Exploring GrapheneOS secure allocator: Hardened Malloc
GrapheneOS est un système d'exploitation mobile dérivé d'Android qui met l'accent sur la sécurité et la protection de la vie privée. Afin de renforcer davantage la sécurité de leur produit, les développeurs de GrapheneOS ont introduit un nouvel allocateur pour la libc : hardened malloc. Cet allocateur bénéficie d'une conception axée sur la sécurité visant à protéger les processus contre les vulnérabilités de corruption mémoire courantes. Cet article détaillera son architecture interne et la manière dont les mécanismes de protection sont implémentés, du point de vue d'un chercheur en sécurité.
Vous souhaitez améliorer vos compétences ? Découvrez nos sessions de formation ! En savoir plus
Introduction
GrapheneOS est un système d'exploitation mobile axé sur la sécurité et la confidentialité, basé sur une version modifiée d'Android (AOSP). Pour renforcer sa protection, il intègre des fonctionnalités de sécurité avancées, dont son propre allocateur mémoire pour la libc : hardened malloc. Conçu pour être aussi robuste que le système d'exploitation lui-même, cet allocateur cherche particulièrement à se protéger contre les corruptions mémoire.
Cet article technique détaille le fonctionnement interne de hardened malloc et les mécanismes de protection qu'il met en œuvre pour contrer les vulnérabilités classiques. Il s'adresse à un public technique, notamment les chercheurs en sécurité ou les développeurs d'exploits, souhaitant comprendre en profondeur les rouages de cet allocateur.
Les analyses et les tests de cet article ont été effectués sur 2 appareils exécutant GrapheneOS :
- Pixel 4a 5G :
google/bramble/bramble:14/UP1A.231105.001.B2/2025021000:user/release-keys - Pixel 9a :
google/tegu/tegu:16/BP2A.250705.008/2025071900:user/release-keys
Les appareils ont été rootés avec Magisk 29 dans le but d'utiliser Frida pour observer l'état interne de hardened malloc au sein des processus du système. L'étude s'est basée sur le code source du dépôt GitHub officiel de GrapheneOS (commit 7481c8857faf5c6ed8666548d9e92837693de91b).
GrapheneOS
GrapheneOS est un système d'exploitation durci basé sur Android. Projet opensource activement maintenu, il bénéficie de mises à jour fréquentes et d'une application rapide des correctifs de sécurité. Toutes les informations sont accessibles sur le site web de GrapheneOS.
Afin de protéger efficacement les processus qui s'exécutent sur l'appareil, GrapheneOS implémente plusieurs mécanismes de sécurité. Les sections suivantes décrivent succinctement les mécanismes spécifiques qui contribuent au durcissement de son allocateur mémoire.
Extended Address Space
Sur les systèmes Android classiques, l'espace d'adressage des processus userland est limité à 39 bits, ce qui correspond à une fenêtre d'adresses entre 0 et 0x800000000. Sur GrapheneOS, cet espace est étendu à 48 bits et pour profiter de cette extension, l'entropie de ASLR a lui aussi était augmenté, passant de 24 à 33 bits. Ce détail est important puisque hardened malloc repose en grande partie sur mmap pour ses structures internes et ses allocations.
tegu:/ # cat /proc/self/maps
c727739a2000-c727739a9000 rw-p 00000000 00:00 0 [anon:.bss]
c727739a9000-c727739ad000 r--p 00000000 00:00 0 [anon:.bss]
c727739ad000-c727739b1000 rw-p 00000000 00:00 0 [anon:.bss]
c727739b1000-c727739b5000 r--p 00000000 00:00 0 [anon:.bss]
c727739b5000-c727739c1000 rw-p 00000000 00:00 0 [anon:.bss]
e5af7fa30000-e5af7fa52000 rw-p 00000000 00:00 0 [stack]
tegu:/ # cat /proc/self/maps
d112736be000-d112736c5000 rw-p 00000000 00:00 0 [anon:.bss]
d112736c5000-d112736c9000 r--p 00000000 00:00 0 [anon:.bss]
d112736c9000-d112736cd000 rw-p 00000000 00:00 0 [anon:.bss]
d112736cd000-d112736d1000 r--p 00000000 00:00 0 [anon:.bss]
d112736d1000-d112736dd000 rw-p 00000000 00:00 0 [anon:.bss]
ea0de59be000-ea0de59e1000 rw-p 00000000 00:00 0 [stack]
tegu:/ # cat /proc/self/maps
d71f87043000-d71f8704a000 rw-p 00000000 00:00 0 [anon:.bss]
d71f8704a000-d71f8704e000 r--p 00000000 00:00 0 [anon:.bss]
d71f8704e000-d71f87052000 rw-p 00000000 00:00 0 [anon:.bss]
d71f87052000-d71f87056000 r--p 00000000 00:00 0 [anon:.bss]
d71f87056000-d71f87062000 rw-p 00000000 00:00 0 [anon:.bss]
f69f7c952000-f69f7c974000 rw-p 00000000 00:00 0 [stack]
Secure app spawning
Sur Android, chaque application est lancée via un fork du processus zygote. Ce mécanisme, conçu pour accélérer le démarrage, a une conséquence majeure sur la sécurité : toutes les applications héritent du même espace d'adressage que zygote. En pratique, cela signifie que les bibliothèques pré-chargées se retrouvent à des adresses identiques d'une application à l'autre. Pour un attaquant, cette prévisibilité permet de contourner facilement la protection ASLR sans avoir besoin d'une fuite d'information préalable.
Pour contrer cette faiblesse, GrapheneOS modifie fondamentalement ce processus. Au lieu d'un fork, les nouvelles applications sont lancées via exec. Cette méthode crée un espace d'adressage entièrement nouveau et aléatoire pour chaque processus, restaurant ainsi toute l'efficacité de l'ASLR. Il n'est plus possible de prédire l'emplacement de zones mémoires distantes. Cette sécurité renforcée a cependant un coût : un léger impact sur les performances au lancement et une augmentation de l'empreinte mémoire pour chaque application.
tegu:/ # cat /proc/$(pidof zygote64)/maps | grep libc\.so
d6160aac0000-d6160ab19000 r--p 00000000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d6160ab1c000-d6160abbe000 r-xp 0005c000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d6160abc0000-d6160abc5000 r--p 00100000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d6160abc8000-d6160abc9000 rw-p 00108000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
tegu:/ # cat /proc/$(pidof com.android.messaging)/maps | grep libc\.so
d5e4a9c68000-d5e4a9cc1000 r--p 00000000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d5e4a9cc4000-d5e4a9d66000 r-xp 0005c000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d5e4a9d68000-d5e4a9d6d000 r--p 00100000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d5e4a9d70000-d5e4a9d71000 rw-p 00108000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
tegu:/ # cat /proc/$(pidof com.topjohnwu.magisk)/maps | grep libc\.so
dabc42ac5000-dabc42b1e000 r--p 00000000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
dabc42b21000-dabc42bc3000 r-xp 0005c000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
dabc42bc5000-dabc42bca000 r--p 00100000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
dabc42bcd000-dabc42bce000 rw-p 00108000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
Memory Tagging Extension (MTE)
Memory Tagging Extension, ou MTE, est une extension de l'architecture Arm introduite avec Armv8.5. MTE qui a pour but d'empêcher les vulnérabilités de type corruption de mémoire d'être exploitées par un attaquant. Cette protection repose sur un mécanisme d'étiquetage de zones mémoire, appelé tag. Lors d'une allocation, un tag de 4 bits est associé à cette zone allouée et stocké dans les bits de poids fort du pointeur. Pour accéder aux données, il est nécessaire de connaitre l'adresse et le tag. Si le tag est mauvais, une exception est levée. Ce mécanisme permet de détecter et de bloquer les vulnérabilités de type out-of-bound read/write ou encore les use-after-free.
Par exemple, l'oob write du code C suivant pourrait être détecté en fonction de l'implémentation de l'allocateur avec MTE :
char* ptr = malloc(8);
ptr[16] = 12; // écriture en oob, le tag n'est plus valide pour cette zone
MTE étant une fonctionnalité offerte par le CPU, il est nécessaire que le matériel soit compatible. C'est le cas notamment de tous les smartphones Google Pixel depuis les Pixel 8. Pour plus d'informations, se référer à la documentation ARM.
Hardened malloc utilise donc MTE sur les smartphones compatibles, dans le but d'empêcher ce type de corruption mémoire.
Afin qu'un binaire soit compatible avec MTE, il doit être compilé avec certains flags. Pour les besoins de cet article, les flags ci-dessous ont été ajoutés au fichier Application.mk de nos binaires de tests pour prendre en compte MTE.
APP_CFLAGS := -fsanitize=memtag -fno-omit-frame-pointer -march=armv8-a+memtag
APP_LDFLAGS := -fsanitize=memtag -march=armv8-a+memtag
La documentation d'Android fournit toutes les informations nécessaires à la création d'une application compatible avec MTE.
Hardened malloc se repose fortement sur MTE en ajoutant des tags à ses allocations, mais uniquement dans le cas de small allocations. Les large allocations, supérieures à 0x20000 octets, ne possèdent pas de tags.
Architecture de hardened malloc
Hardened malloc dissocie les métadonnés des données, elles sont séparées dans des zones différentes en mémoire. Il existe 2 principales structures dans lesquelles se retrouvent les métadonnées :
ro: structure principale dans la section.bssde la libc ;allocator_state: grande structure regroupant toutes les métadonnées des différents types d'allocation, sa zone est réservée une seule fois à l'initialisation.
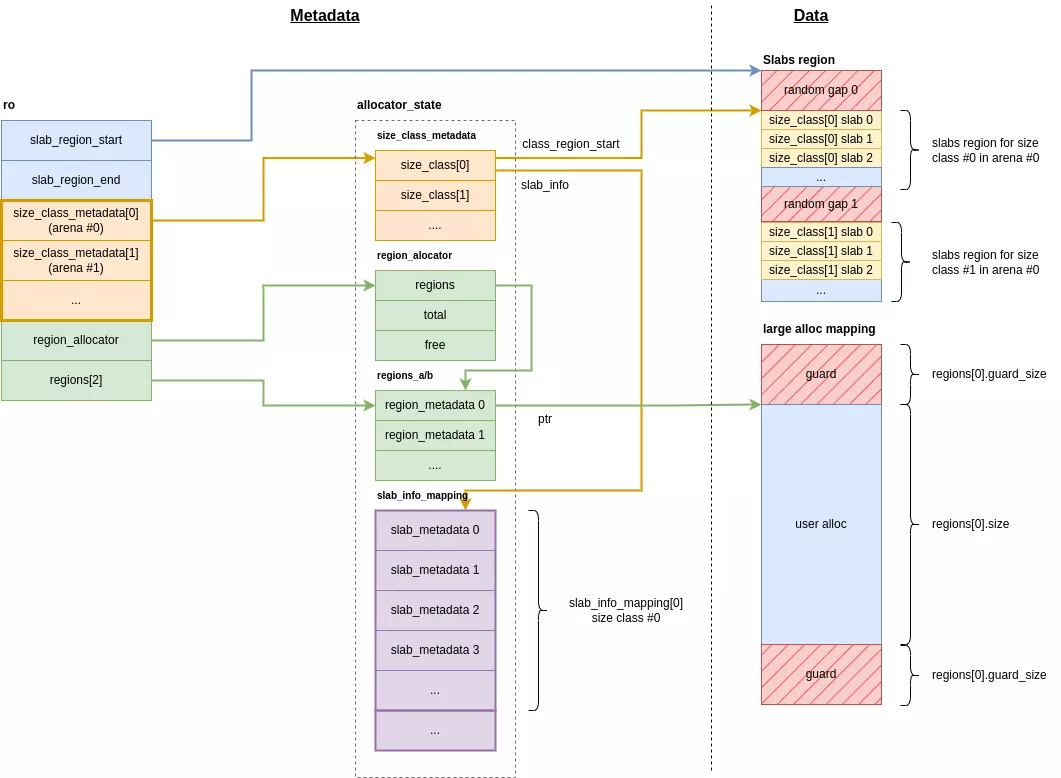
De la même manière que jemalloc, hardened malloc répartit les threads par arena. Chaque arena gère ses propres allocations. Cela implique qu'une allocation effectuée dans une arena ne pourra jamais être récupérée dans une autre. Cependant, aucune structure de données n'existe pour décrire les arenas, elles sont présentes implicitement et vont influer sur la taille de certains tableaux.
Bien que le concept d'arena soit présent dans le code source, en pratique l'analyse des binaires des libc des appareils de test a montré que hardened malloc n'était compilé qu'avec une seule arena. Tous les threads partagent donc les mêmes métadonnées d'allocation.
Structure ro
La structure ro est la principale structure de métadonnées de l'allocateur. Elle est contenue dans la section .bss de la libc. Elle se compose de différents attributs :
static union {
struct {
void *slab_region_start;
void *_Atomic slab_region_end;
struct size_class *size_class_metadata[N_ARENA];
struct region_allocator *region_allocator;
struct region_metadata *regions[2];
#ifdef USE_PKEY
int metadata_pkey;
#endif
#ifdef MEMTAG
bool is_memtag_disabled;
#endif
};
char padding[PAGE_SIZE];
} ro __attribute__((aligned(PAGE_SIZE)));
slab_region_start: début de la zone contenant les regions pour les petites allocationsslab_region_end: fin de la zone contenant les regions pour les petites allocationssize_class_metdata[N_ARENA]: tableau de pointeurs vers les métadonnées de petites allocations pour chaque arenaregion_allocator: pointeur vers la structure de gestion des large allocationsregions[2]: pointeur vers les tables de hashes référençant les large allocations
allocator_state
Cette structure contient toutes les métadonnées utilisées aussi bien pour les small allocations que les large allocations. Elle est mappée une seule fois à l'initialisation de l'allocateur et isolée par des pages de garde. Sa taille est fixe et calculée en fonction du nombre maximal d'allocations que l'allocateur est conçu pour gérer.
struct __attribute__((aligned(PAGE_SIZE))) allocator_state {
struct size_class size_class_metadata[N_ARENA][N_SIZE_CLASSES];
struct region_allocator region_allocator;
// padding until next page boundary for mprotect
struct region_metadata regions_a[MAX_REGION_TABLE_SIZE] __attribute__((aligned(PAGE_SIZE)));
// padding until next page boundary for mprotect
struct region_metadata regions_b[MAX_REGION_TABLE_SIZE] __attribute__((aligned(PAGE_SIZE)));
// padding until next page boundary for mprotect
struct slab_info_mapping slab_info_mapping[N_ARENA][N_SIZE_CLASSES];
// padding until next page boundary for mprotect
};
size_class_metadata[N_ARENA][N_SIZE_CLASSES]: tableau de structuressize_classcontenant les métadonnées des small allocations pour chaque classeregion_allocator: métadonnées des regions des large allocationsregions_a/b[MAX_REGION_TABLE_SIZE]: table de hashes regroupant les informations sur les mappings des large allocationsslab_info_mapping: métadonnées des slabs des small allocations
Données
Les données, quant à elles, sont réparties dans 2 types de regions distinctes des métadonnées :
- slabs region : très grande zone réservée une seule fois à l'initialisation, contenant les slabs pour les small allocations. Elle est initialisée dans
init_slow_pathet stockée dansro.slab_region_start. - large regions : zones réservées dynamiquement contenant les données de large allocations, chaque zone ne contient qu'une seule large allocation
Allocations
Il existe deux types d'allocation dans hardened malloc : small allocations et large allocations.
Small allocations
Size classes/bins
Les petites allocations sont regroupées par taille, appelée size class ou encore bin. Ces classes sont indexées par ordre croissant de taille et représentées par la structure size_class. Hardened malloc différencie 49 classes pour les small allocations :
| Size Class | Total Bin Size | Available Size | Slots | Slab size | Max slabs | Quarantines Size (random / FIFO) |
|---|---|---|---|---|---|---|
| 0 | 0x10 | 0x10 | 256 | 0x1000 | 8388608 | 8192 / 8192 |
| 1 | 0x10 | 0x8 | 256 | 0x1000 | 8388608 | 8192 / 8192 |
| 2 | 0x20 | 0x18 | 128 | 0x1000 | 8388608 | 4096 / 4096 |
| 3 | 0x30 | 0x28 | 85 | 0x1000 | 8388608 | 4096 / 4096 |
| 4 | 0x40 | 0x38 | 64 | 0x1000 | 8388608 | 2048 / 2048 |
| 5 | 0x50 | 0x48 | 51 | 0x1000 | 8388608 | 2048 / 2048 |
| 6 | 0x60 | 0x58 | 42 | 0x1000 | 8388608 | 2048 / 2048 |
| 7 | 0x70 | 0x68 | 36 | 0x1000 | 8388608 | 2048 / 2048 |
| 8 | 0x80 | 0x78 | 64 | 0x2000 | 4194304 | 1024 / 1024 |
| 9 | 0xa0 | 0x98 | 51 | 0x2000 | 4194304 | 1024 / 1024 |
| 10 | 0xc0 | 0xb8 | 64 | 0x3000 | 2796202 | 1024 / 1024 |
| 11 | 0xe0 | 0xd8 | 54 | 0x3000 | 2796202 | 1024 / 1024 |
| 12 | 0x100 | 0xf8 | 64 | 0x4000 | 2097152 | 512 / 512 |
| 13 | 0x140 | 0x138 | 64 | 0x5000 | 1677721 | 512 / 512 |
| 14 | 0x180 | 0x178 | 64 | 0x6000 | 1398101 | 512 / 512 |
| 15 | 0x1c0 | 0x1b8 | 64 | 0x7000 | 1198372 | 512 / 512 |
| 16 | 0x200 | 0x1f8 | 64 | 0x8000 | 1048576 | 256 / 256 |
| 17 | 0x280 | 0x278 | 64 | 0xa000 | 838860 | 256 / 256 |
| 18 | 0x300 | 0x2f8 | 64 | 0xc000 | 699050 | 256 / 256 |
| 19 | 0x380 | 0x378 | 64 | 0xe000 | 599186 | 256 / 256 |
| 20 | 0x400 | 0x3f8 | 64 | 0x10000 | 524288 | 128 / 128 |
| 21 | 0x500 | 0x4f8 | 16 | 0x5000 | 1677721 | 128 / 128 |
| 22 | 0x600 | 0x5f8 | 16 | 0x6000 | 1398101 | 128 / 128 |
| 23 | 0x700 | 0x6f8 | 16 | 0x7000 | 1198372 | 128 / 128 |
| 24 | 0x800 | 0x7f8 | 16 | 0x8000 | 1048576 | 64 / 64 |
| 25 | 0xa00 | 0x9f8 | 8 | 0x5000 | 1677721 | 64 / 64 |
| 26 | 0xc00 | 0xbf8 | 8 | 0x6000 | 1398101 | 64 / 64 |
| 27 | 0xe00 | 0xdf8 | 8 | 0x7000 | 1198372 | 64 / 64 |
| 28 | 0x1000 | 0xff8 | 8 | 0x8000 | 1048576 | 32 / 32 |
| 29 | 0x1400 | 0x13f8 | 8 | 0xa000 | 838860 | 32 / 32 |
| 30 | 0x1800 | 0x17f8 | 8 | 0xc000 | 699050 | 32 / 32 |
| 31 | 0x1c00 | 0x1bf8 | 8 | 0xe000 | 599186 | 32 / 32 |
| 32 | 0x2000 | 0x1ff8 | 8 | 0x10000 | 524288 | 16 / 16 |
| 33 | 0x2800 | 0x27f8 | 6 | 0xf000 | 559240 | 16 / 16 |
| 34 | 0x3000 | 0x2ff8 | 5 | 0xf000 | 559240 | 16 / 16 |
| 35 | 0x3800 | 0x37f8 | 4 | 0xe000 | 599186 | 16 / 16 |
| 36 | 0x4000 | 0x3ff8 | 4 | 0x10000 | 524288 | 8 / 8 |
| 37 | 0x5000 | 0x4ff8 | 1 | 0x5000 | 1677721 | 8 / 8 |
| 38 | 0x6000 | 0x5ff8 | 1 | 0x6000 | 1398101 | 8 / 8 |
| 39 | 0x7000 | 0x6ff8 | 1 | 0x7000 | 1198372 | 8 / 8 |
| 40 | 0x8000 | 0x7ff8 | 1 | 0x8000 | 1048576 | 4 / 4 |
| 41 | 0xa000 | 0x9ff8 | 1 | 0xa000 | 838860 | 4 / 4 |
| 42 | 0xc000 | 0xbff8 | 1 | 0xc000 | 699050 | 4 / 4 |
| 43 | 0xe000 | 0xdff8 | 1 | 0xe000 | 599186 | 4 / 4 |
| 44 | 0x10000 | 0xfff8 | 1 | 0x10000 | 524288 | 2 / 2 |
| 45 | 0x14000 | 0x13ff8 | 1 | 0x14000 | 419430 | 2 / 2 |
| 46 | 0x18000 | 0x17ff8 | 1 | 0x18000 | 349525 | 2 / 2 |
| 47 | 0x1c000 | 0x1bff8 | 1 | 0x1c000 | 299593 | 2 / 2 |
| 48 | 0x20000 | 0x1fff8 | 1 | 0x20000 | 262144 | 1 / 1 |
Chaque arena possède un tableau de 49 entrées de size_class contenant les métadonnées pour chaque classe de taille. L'allocateur réserve pour chacune de ces classes une région de mémoire embarquant toutes ses allocations et segmentée en slabs. Ces slabs se découpent eux même en slots représentant chacun une allocation retournée à l'utilisateur.
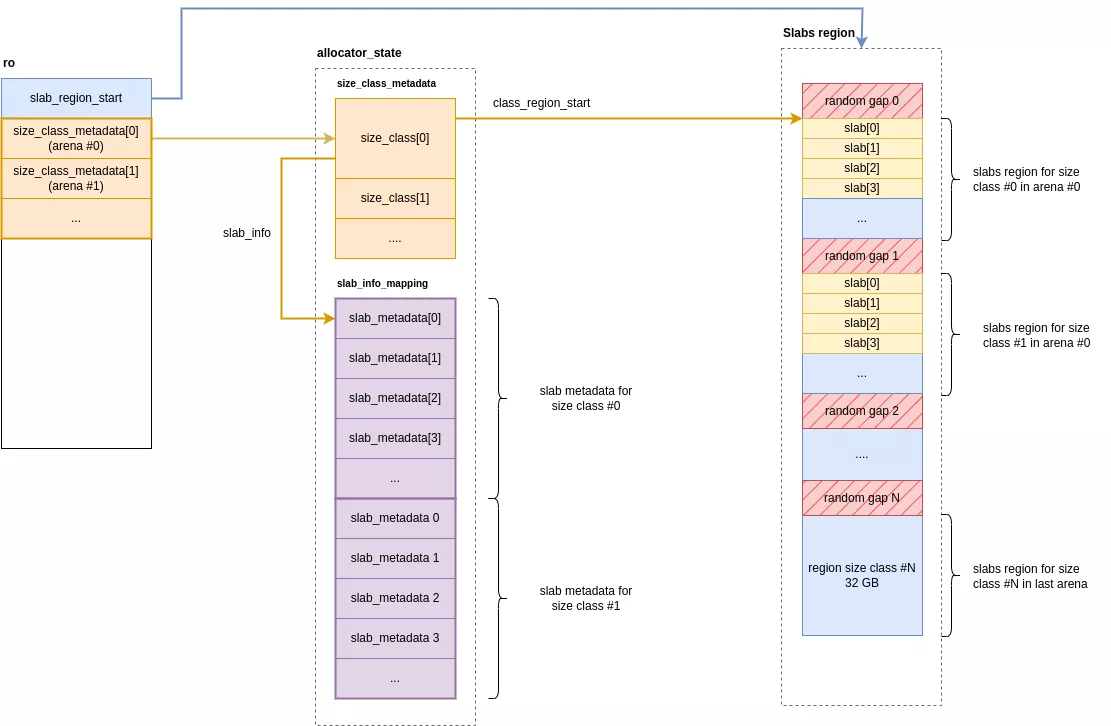
Les régions de toutes les classes sont réservées à l'initialisation de l'allocateur de manière contiguë en mémoire. Chaque région occupe 32 GiB à un offset aléatoire d'une zone de 64 GiB. Les zones de trous avant et après la région sont des gardes de taille aléatoire alignée sur une page. Pour récapituler :
- une région de 32 GiB par size class
- encapsulée à un offset aléatoire dans une zone 2 fois plus grande (64 GiB)
- les zones de 64 GiB sont contiguës et ordonnées par ordre croissant de size class
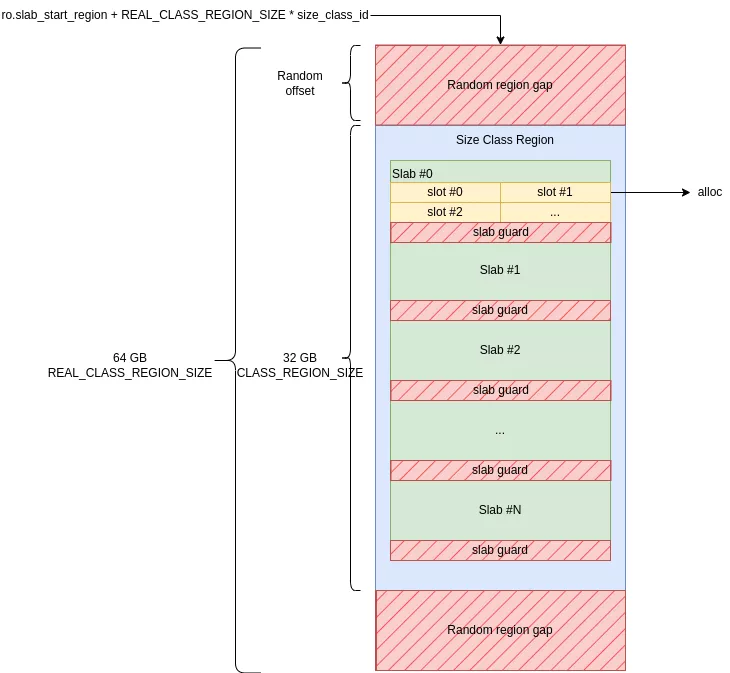
La zone contiguë de mémoire réservée lors de l'initialisation est de N_ARENA * 49 * 64 GiB. Sur les appareils de tests avec une unique arena, cela équivaut à 0x31000000000 octets (~3 TB). La protection par défaut sur ces pages est PROT_NONE, elles ne possèdent donc pas de pages physiques associées. Cette protection est passée en RW à la demande, sur certaines pages, en fonction des besoins d'allocation.
// CONFIG_EXTENDED_SIZE_CLASSES := true
// CONFIG_LARGE_SIZE_CLASSES := true
// CONFIG_CLASS_REGION_SIZE := 34359738368 # 32GiB
// CONFIG_N_ARENA := 1
#define CLASS_REGION_SIZE (size_t)CONFIG_CLASS_REGION_SIZE
#define REAL_CLASS_REGION_SIZE (CLASS_REGION_SIZE * 2)
#define ARENA_SIZE (REAL_CLASS_REGION_SIZE * N_SIZE_CLASSES)
static const size_t slab_region_size = ARENA_SIZE * N_ARENA; // 0x31000000000 on Pixel 4a 5G and Pixel 9a
// ...
COLD static void init_slow_path(void) {
// ...
// Create a big mapping with MTE enabled
ro.slab_region_start = memory_map_tagged(slab_region_size);
if (unlikely(ro.slab_region_start == NULL)) {
fatal_error("failed to allocate slab region");
}
void *slab_region_end = (char *)ro.slab_region_start + slab_region_size;
memory_set_name(ro.slab_region_start, slab_region_size, "malloc slab region gap");
// ...
}
Les size classes/bins sont représentées par la structure size_class. C'est une structure relativement grande qui contient toutes les informations d'une classe de taille donnée.
struct __attribute__((aligned(CACHELINE_SIZE))) size_class {
struct mutex lock;
void *class_region_start;
struct slab_metadata *slab_info;
struct libdivide_u32_t size_divisor;
struct libdivide_u64_t slab_size_divisor;
#if SLAB_QUARANTINE_RANDOM_LENGTH > 0
void *quarantine_random[SLAB_QUARANTINE_RANDOM_LENGTH << (MAX_SLAB_SIZE_CLASS_SHIFT - MIN_SLAB_SIZE_CLASS_SHIFT)];
#endif
#if SLAB_QUARANTINE_QUEUE_LENGTH > 0
void *quarantine_queue[SLAB_QUARANTINE_QUEUE_LENGTH << (MAX_SLAB_SIZE_CLASS_SHIFT - MIN_SLAB_SIZE_CLASS_SHIFT)];
size_t quarantine_queue_index;
#endif
// slabs with at least one allocated slot and at least one free slot
//
// LIFO doubly-linked list
struct slab_metadata *partial_slabs;
// slabs without allocated slots that are cached for near-term usage
//
// LIFO singly-linked list
struct slab_metadata *empty_slabs;
size_t empty_slabs_total; // length * slab_size
// slabs without allocated slots that are purged and memory protected
//
// FIFO singly-linked list
struct slab_metadata *free_slabs_head;
struct slab_metadata *free_slabs_tail;
struct slab_metadata *free_slabs_quarantine[FREE_SLABS_QUARANTINE_RANDOM_LENGTH];
#if CONFIG_STATS
u64 nmalloc; // may wrap (per jemalloc API)
u64 ndalloc; // may wrap (per jemalloc API)
size_t allocated;
size_t slab_allocated;
#endif
struct random_state rng;
size_t metadata_allocated;
size_t metadata_count;
size_t metadata_count_unguarded;
};
Les principaux membres de cettes structure sont les suivants :
class_region_start: adresse de début de la région contenant les slabs associés à cette size classslab_info: pointeur vers le début du tableau de métadonnées des slabsquarantine_random,quarantine_queue: tableaux contenant les pointeurs des allocations en quarantaine (cf. section sur les quarantaines)partial_slabs: pile contenant les métadonnées des slabs partiellement remplisfree_slabs_{head, tail}: file contenant les métadonnées des slabs avec aucune allocation
Les métadonnées des slabs sont conservées dans la structure slab_metadata. Pour une size class donnée, toutes ces structures sont organisées en un tableau contigu, accessible via le pointeur size_class->slab_info. L'ordre des métadonnées dans ce tableau correspond exactement à celui des slabs dans leur région mémoire. Grâce à cette conception, il suffit de connaître l'index d'un slab pour retrouver sa structure de métadonnées associée à ce même index.
struct slab_metadata {
u64 bitmap[4];
struct slab_metadata *next;
struct slab_metadata *prev;
#if SLAB_CANARY
u64 canary_value;
#endif
#ifdef SLAB_METADATA_COUNT
u16 count;
#endif
#if SLAB_QUARANTINE
u64 quarantine_bitmap[4];
#endif
#ifdef HAS_ARM_MTE
// arm_mte_tags is used as a u4 array (MTE tags are 4-bit wide)
//
// Its size is calculated by the following formula:
// (MAX_SLAB_SLOT_COUNT + 2) / 2
// MAX_SLAB_SLOT_COUNT is currently 256, 2 extra slots are needed for branchless handling of
// edge slots in tag_and_clear_slab_slot()
//
// It's intentionally placed at the end of struct to improve locality: for most size classes,
// slot count is far lower than MAX_SLAB_SLOT_COUNT.
u8 arm_mte_tags[129];
#endif
};
-
bitmap[4]: tableau de bits décrivant les slots utilisés du slab -
next, prev: pointeurs vers les éléments suivant et précédent lorsque la structure se trouve dans une liste chainée (par exemple, dans la pile des slabs partiellement utiliséssize_class->partial_slabs) -
canary_value: valeur du canari ajouté à la fin de tous les slots du même slab (uniquement pour les appareils sans MTE) et vérifiée à la libération de l'allocation -
arm_mte_tags[129]: tags MTE en cours d'utilisation par slot
Alloc
Tout d'abord, la taille réellement allouée est calculée en ajoutant 8 octets à la taille demandée. Ces octets correspondent au canari ajouté juste après les données. L'allocation est considérée small uniquement si cette taille est inférieure à 0x20000 (131072 octets). Ensuite, un slot libre doit être récupéré depuis un slab. Pour cela, les étapes suivantes se succèdent :
- Récupération de l'arena, stockée dans le thread local storage du thread
- Récupération des métadonnées de la size class (structure
size_class)ro.size_class_metadata[arena][size_class]: avecarenale numéro de l'arena etsize_classl'index de la classe calculée avec la taille de l'allocation
- Récupération d'un slab contenant un slot disponible depuis la size class :
- s'il y a un slab partiellement rempli,
size_class->partial_slabs != NULL, récupération de ce slab - sinon, si au moins un slab vide est disponible,
size_class->empty_slabs != NULL, récupération du premier slab de la liste - sinon, allocation d'un nouveau slab (allocation d'un
slab_metadataà l'aide de la fonctionalloc_metadata())- des slabs de garde sont réservés entre chaque slab réel
- s'il y a un slab partiellement rempli,
- Récupération d'un slot libre aléatoirement dans ce slab
- les slots occupés sont représentés par des bits à 1 dans
slab_metadata->bitmap - le slot est choisi de manière aléatoire dans le slab
- les slots occupés sont représentés par des bits à 1 dans
- Sélection du tag MTE pour le slot en excluant certaines valeurs afin que les slots adjacents n'aient jamais le même tag :
- tag du slot précédent
- tag du slot suivant
- ancien tag du slot séléctionné
- tag réservé
RESERVED_TAG(0) pour les allocations libres
- Pour les appareils sans MTE, écriture du canari dans les 8 derniers octets du slot qui est commun à tous les slots du slab, pour les autres ces octets restent à zéro
- Renvoi de l'adresse du slot taggé avec MTE
Dans le cas d'une small allocation, l'adresse retournée par malloc est donc un pointeur vers un slot contenant dans ses bits de poids fort un tag MTE de 4 bits. Ci-dessous sont affichés les pointeurs récupérés après des appels successifs à malloc(8), ils se trouvent bien dans le même slab mais à des offsets aléatoires à l'intérieur de celui-ci et possédent des tags MTE différents.
ptr[0] = 0xa00cd70ad02a930
ptr[1] = 0xf00cd70ad02ac50
ptr[2] = 0x300cd70ad02a2f0
ptr[3] = 0x900cd70ad02a020
ptr[4] = 0x300cd70ad02ac90
ptr[5] = 0x700cd70ad02a410
ptr[6] = 0xc00cd70ad02a3c0
ptr[7] = 0x500cd70ad02a3d0
ptr[8] = 0xf00cd70ad02a860
ptr[9] = 0x600cd70ad02ad20
Dans le cas où un accès out-of-bound ou un use-after-free se produit, une exception de type SIGSEGV/SEGV_MTESERR est levée, indiquant qu'une zone protégée par MTE a été accédée à l'aide d'un mauvais tag. Sur GrapheneOS, l'application se termine et un crashlog est envoyé dans le logcat.
07-23 11:32:19.948 4169 4169 F DEBUG : Cmdline: /data/local/tmp/bin libc.so
07-23 11:32:19.948 4169 4169 F DEBUG : pid: 4165, tid: 4165, name: bin >>> /data/local/tmp/bin <<<
07-23 11:32:19.948 4169 4169 F DEBUG : uid: 2000
07-23 11:32:19.949 4169 4169 F DEBUG : tagged_addr_ctrl: 000000000007fff3 (PR_TAGGED_ADDR_ENABLE, PR_MTE_TCF_SYNC, mask 0xfffe)
07-23 11:32:19.949 4169 4169 F DEBUG : pac_enabled_keys: 000000000000000f (PR_PAC_APIAKEY, PR_PAC_APIBKEY, PR_PAC_APDAKEY, PR_PAC_APDBKEY)
07-23 11:32:19.949 4169 4169 F DEBUG : signal 11 (SIGSEGV), code 9 (SEGV_MTESERR), fault addr 0x0500d541414042c0
07-23 11:32:19.949 4169 4169 F DEBUG : x0 0800d541414042c0 x1 0000d84c01173140 x2 0000000000000015 x3 0000000000000014
07-23 11:32:19.949 4169 4169 F DEBUG : x4 0000b1492c0f16b5 x5 0300d6f2d01ea99b x6 0000000000000029 x7 203d207972742029
07-23 11:32:19.949 4169 4169 F DEBUG : x8 5dde6df273e81100 x9 5dde6df273e81100 x10 0000000000001045 x11 0000000000001045
07-23 11:32:19.949 4169 4169 F DEBUG : x12 0000f2dbd10c1ca4 x13 0000000000000000 x14 0000000000000001 x15 0000000000000020
07-23 11:32:19.949 4169 4169 F DEBUG : x16 0000d84c0116e228 x17 0000d84c010faf50 x18 0000d84c1eb38000 x19 0500d541414042c0
07-23 11:32:19.949 4169 4169 F DEBUG : x20 0000000000001e03 x21 0000b1492c0f16e8 x22 0800d541414042c0 x23 0000000000000001
07-23 11:32:19.949 4169 4169 F DEBUG : x24 0000d541414042c0 x25 0000000000000000 x26 0000000000000000 x27 0000000000000000
07-23 11:32:19.949 4169 4169 F DEBUG : x28 0000000000000000 x29 0000f2dbd10c1f10
07-23 11:32:19.949 4169 4169 F DEBUG : lr 002bb1492c0f2ba0 sp 0000f2dbd10c1f10 pc 0000b1492c0f2ba4 pst 0000000060001000
Free
Lors de la libération d'une small allocation, la première étape consiste à retrouver l'index de la size class à partir du pointeur. Cet index servira à récupérer les métadonnées associées à cette size class ainsi que la région contenant les données de l'allocation. Il est calculé via la fonction slab_size_class.
static struct slab_size_class_info slab_size_class(const void *p) {
size_t offset = (const char *)p - (const char *)ro.slab_region_start;
unsigned arena = 0;
if (N_ARENA > 1) {
arena = offset / ARENA_SIZE;
offset -= arena * ARENA_SIZE;
}
return (struct slab_size_class_info){arena, offset / REAL_CLASS_REGION_SIZE};
}
Avec cet index, que l'on nommera class_id, il est maintenant possible de récupérer différentes informations liées au slab contenant l'allocation :
- la structure
size_class:size_class *c = &ro.size_class_metadata[size_class_info.arena][class_id]
- la taille des allocations de cette size class à l'aide du tableau associatif
size_classes:size_t size = size_classes[class_id]
- le nombre de slots par slab à l'aide du tableau associatif
size_class_slots:slots = size_class_slots[class_id]
- la taille des slabs :
slab_size = page_align(slots * size)
- les métadonnées du slab courant :
offset = (const char *)p - (const char *)c->class_region_startindex = offset / slab_sizeslab_metadata = c->slab_info + index
Ces informations sont suffisantes pour récupérer l'adresse de début du slab en utilisant la fonction get_slab().
static void *get_slab(const struct size_class *c, size_t slab_size, const struct slab_metadata *metadata) {
size_t index = metadata - c->slab_info;
return (char *)c->class_region_start + (index * slab_size);
}
L'adresse du slot est déduit avec la formule : slot = (const char*)slab - p, ainsi que son index : slot_index = (const char*)slab - slot) / slots.
Une fois le slot et son index récupérés, plusieurs vérifications de sécurité et d'intégrité sont effectuées. Cette phase est essentielle pour s'assurer que l'opération de libération est légitime et ne résulte pas d'un bug ou d'une attaque.
- Alignement du pointeur : l'allocateur vérifie que le pointeur correspond exactement au début d'un slot. Si ce n'est pas le cas (par exemple, il pointe au milieu d'un bloc alloué), c'est le signe d'une corruption de pointeur, et l'opération est avortée.
- État d'utilisation du slot : Le système consulte les métadonnées du slab pour confirmer que le slot est bien marqué comme "utilisé".
- Vérification du canari : le système vérifie que le canari, 8 octets en fin de slot, est intact et correspond au canari du slab courant. Cette valeur étant commune à tout le slab, un leak mémoire permettrait donc de réutiliser le canari d'un autre slot du même slab. Sur scudo ce n'est pas possible puisque le cookie du header est calculé à partir de l'adresse de l'allocation.
- Changement du tag MTE (Memory Tagging Extension) : l'allocateur assigne une valeur réservée (0) au tag du slot libéré afin que l'ancien tag ne soit plus valide pour cette zone.
- Mise à zéro du slot entier.
En cas de canari invalide, l'exception suivante est levée et le programme s'arrête :
07-23 02:14:09.559 7610 7610 F libc : hardened_malloc: fatal allocator error: canary corrupted
07-23 02:14:09.559 7610 7610 F libc : Fatal signal 6 (SIGABRT), code -1 (SI_QUEUE) in tid 7610 (bin), pid 7610 (bin)
07-23 02:14:09.775 7614 7614 F DEBUG : *** *** *** *** *** *** *** *** *** *** *** *** *** *** *** ***
07-23 02:14:09.775 7614 7614 F DEBUG : Build fingerprint: 'google/bramble/bramble:14/UP1A.231105.001.B2/2025021000:user/release-keys'
07-23 02:14:09.776 7614 7614 F DEBUG : Revision: 'MP1.0'
07-23 02:14:09.776 7614 7614 F DEBUG : ABI: 'arm64'
07-23 02:14:09.776 7614 7614 F DEBUG : Timestamp: 2025-07-23 02:14:09.603643955+0200
07-23 02:14:09.776 7614 7614 F DEBUG : Process uptime: 1s
07-23 02:14:09.776 7614 7614 F DEBUG : Cmdline: /data/local/tmp/bin
07-23 02:14:09.776 7614 7614 F DEBUG : pid: 7610, tid: 7610, name: bin >>> /data/local/tmp/bin <<<
07-23 02:14:09.776 7614 7614 F DEBUG : uid: 2000
07-23 02:14:09.776 7614 7614 F DEBUG : signal 6 (SIGABRT), code -1 (SI_QUEUE), fault addr --------
07-23 02:14:09.776 7614 7614 F DEBUG : Abort message: 'hardened_malloc: fatal allocator error: canary corrupted'
07-23 02:14:09.776 7614 7614 F DEBUG : x0 0000000000000000 x1 0000000000001dba x2 0000000000000006 x3 0000ea4a84242960
07-23 02:14:09.776 7614 7614 F DEBUG : x4 716e7360626e6b6b x5 716e7360626e6b6b x6 716e7360626e6b6b x7 7f7f7f7f7f7f7f7f
07-23 02:14:09.777 7614 7614 F DEBUG : x8 00000000000000f0 x9 0000cf1d482da2a0 x10 0000000000000001 x11 0000cf1d48331980
07-23 02:14:09.777 7614 7614 F DEBUG : x12 0000000000000004 x13 0000000000000033 x14 0000cf1d482da118 x15 0000cf1d482da050
07-23 02:14:09.777 7614 7614 F DEBUG : x16 0000cf1d483971e0 x17 0000cf1d48383650 x18 0000cf1d6fe40000 x19 0000000000001dba
07-23 02:14:09.777 7614 7614 F DEBUG : x20 0000000000001dba x21 00000000ffffffff x22 0000cc110ff0d150 x23 0000000000000000
07-23 02:14:09.777 7614 7614 F DEBUG : x24 0000000000000001 x25 0000cf0f4a421300 x26 0000000000000000 x27 0000cf0f4a421328
07-23 02:14:09.777 7614 7614 F DEBUG : x28 0000cf0f7ba30000 x29 0000ea4a842429e0
07-23 02:14:09.777 7614 7614 F DEBUG : lr 0000cf1d4831a9f8 sp 0000ea4a84242940 pc 0000cf1d4831aa24 pst 0000000000001000
Pour terminer, le slot n'est pas libéré immédiatement mais est placé en quarantaine dans le but d'ajouter un délai avant sa prochaine réutilisation.
Quarantaines
Chaque classe d'allocation maintient des quarantaines pour ses slots libérés. Lors de la libération d'une allocation, celle-ci n'est pas tout de suite rendue accessible mais passera successivement par 2 quarantaines :
- quarantaine random : tableau de pointeurs de taille fixe où les éléments sont inséré à un index aléatoire.
- quarantaine queue : FIFO recevant les slots éjectés de la quarantaine random.
Les tailles de ces quarantaines sont dépendantes de la classe d'allocation et détaillées dans le tableau décrivant les classes détaillé précédemment. Les quarantaines sont contenues dans la structure size_class :
struct __attribute__((aligned(CACHELINE_SIZE))) size_class {
// ...
#if SLAB_QUARANTINE_RANDOM_LENGTH > 0
void *quarantine_random[SLAB_QUARANTINE_RANDOM_LENGTH << (MAX_SLAB_SIZE_CLASS_SHIFT - MIN_SLAB_SIZE_CLASS_SHIFT)];
#endif
#if SLAB_QUARANTINE_QUEUE_LENGTH > 0
void *quarantine_queue[SLAB_QUARANTINE_QUEUE_LENGTH << (MAX_SLAB_SIZE_CLASS_SHIFT - MIN_SLAB_SIZE_CLASS_SHIFT)];
size_t quarantine_queue_index;
#endif
// ...
}
L'insertion dans la première quarantaine, la quarantaine random, s'effectue à un index aléatoire. L'élément présent à cet index sera retiré et inséré dans la seconde quarantaine. Cette dernière est une file dont l'index courant est conservé dans la structure size_class de la classe correspondante. Lors d'une insertion, l'allocation entrante est placée à l'index courant, l'élément remplacé est libéré et rendu disponible pour une prochaine allocation. Enfin, l'index courant est incrémenté.
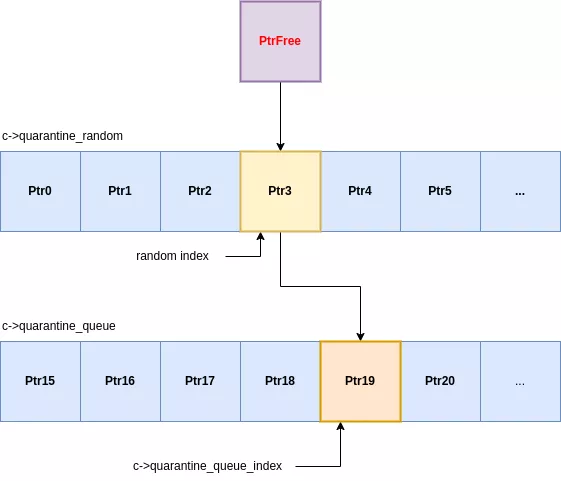
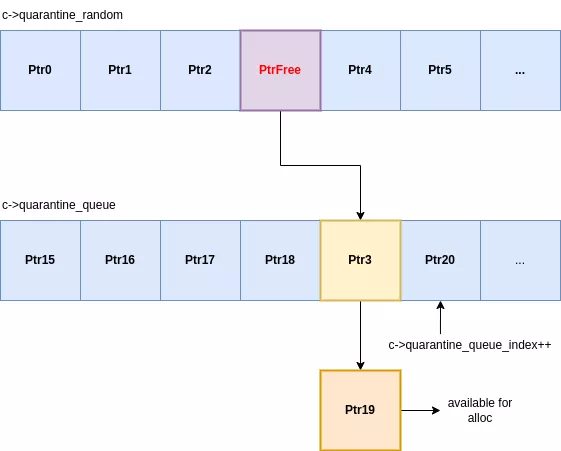
Contrairement aux allocateurs classiques, il n'y a pas de freelist sous forme de pile ce qui implique que la dernière allocation libérée ne sera pas la première réutilisée. Pour qu'une allocation soit réutilisée, il est nécessaire qu'elle passe par les 2 quarantaines. Il faut donc libérer suffisamment d'allocations pour que les éléments de quarantaine soient consommés. Ce mécanisme ajoute une incertitude lors de l'exploitation de vulnérabilités de type use-after-free et impacte tous les appareils, même ceux ne prenant pas en charge MTE.
L'allocateur n'ayant pas de freelist, le moyen le plus simple pour reuse est d'enchainer les appels à malloc et free. Le nombre de libérations nécessaire dépendra de la taille des quarantaines. Le code suivant a été utilisé pour tester le fonctionnement des quarantaines et les chances de réutilisation.
void reuse(void* target_ptr, size_t size) {
free(target_ptr);
for (int i = 0; ; i++) {
void* new_ptr = malloc(size);
if (untag(target_ptr) == untag(new_ptr)) {
printf("REUSED [size = 0x%x] target_ptr @ %p (new_ptr == %p) try = %d\n", size, target_ptr, new_ptr, i);
break;
}
free(new_ptr);
}
}
Par exemple, pour les allocations de taille 8, c'est-à-dire de size class 1, les 2 quarantaines possèdent 8192 éléments. 8192 libérations seront donc nécessaires pour retiré une allocation de la quarantaine queue. Ce nombre sera probablement bien plus élevé puisqu'il ne prend pas en compte la quarantaine random, qui choisit aléatoirement l'index de l'élément sortant. Lors de tests, il a fallu en moyenne ~19000 libérations avant de pouvoir réutiliser une allocation.
$ make launch
adb push libs/arm64-v8a/test /data/local/tmp
libs/arm64-v8a/test: 1 file pushed, 0 skipped. 0.5 MB/s (5192 bytes in 0.009s)
adb shell /data/local/tmp/test
REUSED [size = 0x8] ptr @ 0xb400c7a41875fa50 (new_ptr == 0xb400c7a41875fa50) try = 18327
Large allocations
Alloc
Contrairement aux petites allocations, les large allocations ne sont pas triées par taille dans des regions pré-réservées, l'allocateur les réserve à la demande. À noter que ce mécanisme est le seul à créer dynamiquement des mappings dans hardened malloc. La taille mappée dépendra de plusieurs éléments :
- taille alignée : calculée dans
get_large_size_classen alignant la taille demandée avec des classes de tailles, dans la continuité des tailles des petites allocations, - taille des zones de garde : nombre aléatoire de pages précédant et suivant l'allocation
static size_t get_large_size_class(size_t size) {
if (CONFIG_LARGE_SIZE_CLASSES) {
// Continue small size class growth pattern of power of 2 spacing classes:
//
// 4 KiB [20 KiB, 24 KiB, 28 KiB, 32 KiB]
// 8 KiB [40 KiB, 48 KiB, 54 KiB, 64 KiB]
// 16 KiB [80 KiB, 96 KiB, 112 KiB, 128 KiB]
// 32 KiB [160 KiB, 192 KiB, 224 KiB, 256 KiB]
// 512 KiB [2560 KiB, 3 MiB, 3584 KiB, 4 MiB]
// 1 MiB [5 MiB, 6 MiB, 7 MiB, 8 MiB]
// etc.
return get_size_info(max(size, (size_t)PAGE_SIZE)).size;
}
return page_align(size);
}
Une fois ces deux tailles calculées, l'allocateur crée un mapping via mmap en additionnant ces tailles. Les zones de garde, précédant et suivant les données, sont mappées en PROT_NONE tandis que la zone de données le sera en PROT_READ/PROT_WRITE. Cet ajout de pages de garde de taille aléatoire implique que deux large allocations de même taille auront des zones mappées de tailles différentes.
void *allocate_pages_aligned(size_t usable_size, size_t alignment, size_t guard_size, const char *name) {
//...
// Compute real mapped size = alloc_size + 2 * guard_size
size_t real_alloc_size;
if (unlikely(add_guards(alloc_size, guard_size, &real_alloc_size))) {
errno = ENOMEM;
return NULL;
}
// Mapping whole region with PROT_NONE
void *real = memory_map(real_alloc_size);
if (unlikely(real == NULL)) {
return NULL;
}
memory_set_name(real, real_alloc_size, name);
void *usable = (char *)real + guard_size;
size_t lead_size = align((uintptr_t)usable, alignment) - (uintptr_t)usable;
size_t trail_size = alloc_size - lead_size - usable_size;
void *base = (char *)usable + lead_size;
// Change protection to usable data with PROT_RAD|PROT_WRITE
if (unlikely(memory_protect_rw(base, usable_size))) {
memory_unmap(real, real_alloc_size);
return NULL;
}
//...
return base;
}
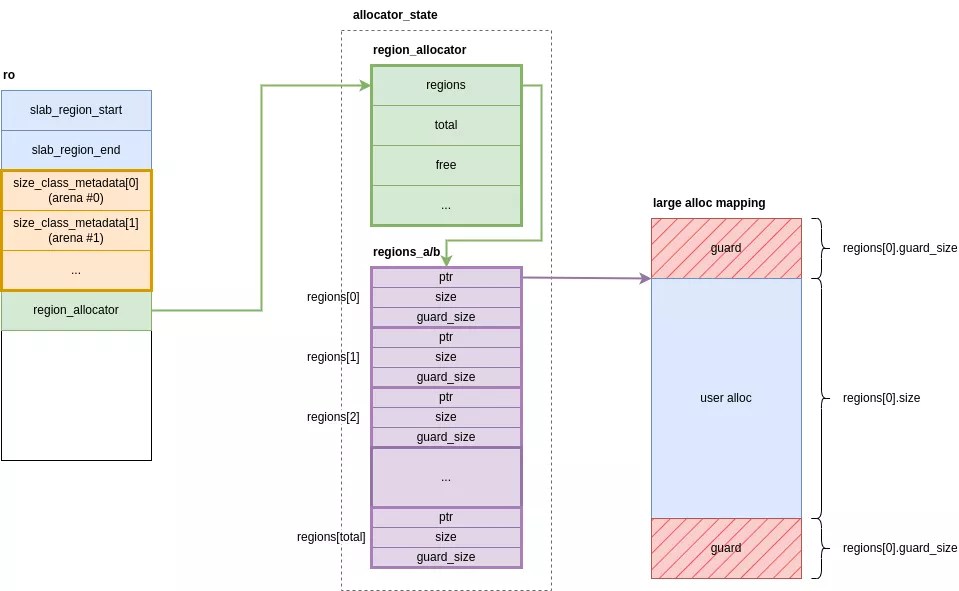
Si la création du mapping s'est bien déroulée, une structure contenant l'adresse, la taille utilisable et la taille de la zone de garde est insérée dans la table de hashes des regions. Cette table de hashes est représentée par 2 tableaux de struct region_metadata : alloctor_state.regions_a et allocator_state.regions_b, respectivement ro.regions[0] et ro.regions[1] dans la structure ro. Ils possèdent une taille statique et sont réservés à l'initialisation. Tous les éléments de ces tableaux ne sont pas accessibles dès l'initialisation, la zone mémoire des éléments utilisables est passée en RW et le reste en PROT_NONE. Les nombres totaux d'éléments utilisés et utilisables sont stockées réciproquement dans ro.region_allocator.total et ro.region_allocator.free. Lorsque le nombre d'éléments utilisés dépasse la taille totale, la zone accessible est étendue à deux fois la zone totale actuelle.
Les tableaux regions_a et regions_b sont utilisés de manière alternée en tant que table de hash de large allocations. Lors d'un accroissement du nombre d'éléments accessibles, le tableau actuel est recopié dans le tableau inutilisé, la zone accessible étendue et ce second tableau devient le tableau principal. L'ancien tableau est enfin remappé avec la protection PROT_NONE pour le rendre inaccessible.
static int regions_grow(void) {
struct region_allocator *ra = ro.region_allocator;
if (ra->total > SIZE_MAX / sizeof(struct region_metadata) / 2) {
return 1;
}
// Compute new grown size
size_t newtotal = ra->total * 2;
size_t newsize = newtotal * sizeof(struct region_metadata);
size_t mask = newtotal - 1;
if (newtotal > MAX_REGION_TABLE_SIZE) {
return 1;
}
// Select new metadata array
struct region_metadata *p = ra->regions == ro.regions[0] ?
ro.regions[1] : ro.regions[0];
// Enlarge new metadata elements
if (memory_protect_rw_metadata(p, newsize)) {
return 1;
}
// Copy elements to the new array
for (size_t i = 0; i < ra->total; i++) {
const void *q = ra->regions[i].p;
if (q != NULL) {
size_t index = hash_page(q) & mask;
while (p[index].p != NULL) {
index = (index - 1) & mask;
}
p[index] = ra->regions[i];
}
}
memory_map_fixed(ra->regions, ra->total * sizeof(struct region_metadata));
memory_set_name(ra->regions, ra->total * sizeof(struct region_metadata), "malloc allocator_state");
ra->free = ra->free + ra->total;
ra->total = newtotal;
// Switch current metadata array/hash table
ra->regions = p;
return 0;
}
Les métadonnées de l'allocation, adresse + taille + taille des zones de garde, sont enfin placées dans la table de hashes courante ro.region_allocator->regions.
Pour les large allocations, non protégées par MTE, les pages de garde à taille aléatoire constituent la seule protection contre les débordements. Si un attaquant parvient à déjouer cette randomisation et possède une vulnérabilité de type out-of-bounds read/write avec un offset précis, la corruption de données adjacentes reste un scénario possible, bien que complexe à réaliser.
Par exemple, lors de l'exécution d'un malloc(0x28001), les métadonnées suivantes sont créées pour gérer l'allocation. Une taille aléatoire de 0x18000 pour les pages de garde est choisie.
large alloc @ 0xc184d36f4ac8
ptr : 0xbe6cadf4c000
size : 0x30000
guard size: 0x18000
En affichant les zones mémoire du processus, la large allocation de taille 0x28001, qui passe à 0x30000 après alignement, se retrouve bien protégée entre 2 zones PROT_NONE de taille 0x18000.
be6cadf34000-be6cadf4c000 ---p 00000000 00:00 0
be6cadf4c000-be6cadf7c000 rw-p 00000000 00:00 0
be6cadf7c000-be6cadf94000 ---p 00000000 00:00 0
Free
La libération d'une large allocation est relativement simple et reprend le même mécanisme de quarantaines que les petites allocations.
- Calcul du hash du pointeur
- Récupération de la structure dans la table de hash actuelle
ro->region_allocator.regions - Mise en quarantaine si la taille est inférieure à
0x2000000(33554432)- Même mécanisme de quarantaine que pour les petites allocations : quarantaine random + quarantaine queue
- Les quarantaines sont globales à toutes les large allocations et stockées dans
ro.region_allocator
- Unmap des allocations sorties de quarantaine ou supérieures à
0x2000000memory_unmap((char *)usable - guard_size, usable_size + guard_size * 2)
Conclusion
Hardened malloc est un allocateur de mémoire axé sur la sécurité qui intègre plusieurs mécanismes de protection avancés, y compris la prise en charge de ARM Memory Tagging Extension (MTE) pour détecter et empêcher les corruptions mémoire. Bien qu'il offre une protection supérieure à l'allocateur scudo de base, en particulier vis-à-vis des use-after-free, sa véritable force se manifeste lorsqu'il est couplé à GrapheneOS. Cette combinaison offre un niveau de sécurité supérieur à celui d'un appareil Android standard utilisant scudo.
De plus, l'utilisation des canaris et de nombreuses pages de garde vient compléter son arsenal, notamment sur d'anciens appareils sans MTE, en entrainant rapidement la levée d'exceptions en cas d'accès mémoire non désirés.
Du point de vue d'un attaquant, hardened malloc réduit considérablement les opportunités d'exploitation des vulnérabilités de corruption mémoire :
- heap overflow : hardened malloc est relativement proche de scudo, il rajoute néanmoins des pages de gardes entre les slabs de même taille ce qui empêche un débordement de se propager d'un slab à un autre. Cependant, avec MTE activé, la protection devient bien plus fine : même un débordement à l'intérieur d'un même slab (d'un slot à un autre) est détecté et bloqué sans attendre la vérification du canari, rendant l'exploitation de ce type de vulnérabilité quasiment impossible.
- use-after-free : Le mécanisme de double quarantaine complexifie la réutilisation d'une zone mémoire libérée, mais ne la rend pas totalement impossible. Toutefois, MTE change radicalement la situation. Le pointeur et la zone mémoire associée sont "taggés". Lors de la libération (
free), ce tag est modifié. Toute tentative ultérieure d'utiliser l'ancien pointeur (avec son tag désormais invalide) lèvera très probablement une exception, neutralisant l'attaque. Pour les large allocations, qui ne sont pas couvertes par MTE, la stratégie est différente : chaque allocation est isolée par des pages de garde et son emplacement en mémoire est aléatoire. Cette combinaison d'isolation et de randomisation rend toute tentative de réutilisation de ces zones mémoire difficile et peu fiable pour un attaquant.
En outre, son implémentation s'est avérée être particulièrement claire et concise, facilitant son audit et sa maintenance.