service de détection des menaces qui surveille et analyse en permanence l'environnement AWS.
Il analyse automatiquement plusieurs sources données, telles que :
- Journaux AWS CloudTrail (activité API) ;
- Journaux "VPC flow logs" (traffic réseaux) ;
- Requêtes DNS ;
- Activité des services S3, RDS, EKS, ECS et EC2.
Les principaux éléments à configurer dans GuardDuty sont les suivants :
- Les plans de protection (protections plans), qui correspondent aux fonctionnalités spécifiques et aux capacités de détection des menaces à activer ;
- La configuration de l'exportation et de la conservation des résultats, généralement via la mise en place d'un bucket S3 destiné à stocker les résultats.
Les plans de protection sont des ensembles de règles et de fonctionnalités conçus pour des cas d'utilisation spécifiques afin d'améliorer la détection des menaces dans divers services AWS (tels que S3, Lambda, EKS, RDS, etc.). Vous trouverez ci-dessous la liste des plans disponibles dans GuardDuty. Sauf indication contraire, ces plans sont désactivés par défaut :
- Protection S3 (S3 Protection) : surveille les bucket Amazon S3 en analysant les événements de données CloudTrail afin de détecter les accès suspects et les fuites de données
- Protection contre les logiciels malveillants pour S3 (Malware Protection for S3) : analyse automatiquement les objets S3 nouvellement uploadés à la recherche de logiciels malveillants
- Protection EKS (EKS Protection, activée par défaut pour les nouveaux comptes) : surveille les clusters Amazon EKS en analysant les journaux d'audit Kubernetes afin de détecter toute activité suspecte ou malveillante
- Surveillance en temps réel (Runtime Monitoring) : assure la surveillance en temps réel des processus, des accès aux fichiers et des connexions réseau sur les services Amazon EC2, ECS et EKS.
- Protection contre les logiciels malveillants pour EC2 (Malware Protection for EC2) : analyse les volumes EBS attachés aux instances EC2 à la recherche de logiciels malveillants.
- Protection RDS (RDS Protection) : surveille les activités d'accès et de connexion sur les bases de données Amazon RDS et Aurora afin de détecter tout comportement suspect.
- Protection Lambda (Lambda Protection) : surveille les journaux d'activité réseau AWS Lambda afin de détecter les comportements suspects ou malveillants, tels que le minage de cryptomonnaies.
- Détection étendue des menaces (Extended Threat Detection, activée par défaut) : nouveau plan qui détecte et met en corrélation automatiquement les attaques en plusieurs étapes sur l'ensemble des sources de données et des services AWS au fil du temps.
Journaux d'accès S3 (S3 Access Logs)
Les journaux d'accès S3 enregistrent toutes les requêtes HTTP adressées à un bucket, en mettant l'accent sur le volume de données échangées (octets transférés, requêtes répétées), ce qui s'avère utile en cas de suspicion de fuite de données.
Lambda Logs
En complément des événements de données, qui indiquent qui a invoqué une fonction Lambda, les journaux Lambda (CloudWatch Logs) capturent les détails d'exécution (stdout/stderr, erreurs, durée). Activés par défaut avec un rôle IAM approprié (logs:*), ils nécessitent une configuration de "groupe de journaux" et une politique de conservation (1 jour à 10 ans).
CloudWatch Logs
Un service de surveillance qui collecte des métriques, des événements, des alarmes et des journaux. Le composant CloudWatch Logs peut être déployé sur des instances EC2 pour collecter et centraliser les journaux système et d'application, selon la configuration souhaitée, dans des groupes de journaux et en faciliter l'exploitation.
VPC Flow Logs
Journaux réseau qui capturent le trafic IP entrant et sortant des interfaces réseau (ENIs), couvrant à la fois le trafic interne et externe. À l'instar de journaux de type NetFlow, ils enregistrent les informations suivantes : adresses IP source/destination, ports et actions (ACCEPT/REJECT). Journaux complémentaire aux événements d'activité réseau, qui se concentrent sur les appels d'API et les identités responsables de l'événement.
AWS Config
Un service qui surveille et enregistre en continu les modifications apportées aux configurations des ressources. Conçu pour l'audit des services et la conformité, il offre les fonctionnalités suivantes :
- Inventaire : liste exhaustive des ressources et des métadonnées ;
- Historique : permet d'identifier quelle entité (au sens identité) a modifié quelle configuration et à quel moment ;
- Conformité : utilisation de règles managées ou personnalisées pour évaluer les services.
Choix des journaux
La liste présentée n'est pas exhaustive, mais couvre les cas d'utilisation les plus courants, en particulier CloudWatch Logs, qui mérite une attention particulière. Ces journaux, lorsqu'ils sont activés rétroactivement lors d'un incident, ne capturent pas les événements survenus avant leur mise en place. Ils peuvent néanmoins servir de recommandations pour combler des lacunes identifiées lors des analyses ou pour aider les équipes internes à renforcer la visibilité sur les données et les services.
L'activation de journaux supplémentaires doit tenir compte des critères suivants :
- Ciblage précis : éviter de journaliser les services inutilisés (par exemple, EKS non déployé) ;
- Donner la priorité aux actifs critiques et sensibles (par exemple, les bucket S3 contenant des données sensibles ou les instances EC2 exposées) ;
- Évaluation des coûts : analyser l'impact financier en amont.
Audit et Hunting
Au cours d'une analyse de journaux, il est fréquent de questionner la configuration et le niveau de sécurité d'une ressource ou d'une identité. Par exemple : l'authentification à deux facteurs est-elle activée ? Un bucket S3 est-il accessible à n'importe qui depuis Internet ?). AWS propose divers outils, initialement conçus pour l'audit, mais qui s'avèrent également utiles pour la recherche de menaces.
IAM Access Analyzer
Permet une analyse approfondie et exhaustive des politiques IAM pour identifier les accès potentiellement excessifs en fonction des profils suivants :
- Accès externe : ressources accessibles depuis l'extérieur du compte (Internet, autres comptes) ;
- Accès interne : identification des accès privilégiés ;
- Accès inutilisés : identification des identités, clés et secrets inactifs.
Il intègre également un générateur de politiques qui vous permet de valider et de tester (syntaxe et conformité) les politiques avant leur déploiement.
Les analyses génèrent des résultats (findings) accompagnés des risques associés. Par exemple, cette politique S3 :
{
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::secrets-bucket/*"
}
Cela générera une alerte indiquant que la ressource « secrets-bucket » est accessible depuis Internet, avec les informations suivantes :
- Ressource : secrets-bucket
- Accès externe : Entité :* (Internet)
- Risque : lecture publique des secrets
- Action : Archiver / Supprimer / Ignorer
AWS Inspector
Service de gestion des vulnérabilités qui analyse automatiquement les charges de travail (EC2, Lambda, ECS, référentiels de code) afin de détecter les CVE, les secrets codés en dur et les expositions réseau. Il permet une configuration très fine pour cibler uniquement des ressources spécifiques.
AWS Security Hub and CSPM
Agrégateur et corrélateur de données de sécurité. Il centralise, normalise, corrèle et analyse plusieurs sources de données (CloudTrail, GuardDuty, Inspector, Config, etc.). Il fournit un score de criticité et des informations classées par ordre de priorité (par exemple, les 3 risques majeurs). Exemple de corrélation multisource sur une instance EC2 :
- Rapport de vulnérabilité provenant d'Inspector ;
- Détection d'un accès SSH depuis une adresse IP étrangère dans GuardDuty ;
- Identification du groupe de sécurité public 0.0.0.0/0 (EC2 accessible depuis n'importe quelle adresse IP sur n'importe quel port) à partir d'AWS Config.
La combinaison de ces trois constatations (findings) génère une alerte de haute priorité concernant l'instance EC2.
Outre son moteur de corrélation, il s'appuie également sur des règles de conformité basées sur des normes telles que CIS, PCI-DSS ou NIST.
D'autres outils comme Audit Manager, Macie et Trusted Advisor peuvent compléter l'analyse du service pour des besoins plus spécifiques, même si les outils précédemment mentionnés couvrent déjà un large spectre de besoin.
Autres outils
AWS CLI
Interface de ligne de commande officielle d'AWS permettant d'interagir avec tous les services AWS. Elle est particulièrement utile pour obtenir des informations détaillées et spécifiques sur une identité IAM ou un service donné.
Par exemple, en cas de suspicion de compromission d'une identité, il est possible de déterminer si une clé d'accès existait déjà ou a été créée par un attaquant à l'aide de la commande suivante : aws iam list-access-keys --user-name user_name.
Cette requête liste les clés d'accès associées à l'utilisateur, ainsi que leur statut (actif/inactif) et leur date de création exacte.
Qu'il s'agisse d'un audit ou une investigation, la maîtrise de l'AWS CLI constitue un avantage considérable dans votre boîte à outils.
Par ailleurs, elle peut également être utilisée pour copier des journaux stockés dans un bucket S3 et les exporter vers des outils tiers, évitant ainsi de dépendre d'outils comme Athena, qui peuvent s'avérer moins flexibles et plus coûteux.
Outils tiers complémentaires
Au-delà des services natifs d'AWS, plusieurs outils open source offrent une vue d'ensemble de l'environnement et fournissent des informations pertinentes pour l'analyse de la sécurité.
- Invictus-AWS : Cet outil énumère les services actifs dans le compte, collecte leurs configurations détaillées et extrait automatiquement les journaux pertinents liés à ces services identifiés.
- CloudMapper : Bien que déprécié, il reste intéressant pour analyser l'ensemble de l'environnement AWS. Il génère un diagramme réseau des ressources déployées et produit des tableaux de bords sur le niveau de sécurité des identités et services.
- IAMHoundDog : Inspiré de BloodHound, il génère un graphe des relations entre les identités IAM, les politiques et les ressources sélectionnées. Cela permet de visualiser et d'identifier les chemins potentiels de compromission ou d'escalade de privilèges.
- Cloud Scout : Similaire à IAMHoundDog, il cartographie les environnements cloud (y compris AWS) pour détecter les vulnérabilités et les expositions fortes.
- ScoutSuite: Outil d'audit multi-cloud aux fonctionnalités proches de Security Hub. Il analyse les configurations et identifie les éléments à risques en produisant des rapports structurés et exploitables.
Ces outils open source complètent idéalement les capacités natives d'AWS, couvrant un large éventail de besoins en matière de reconnaissance (ou connaissance de l'environnement à analyser) et d'analyse.
Conclusion
Cet article se veut une introduction destinée aux personnes ayant peu d'expérience avec AWS ou souhaitant élargir leurs connaissances sur les aspects défenses / analyses. Les sujets abordés ne se veulent pas exhaustifs, mais ont été sélectionnés pour illustrer des concepts fondamentaux et essentiels.
Parmi les points clés mis en avant et méritant d'être retenus, on peut citer :
- Le concept des comptes et des identités AWS, qui peut prêter à confusion pour les débutants ;
- La gestion des autorisations, dont la complexité apparente nécessite une explication claire ;
- Le fonctionnement des services AWS, en mettant en évidence leurs points communs et leurs spécificités, afin de comprendre et d'identifier les éléments d'intérêt dans un service donné ;
- Les techniques d'attaque couramment utilisées par les attaquant, ainsi que les traces qu'ils laissent dans l'environnement ;
- Les différents types de journaux disponibles ;
- Les outils qui facilitent l'analyse et renforcent la sécurité globale.
Approfondissement
Pour ceux qui souhaitent approfondir le sujet, voici quelques recommandations de ressources de qualité :
- Le blog de l'équipe de sécurité de Datadog, riche en articles techniques sur AWS et ses services.
- Hacking Cloud, un blog consacré aux techniques d'intrusions dans les environnements cloud.
- Le blog de Nick Frichette, une référence incontournable pour la sécurité offensive sur AWS.
- L'outil Stratus-red-team, qui fournit de nombreux exemples de techniques d'attaque et des méthodes de détection associées.
- CloudGoat par Rhino Security Labs, un environnement de simulation pour reproduire et de tester diverses attaques AWS.
- Un retourd d'expérience d'un incident traité par notre équipe et présenté à Coriin.