Old bug, shallow bug: Exploiting Ubuntu at Pwn2Own Vancouver 2023
At this year Pwn2Own Vancouver we demonstrated Local Escalation of Privilege (LPE) exploits for the three desktop operating systems present at the competition: Windows, MacOS and Linux (Ubuntu). This blogpost explores the Ubuntu entry exploiting CVE-2023-35001, a 9 year old vulnerability in the Linux Kernel.
Vous souhaitez améliorer vos compétences ? Découvrez nos sessions de formation ! En savoir plus
Introduction
The surface available at Pwn2Own for LPEs is restricted to the kernel code. Through a survey of public exploits at the time of research, we found two areas in particular which were heavily targeted for exploitation.
The first is kernel code accessible through user namespaces. On most Linux distributions the default configuration exposes a pretty restricted attack surface, with most of the interesting functionality gated behind permission or capability checks. On Ubuntu, however, it is possible to completely open up the attack surface through the use of user namespaces, which are allowed for unprivileged users (through the kernel.unprivileged_userns_clone sysctl).
Then comes io_uring, a complex kernel subsystem used for fast asynchronous IO. This surface has been really popular for kernel exploits lately. So popular in fact that Google decided to remove io_uring from their kernelCTF builds of the linux kernel, as more than 60% of the exploits were targetting this subsystem in particular. From an attacker standpoint io_uring is interesting as the code is extremely complex, moves around a lot, and constantly grows to interact with additional parts of the kernel. It is also still accessible to unprivileged users on Ubuntu kernels.
In the end however we settled on the first option and chose to target kernel code accessible through user namespaces. One subsystem in particular caught our attention, nftables. Throughout 2022 and 2023 more than a dozen vulnerabilities were found in this subsystem and multiple LPE exploits relied on them.
An audit of this subsystem allowed us to discover a vulnerability, present since the introduction of nftables in the linux kernel back in version 3.13.
Exploit
nftables 101: Core objects
The nftables subsystem implements a register based virtual machine for packet filtering. It revolves around a few nested components: tables, chains, rules and expressions.
Expressions are the lowest level object and the actual instructions executed by the vm. They operate on the payload or metadata of incoming packets and implement basic operations (byte comparisons, arithmetic operations, set manipulation, ...). In memory, expressions are composed of a vtable pointer followed by variable length expression specific data:
struct nft_expr {
const struct nft_expr_ops *ops;
unsigned char data[]
__attribute__((aligned(__alignof__(u64))));
};
These expressions are bundled into rules, which are akin to statements in higher level languages. The vm executes each expression inside a rule and stops when either all expressions were executed, or when an expression sets the verdict register to something different from NFT_CONTINUE. The rule object is composed of a small header followed by an inline array of expressions:
struct nft_rule_dp {
u64 is_last:1, dlen:12, handle:42; /* for tracing */
unsigned char data[]
__attribute__((aligned(__alignof__(struct nft_expr))));
};
Chains are akin to functions in high level languages. They have a name and contain a list of rules to be executed. Like functions, chains can be called or jumped to using expressions. Much like the rule object, the chain object represents the list of rules as an object with a small header followed by an inline array of rule objects:
struct nft_rule_blob {
unsigned long size;
unsigned char data[]
__attribute__((aligned(__alignof__(struct nft_rule_dp))));
};
The top level object is the table, which is a container for chains. For the purpose of this blogpost, there is nothing more to know about it.
nftables 101: Usage
The nftables code is executed during two distinct phases, configuration and evaluation.
In the configuration phase, userland binaries such as nft communicate through netlink with nftables to prepare the firewall. Top level objects such as tables or chains are created directly, and objects such as rules and expressions are compiled down to bytecode before being sent through netlink. Sanity checks are done during this phase to prevent installing dangerous operations. For example, checks are done on loads and stores of registers to verify that the operations stay within the bounds of the register array.
The evaluation phase occurs when a packet is received. The vm executes the configured firewall operations and returns a verdict about what the network stack should do with the packet. It is interesting to note here that almost no checks are done during expression evaluation, as everything should have been checked during configuration. Being able to corrupt expressions after configuration could thus give powerful exploit primitives.
Vulnerability description
The vulnerability found during the audit occurs during the evaluation of the nft_byteorder expression. This operation implements endianness swapping of the vm's register contents. It takes in a length, representing the total number of bytes on which to operate, as well an element size which can be 2, 4 or 8 bytes wide. The vulnerability occurs in the handling of 16 bits elements:
void nft_byteorder_eval(const struct nft_expr *expr,
struct nft_regs *regs,
const struct nft_pktinfo *pkt)
{
const struct nft_byteorder *priv = nft_expr_priv(expr);
u32 *src = ®s->data[priv->sreg];
u32 *dst = ®s->data[priv->dreg];
union { u32 u32; u16 u16; } *s, *d; // <---- [1]
unsigned int i;
s = (void *)src;
d = (void *)dst;
switch (priv->size) {
case 8: {
// ...
}
case 4:
switch (priv->op) {
case NFT_BYTEORDER_NTOH:
for (i = 0; i < priv->len / 4; i++)
d[i].u32 = ntohl((__force __be32)s[i].u32);
break;
case NFT_BYTEORDER_HTON:
for (i = 0; i < priv->len / 4; i++)
d[i].u32 = (__force __u32)htonl(s[i].u32);
break;
}
break;
case 2:
switch (priv->op) {
case NFT_BYTEORDER_NTOH:
for (i = 0; i < priv->len / 2; i++)
d[i].u16 = ntohs((__force __be16)s[i].u16); // <---- [2]
break;
case NFT_BYTEORDER_HTON:
for (i = 0; i < priv->len / 2; i++)
d[i].u16 = (__force __u16)htons(s[i].u16); // <---- [2]
break;
}
break;
}
}
In [1], 2 pointers to an anonymous union are defined. These pointers are then aliased to the source and destination pointers defined above. The sreg and dreg fields of priv are correctly checked during the configuration phase, so src and dst are always in bounds. The same is true for the len field of priv.
The code for handling 4 bytes and 2 bytes elements uses the union for accessing the elements. While this implementation is valid for 4 bytes elements, it is invalid for handling the 2 bytes elements in [2]. In C, the size of an union is the size of its largest element. In this case the array accesses will be aligned on 4 bytes, regardless of the element size. This allows in the 2 bytes case to access memory out of bounds, which is on the stack as this is where the array of registers is allocated. The expected and actual behavior of the operation can be seen in the following illustration:
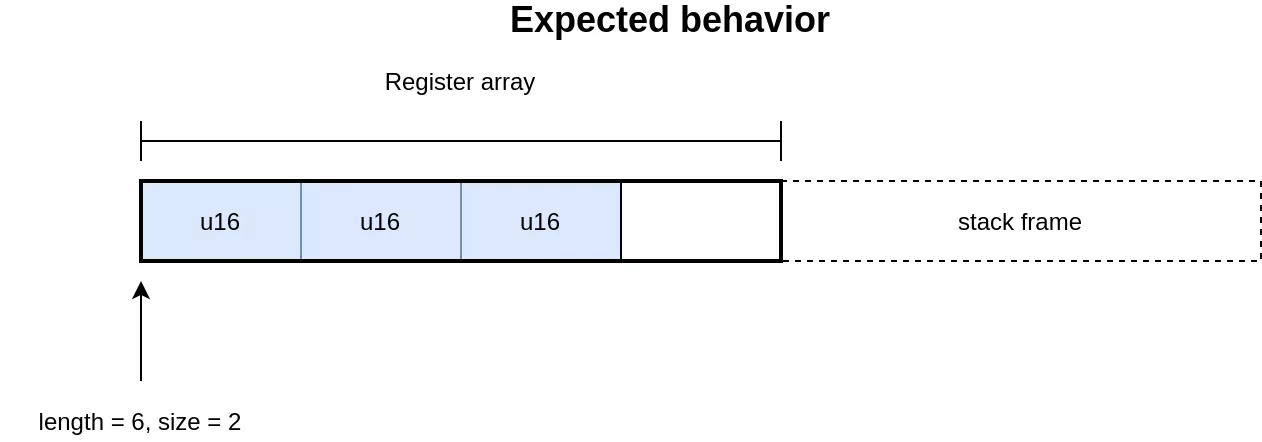
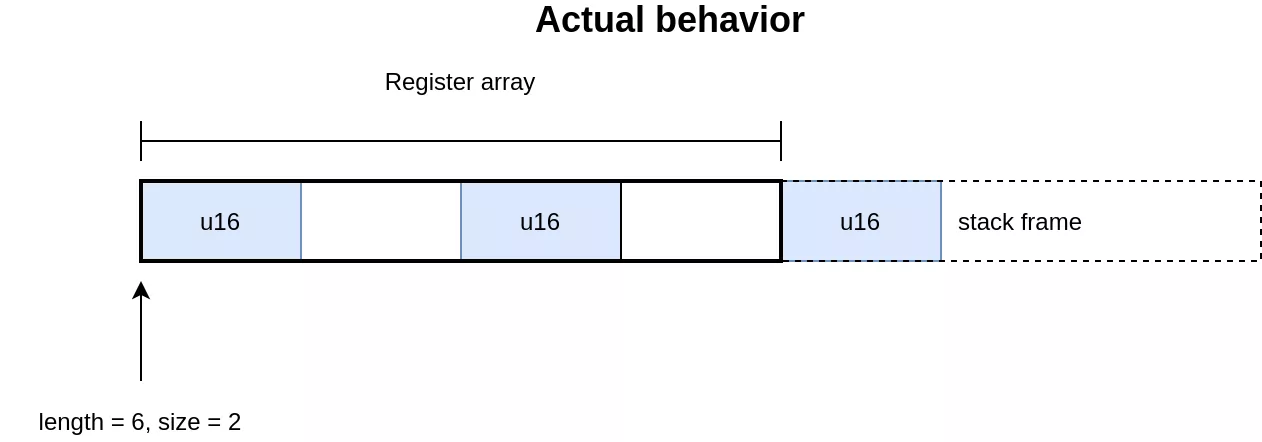
Exploit outline
The out-of-bounds access primitive has the following constraints:
- All accesses are 2 bytes wide
- All accesses are aligned on 4 bytes
priv->lengthis still checked, and the overflow range is limited to few dozen bytes after the array
To get a clear idea of what is overwritable we need to check the function nft_do_chain, whose stack frame contains the vm registers:
unsigned int
nft_do_chain(struct nft_pktinfo *pkt, void *priv)
{
const struct nft_chain *chain = priv, *basechain = chain;
const struct nft_rule_dp *rule, *last_rule;
const struct net *net = nft_net(pkt);
const struct nft_expr *expr, *last;
struct nft_regs regs = {};
unsigned int stackptr = 0;
struct nft_jumpstack jumpstack[NFT_JUMP_STACK_SIZE];
bool genbit = READ_ONCE(net->nft.gencursor);
struct nft_rule_blob *blob;
struct nft_traceinfo info;
// ...
}
By using a kernel debugger, we notice that the jumpstack array directly follows the registers and is the only data reachable with the overflow. Its purpose is to record at the moment of jump expressions the position in the current chain's rules. At the end of the subchain evaluation the top jumpstack entry is popped to resume execution in the correct place. A jumpstack entry has the following definition:
struct nft_jumpstack {
const struct nft_chain *chain;
const struct nft_rule_dp *rule;
const struct nft_rule_dp *last_rule;
};
Using the vulnerability it is possible to leak and overwrite the two lower bytes of these pointers to misalign them. The interesting pointers to target in this structure are rule and last_rule. By making them point to a fake rule it should be possible to execute arbitrary expressions and gain kernel code execution. To reach this goal we designed the following exploit strategy:
- Leak nf_tables.ko to compute expression vtable addresses
- Leak the kernel base using a crafted expression
- Use a crafted expression to write a ropchain and gain code execution
Template setup
To overflow the nft_rule_dp pointer in a stable way we need to leak them first. A way of doing this is by using two chains. The top chain calls a subchain, which contains a nft_byteorder expression. As the first chain pushes an entry on the jumpstack, the subchain can read or write to it using the vulnerability.
The jumpstack entry can be leaked through the registers by making the destination register point to the beginning of the array and the source to the end, where it will read out-of-bounds.
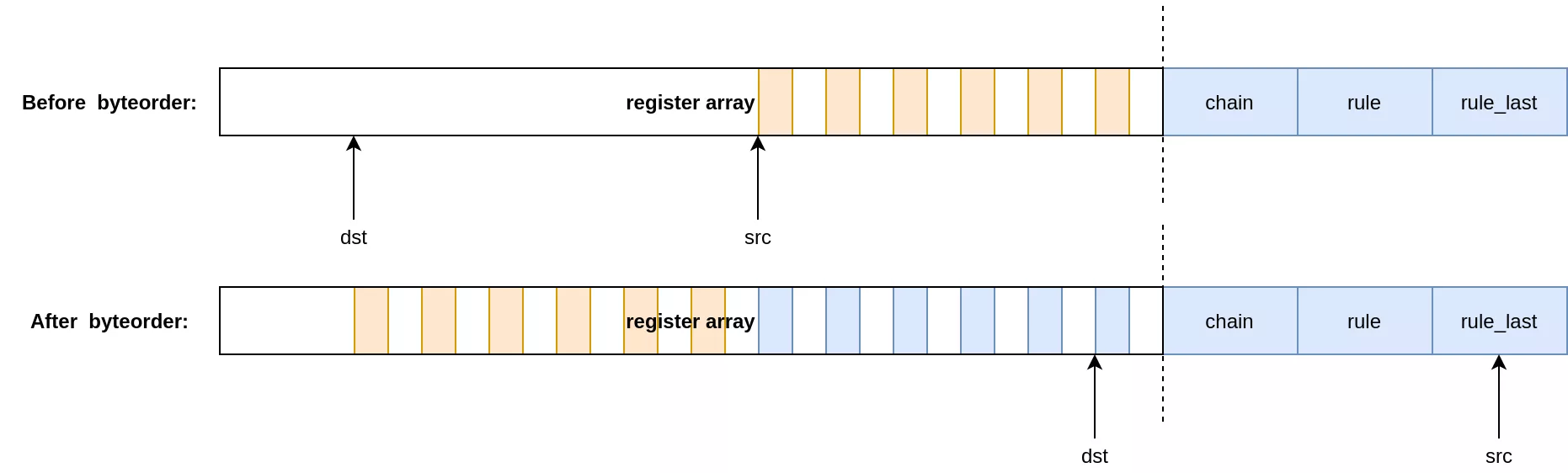
The registers in blue in the figure contain parts of the jumpstack pointers (bits [0:15] and [32:47]). They can be recovered from userland by writing them to a map object using the nft_dynset expression.
To overwrite the pointers, the rule doing the leak must be flushed and its expressions replaced by the opposite of the leak. Source and destination registers are swapped, and the chosen value for the overwrite must be placed inside the register array. Do note that at some point src will overlap with a value written through dst. Effectively, the values we input for the overwrite will be byteswapped twice before being written out-of-bounds.
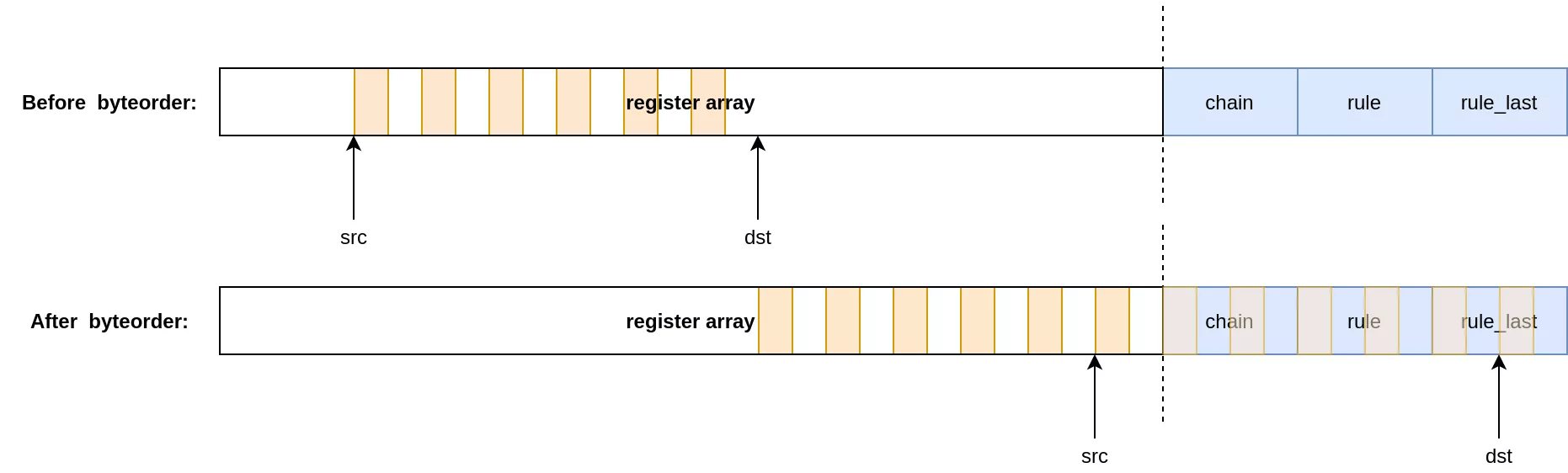
In the end the setup consists of two chains:
- The base-chain, whose role is to jump to another chain to fill the jumpstack and store the leak pointer in a set
- The leak-chain, whose role is to contain the leak and overwrite operation
The following process is followed by all the exploit steps:
- Fill base-chain with required expressions
- Fill leak-chain with payload for the leak
- Send packet to evaluate chain and recover the base-chain jumpstack pointers
- Replace leak-chain expressions with the overwrite payload
- Send packet to evaluate chain, which will corrupt the top jumpstack entry
- Profit ?
Module infoleak
Only a few mechanisms allow a user of nftables to return data from the kernel to userland. Netlink dump command, nft_log expressions, and nftables execution tracing.
The netlink dump command allows recovering the state of all objects in a table in a serialized form. However, it is not used on the packet evaluation path and cannot be used for an infoleak.
The nft_log expression allows sending packet information back to userland for logging. Additionally, an arbitrary prefix of size up to 128 can be provided by the user. This prefix being heap allocated, it could be used in a use-after-free situation to leak heap data. However, on kernel 5.19 and above every nftables allocation uses GFP_KERNEL_ACCOUNT while the prefix still uses the general heap, making the setup for a leak too complex and brittle to implement.
The last functionality is nftables execution tracing. If the tracing bit on a packet is set, the nftables subsystem will send back to userland a blob of information on every executed rule. This is the mecanism we used for an infoleak.
Inside nft_do_chain, rule tracing is implemented through calls to nft_trace_rule and nft_trace_verdict. If tracing is enabled they end up calling nft_trace_notify. This function fills out information about a packet and the rule being evaluated such as:
- Protocol
- Trace type (VERDICT, RULE, POLICY, ...)
- Chain name
- Table name
- Rule handle (identifier)
From the evaluation path most of these values cannot be controlled or would be to tedious to use, such as trying to leak through name strings. One interesting candidate however is the rule handle. It sits inside the nft_rule_dp structure and we can corrupt pointers to those. By misaligning a rule pointer and making it overlap an ops pointer, it should be possible to recover the pointer from userland through the handle field. This is the theory, as in practice a few hurdles need to be overcome first.
We start from the code serializing the rule handle itself, nft_trace_fill_rule_info:
static int nf_trace_fill_rule_info(struct sk_buff *nlskb,
const struct nft_traceinfo *info)
{
if (!info->rule || info->rule->is_last) // <---- [1]
return 0;
/* a continue verdict with ->type == RETURN means that this is
* an implicit return (end of chain reached).
*
* Since no rule matched, the ->rule pointer is invalid.
*/
if (info->type == NFT_TRACETYPE_RETURN && // <---- [2]
info->verdict->code == NFT_CONTINUE)
return 0;
return nla_put_be64(nlskb, NFTA_TRACE_RULE_HANDLE,
cpu_to_be64(info->rule->handle),
NFTA_TRACE_PAD);
}
This function shows the first two constraints. In [1] the code checks that the rule must not be the last of the chain. The second check in [2] verifies that the tracetype is different from NFT_TRACETYPE_RETURN. It forces us to go through the nft_trace_packet function. By going up the call stack and checking the evaluation loop in nft_do_chain, a few other constraints can be deduced:
next_rule:
regs.verdict.code = NFT_CONTINUE;
for (; rule < last_rule; rule = nft_rule_next(rule)) {
nft_rule_dp_for_each_expr(expr, last, rule) {
if (expr->ops == &nft_cmp_fast_ops)
nft_cmp_fast_eval(expr, ®s);
else if (expr->ops == &nft_cmp16_fast_ops)
nft_cmp16_fast_eval(expr, ®s);
else if (expr->ops == &nft_bitwise_fast_ops)
nft_bitwise_fast_eval(expr, ®s);
else if (expr->ops != &nft_payload_fast_ops ||
!nft_payload_fast_eval(expr, ®s, pkt))
expr_call_ops_eval(expr, ®s, pkt);
if (regs.verdict.code != NFT_CONTINUE)
break;
}
switch (regs.verdict.code) {
case NFT_BREAK:
regs.verdict.code = NFT_CONTINUE;
nft_trace_copy_nftrace(pkt, &info);
continue;
case NFT_CONTINUE:
nft_trace_packet(pkt, &info, chain, rule,
NFT_TRACETYPE_RULE);
continue;
}
break;
}
While misaligning the rule pointers we need to make sure that:
last_rule > ruleto enter the looprule->dlenmust be 0, otherwise misaligned data will be evaluated as expressions (without a module leak expression ops pointers cannot be crafted yet)- The misaligned rule should be the last, otherwise arbitrary data will be evaluated as the next rule
The last constraint for this to run at all is that packet tracing should be enabled, which can be done using an nft_meta expression.
To solve all these constraints the following setup was used:
- Setup base-chain with two rules:
nft_metaexpression to enable tracing- jump
leak_chain+verdict_returnexpression (which is annft_immediateexpression)
- Overwrite
rulepointer to point two bytes beforeverdict_returnops pointer - Overwrite
last_ruleto point 8 bytes after the newrulepointer
After the pointer corruption the overlap looks as follows:
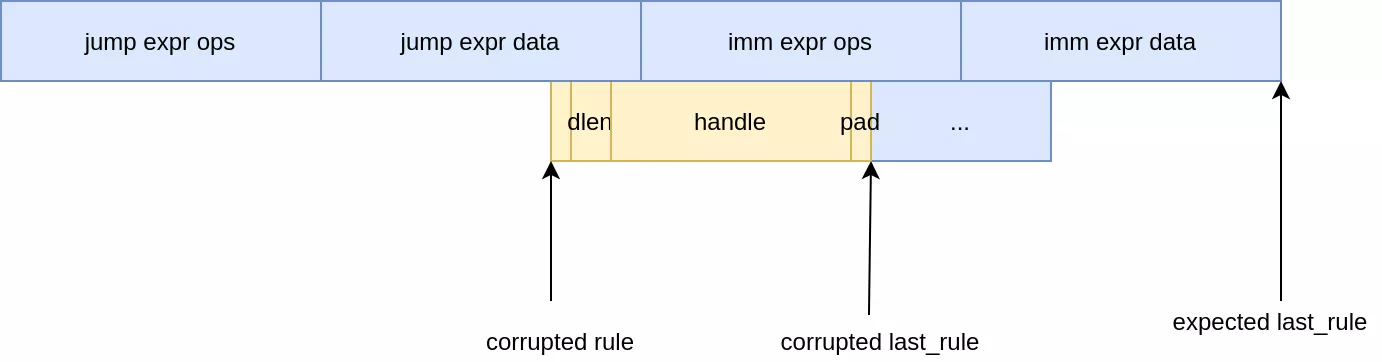
To understand why it works, let's first recall the structure of a rule:
struct nft_rule_dp {
u64 is_last:1, dlen:12, handle:42; /* for tracing */
unsigned char data[]
__attribute__((aligned(__alignof__(struct nft_expr))));
};
Setting the rule pointer two bytes before the start of the ops pointer means that is_last, dlen and 3 bits of the handle will overlap with the end of the jump expression. In practice this "jump" expression is an nft_immediate expression and has the following memory layout:
struct nft_immediate_expr {
struct nft_data data __attribute__((__aligned__(8))); /* 0 16 */
u8 dreg; /* 16 1 */
u8 dlen; /* 17 1 */
/* size: 24, cachelines: 1, members: 3 */
/* padding: 6 */
/* forced alignments: 1 */
/* last cacheline: 24 bytes */
} __attribute__((__aligned__(8)));
Two bytes before the end of the object ends up in the padding. As all nft private data is allocated with kzalloc, the last two bytes of the structure will be null. As such, dlen and is_last will be 0 as required by the constraints.
The rule < last_rule constraint is verified as well and will not cause unwanted behavior. To obtain the pointer to the next nft_rule_dp the code takes the rule pointer, adds 8 for the header, and adds dlen for the rule contents. As last_rule is set 8 bytes away from rule, we end up at rule == last_rule which exits gracefully.
One issue with this approach is that only 39 bits of the ops pointer are leaked. In practice however, we observed that this was not an issue as most top bits of kernel pointers are set to 1.
To recover the leaked pointer, a netlink socket subscribing to the NFNLGRP_NFTRACE group must be created. The serialized trace can be recovered by reading from the socket after the execution of the payload.
kASLR leak
From the ops leaks obtained in the previous step, it is possible to recover the base address of nf_table.ko and compute the address of ops pointers for core expressions. To break kASLR in this step we use a crafted nft_byteorder expression with a large source register index to read a return address from the stack.
One way of executing arbitrary expressions would be to spray crafted rule blobs around the current blob, and redirect the pointers to the fake object. This however introduces a probabilistic element in the exploit.
Instead, fake rule blobs can be created within nft expressions themselves. It has the advantage of being completely deterministic.
For this step the setup is as follows:
- Fill base-chain with three rules:
- jump to leak-chain
- Rule embedding the crafted rule within an expression
- Rule writing the leaked pointer to a set (
nft_dynset)
This strategy however has a few constraints:
- Expressions embed a limited amount of user controllable data
- As we did not leak the dynset module and set pointers, it is not possible to craft set expressions. We need to execute the third rule after the crafted rule gracefully.
For the first point an interesting expression is the nft_range expressions, which has the following structure:
struct nft_range_expr {
struct nft_data data_from;
struct nft_data data_to;
u8 sreg;
u8 len;
enum nft_range_ops op:8;
};
The nft_data structure is 16 bytes wide and its contents are fully user controlled. In total, it gives us 32 bytes of fake rule and expression data. There is however an issue. A rule header is 8 bytes and an nft_byteorder expression is 16 bytes. This leaves only 8 bytes for a last expression, but all expressions are above 8 bytes in size.
To solve this problem we can make the second expression overlap with the last fields of the nft_range expression. For this purpose, we used the nft_meta expression:
struct nft_meta {
enum nft_meta_keys key:8;
u8 len;
union {
u8 dreg;
u8 sreg;
};
};
The key and len fields of the nft_meta expression will overlap with the sreg and len fields of the nft_range expression. If we set the sreg to 8 in the range expression, which is the first available register, the value as a key will be invalid. Luckily, an invalid key in nft_meta_set_ops will only trigger a WARN_ON as seen in the code:
void nft_meta_set_eval(const struct nft_expr *expr,
struct nft_regs *regs,
const struct nft_pktinfo *pkt)
{
const struct nft_meta *meta = nft_expr_priv(expr);
struct sk_buff *skb = pkt->skb;
u32 *sreg = ®s->data[meta->sreg];
u32 value = *sreg;
u8 value8;
switch (meta->key) {
case NFT_META_MARK:
case NFT_META_PRIORITY:
// ...
default:
WARN_ON(1);
}
}
Graphically, the final setup for the overlap is the following:
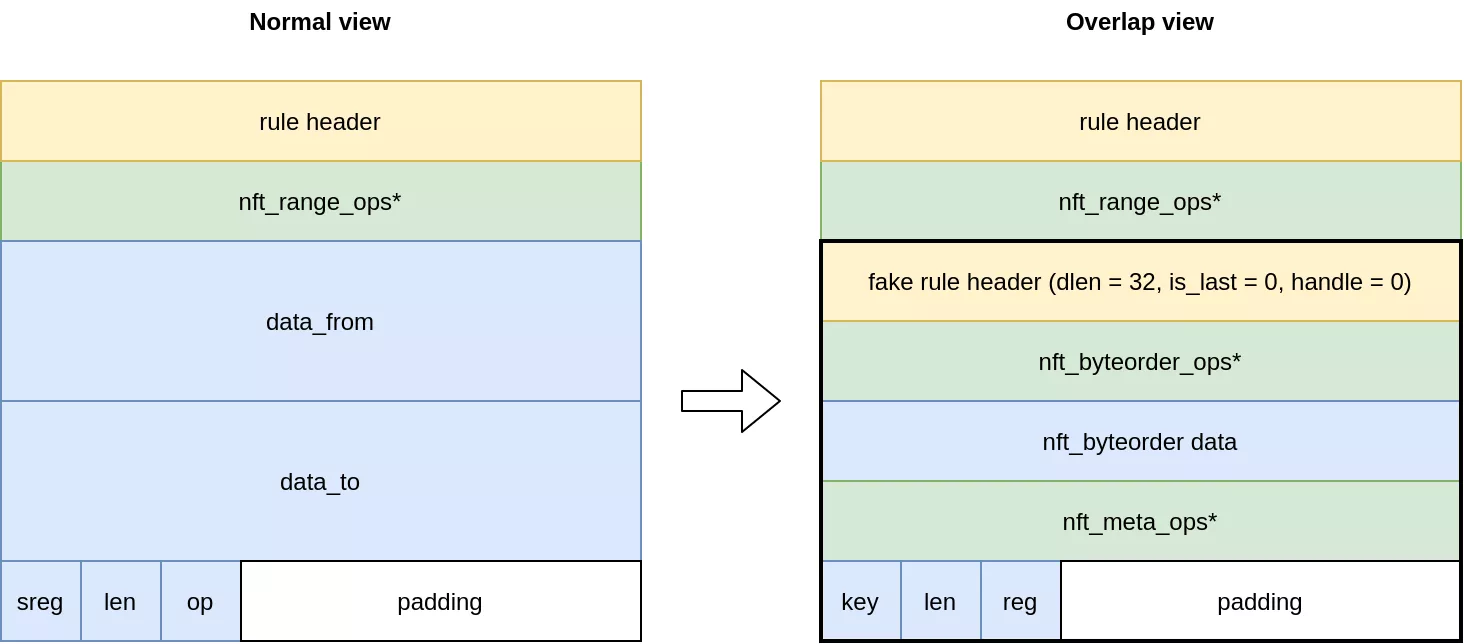
Even though nft_meta actual size is 4 bytes, the resulting size as defined in the ops is 8 (due to the NFT_EXPR_SIZE macro). This makes the crafted rule's end align perfectly with the original rule's end. As such the virtual machine continues executing normally the next rule, which is the one writing the leaked kernel pointer to the set.
The actual exploitation follows the same process as before. First, the pointer to the rule containing the nft_range expression is leaked (low 16 bits). Then, the jumpstack rule pointer is overwritten to point into the crafted rule contained in the nft_range expression . The last_rule pointer itself is not modified as we wish to continue execution normally after the crafted rule.
Kernel Code Execution
For kernel code execution we chose to use a ropchain as we have an easy access to the stack. Storing a ropchain and using a fake nft_byteorder to copy the ropchain beyond the stack cookie would be an idea. However, it is not flexible enough and limits the size of the ropchain.
Instead, a fake nft_payload expression can be crafted. It has the following definition:
struct nft_payload {
enum nft_payload_bases base:8;
u8 offset;
u8 len;
u8 dreg;
};
This expression copies len bytes from a given offset in the packet contents to the specified dreg in the register array. By specifying an out-of-bounds dreg pointing to the return address, and by sending the ropchain in a network packet, we get code execution. For the copy, the same exploit template as in the previous step is reused. The only change is to replace nft_byteorder by nft_payload in the crafted rule.
The ropchain itself does the following actions:
- calls
set_memory_rwonsys_modify_ldt - calls
copy_from_user_priv, reading shellcode from userland tosys_modify_ldt- Shellcode is a simple
commit_creds(prepare_kernel_creds(0))
- Shellcode is a simple
- calls
do_task_deadto hang the kernel thread
Afterwards, any process making a sys_modify_ldt syscall will be granted root privileges.
Conclusion
The vulnerability we found in the nftables subsystem is very shallow and self contained. It was interesting to see that such a bug was able to survive for so long, even after the audit done by researchers on this surface during the past few years. This example illustrates that the mindset of "people already looked at this, there are no other vulnerabilities to be found" can be wrong. As a junior security researcher I find it very comforting.
The code for the exploit described in this post can be found on Synacktiv's Github. It is 100% stable, and supports the kernel versions available at the time of the event.
We would also like to thank ZDI for organizing the Pwn2Own event. See you next year !