Building a io_uring based network scanner in Rust
Using the recent io_uring Linux kernel API to build a fast and modular network scanner in the Rust language
Vous souhaitez améliorer vos compétences ? Découvrez nos sessions de formation ! En savoir plus
Network performance on Linux is an ever evolving topic. Among the different approaches to reach maximum software performance, some solutions rely on special interfaces to avoid copying data between kernel and user space, like AF_XDP sockets. Other frameworks go further by bypassing the kernel packet processing, partly or completely (DPDK, PF_Ring, Netmap...). This can remove the need from any context switch between kernel and user space, but requires the software to implement all packet processing in user space, including the IP layer, and all its complexities (routing, fragmentation, etc.). For TCP traffic this is even more complex and requires tracking the state of each connection, handling retransmissions, etc.
As we can see, each of theses approaches brings its own advantages and drawbacks: bypassing the kernel can allow reaching maximum theoretical performance, but forces the programmer to implement all packet processing in its own software, adding complexity, increasing the probability of bugs, and losing the safety and checks of the kernel network stack. Solutions relying on BSD sockets bring instead the confort and developer productivity of a higher level API, but with a much lower overall performance.
Here we will focus on a relatively new kernel API called io_uring, which seems to strike a balance between network performance and developer velocity. To illustrate its ease of use and performance, we will build a fully functional modular network scanner with the Rust language.
io_uring, the new kid on the block
io_uring is a new Linux kernel interface for user space programs, to execute asynchronous I/O operations. It was mainlined in Linux 5.1 in 2019, and sees frequent fixes and improvements since then.
io_uring works with 2 rings (or queues) : the Submission Queue (SQ) and the Completion Queue (CQ). To do some work, the user pushes entries into the submission queue. Each entry corresponds to the operation of a system call. Not all system calls can be used with io_uring though, but basic operations on files and sockets are supported. An entry contains parameters depending on the operation, for example a write operation will have a buffer and associated size. Then the programs gets the result of the operations from the completion ring. Each operation completed has a return code set by the kernel, just like its classic system call counterpart. It is important however to note that the operations may be completed in a different order they are submitted. We will get back to the implication of this later on.
In a classic program, to make an HTTP request, a programmer typically does at the very least the following C library calls for network operations:
- socket: to create the TCP socket
- connect: to connect to the remote server
- send: to send the request
- recv: to receive the response
- close: to close the created socket
Note that this is in many case more complex than that, and may involve TLS, several send or recv calls for large buffers or setsockopt calls for example to handle timeouts. Of course many programs abstract this processing behind higher level functions or libraries like libcurl, but these calls are still made behind the scene anyway. Each of these involve leaving user space and entering kernel space, copying buffer data or syscall parameters, do the actual processing, and then returning back to user space. In a network scanner in which we may do this for thousands of IPs, this overhead quickly adds up, and takes up an important part of CPU time. One of the design principle of io_uring is to remove the overhead of syscalls. By pushing operations in the submission ring, and reading the result in the completion ring, we can make this processing much more simple, and do this for many IPs at the same time without needing to use threading or epoll.
Designing our scanner
Now that we know how io_uring works, we can start designing our scanner. Fortunately, Rust already has io_uring low level bindings that are very close to the official C API which we will rely on for this project.
We can already define the basic processing steps of our scanner:
- iterate over the IP addresses of the range we want to scan
- push entries for the operations on each IP (connect, send, recv...) in the submission ring
- get the result of the operations from the completion ring
Pushing entries involves some handling specific to io_uring: some operations can be run in parallel, others have specific dependencies between them. For example, it makes sense to connect to two different IPs simultaneously because to the two operations have no dependency between them. However it makes no sense to write to a TCP socket before having successfully finished the connect step for the same socket, so this is a case of an ordering (the second one is run only after the second) and success (the second one is canceled if the first one fails) dependency. Those dependencies car be represented using the IO_LINK entry flags.
Another interesting io_uring feature we will use is the ability to set timeouts to linked operations. By pushing a special LINK_TIMEOUT entry in the completion ring, we can instruct the kernel to cancel the previous operation in the ring (and all operations that depend on it) if it takes more than a certain amount of times to run. In a network scanner where many addresses may not respond at all to network packets, this is a much needed feature.
// Building a connect op on 127.0.0.1:1234 with a 10 seconds timeout
let sckt = socket(
AddressFamily::Inet,
SockType::Stream,
SockFlag::empty(),
None,
)
.expect("Failed to create TCP socket");
let addr = SockaddrIn::new(127, 0, 0, 1, 1234);
let op_connect = opcode::Connect::new(Fd(sckt.as_raw_fd()), addr.as_ptr(), addr.len())
.build()
.flags(squeue::Flags::IO_LINK);
let connect_timeout = Timespec::new().sec(10);
let op_connect_timeout = opcode::LinkTimeout::new(&connect_timeout).build();
let ops = [op_connect, op_connect_timeout]; // ops ready to send to SQ
So far we have described a network scanner that uses io_uring to reduce the number of system calls. However this processing also involves copying buffer from user space to kernel space (write/send) and the reverse (read/recv), which is a large part of processing time that can be targeted for optimization.
Fixed buffers to the rescue
To avoid buffer copies (a concept commonly known as 0-copy processing) io_during provides opt-in special handling for buffers then called fixed buffers. The concept is simple: the program allocates buffers in user space as usual, and then registers them using an io_uring API. The kernel then maps the buffer pages both in user space and kernel space, so buffer copies are no longer needed. It is however the responsibility of the program to ensure buffers are not modified once an entry referencing them are being processed by the kernel.
// Allocate and register a single fixed buffer
let mut rx_buffer: Vec<u8> = vec![0; 128];
let fixed_buffer = iovec {
iov_base: rx_buffer.as_mut_ptr() as *mut c_void,
iov_len: rx_buffer.len(),
};
submitter
.register_buffers(&[fixed_buffer])
.expect("Failed to register buffers");
// Build an operation to read on a socket using our fixed buffer to benefit from 0-copy
let op_recv = opcode::ReadFixed::new(
Fd(sckt.as_raw_fd()),
fixed_buffer.iov_base.cast::<u8>(),
fixed_buffer.iov_len as u32,
0, // buffer index
)
.build();
This last constraint is very important and is a common pitfall when using the io_uring Rust bindings. The Rust langage is well known to close whole classes of possible bugs by tracking ownerships, lifetimes, and concurrent use, and making it impossible to misuse memory in ways C or C++ do. However in our case we are using a mechanism whose goal is to share data with the kernel, by removing the usual user/kernel space clear frontier usually set by system calls. When we push entries in the submission ring, they are referring to addresses of structure and buffers the kernel will use, but the Rust compiler has no understanding of the io_uring specifics and cannot see that the logical ownership of this data is no longer the program, until the entry is done being processed and shows up in the completion ring. Not being careful about this can quickly lead to hard to track random bugs, for example when creating short lived data on the stack, then referencing its address in an entry and pushing it in the submission ring. Immediately after this, the Rust program will drop the logical data because it identifies it is no longer in use, and by the time the kernel thread starts processing the entry, the address may refer to completely different data overwritten on the stack. To avoid this, the user needs to manually (without relying on the Rust borrow checker which cannot help here) ensure that the data whose addresses is set in the entries, is valid at least as long as the entry is being processed. We will see how to translate this constraint in the program in the next part.
State tracking
As we can see, operating the rings is actually not very complex, but requires special care when using adresses. For this we will build our own data structure to track entry state.
When processing entries from the completion ring, we only get the return code of the operation, and a unique integer we have set in the submission entry. Since entries in the completion ring may arrive in a different order than the one they were submitted with, at this point, we need to find out metadata like the IP address the operation was related to, the nature of the operation (was it a connect, a read... ?), the related buffer if it has any, etc. Similarly, when pushing new entries, we need to find a buffer that we have already registered and that is not currently in use, so we can use it and pass it to the kernel.
To get metadata from an integer, an efficient data structure is the hashmap which is available the Rust standard library, but since our rings have fixed size, it is even more efficient to use simple vectors, with the integer as the index. For the buffer allocator we also use vectors representing the indexes of free buffers, and simply push and pop at the end of it to respectively release buffers or allocate them. The use of vectors gives us a nice performance property: no costly dynamic memory allocation is ever done once the program is started.
Once our structure to track entry state is written, most of the work is done. When processing an IP, the program can allocate as many entries as it needs depending on the scan mode, and the memory will be guaranteed not to be reused and long as we process and release the related entry from the completion ring.
Scan modes
To make our scanner useful in realistic scenarios, we will support 3 different scan modes:
- TCP connect: does a full TCP handshake on a remote host, and report the IP addresses for which it succeeds
- SSH version: reads the SSH version reported by SSH servers, and match it against a user provided regular expression, reporting successful matches. This can be used for example to find servers running a vulnerable OpenSSH version, or still using the SSH 1 protocol.
- HTTP header: sends an HTTP request with optional custom headers, and match response headers against user provided regular expressions. This is a powerful tool that can be used to look for servers running a vulnerable software version, identify missing security headers, search specific cookie value, etc.
To separate the generic management of io_uring ring entries from the scan specific code, we write a Scan Rust trait, and implement it for each of of the 3 scan modes.
Performance comparison
Comparing the performance of a network scanner is notoriously difficult. Realistic usage depends on network conditions which are difficult to reproduce consistently.
We define two benchmarks, one is completely synthetic and therefore not representative of any realistic conditions, by scanning on the local 127.0.0.1/8 subnet. Since all IP are routed to 127.0.0.1, and the local TCP port we are scanning is closed, all connections will fail. The other benchmark is more realistic but slower and may not be 100% reproductible, by scanning a real subnet.
For the io_uring scanner we use our tcp-connect scan mode, which only does the TCP connect step, with no application data sent or received.
We compare the performance of our scanner with nmap, which is an established scanner, with many features and an emphasis on performance (see https://nmap.org/book/man-performance.html).
To set a fair comparison, we set some specific nmap options. By default nmap tries to avoid detection by slowing down the rate at which the network packets are sent while we want to send as fast as possible instead. It also provides scan modes to detect open TCP ports, by only sending the first SYN frame of the TCP handshake, but we want nmap to do a complete TCP connection instead. We also disable DNS resolution and host discovery.
The following nmap options are set:
- --min-hostgroup 65536: batch host processing, experiments seem to indicate that in our environment, this values gives the best performance when scanning many IPs
- --max-retries 0: do not retry failed connections
- --host-timeout 3s: timeout after 3 seconds for a host
- --max-scan-delay 0: do not enforce a limit on the total scan time
- -n: do not perform DNS resolution
- -Pn: consider host is online, and try to connect immediately
- -sT: perform a complete TCP connection using BSD sockets
The tests are run on a laptop with 8-core Intel Core i7-8665U CPU, with wired 1 Gb/s Ethernet connection, and WAN connectivity from a fast FFTH ISP. The benchmarks are run by the nmap-comparison script with nmap version 7.92. The script measures total scan run time ("wall" time) and CPU time, for increasingly large subnets, for both our io_uring scanner (shown as "ius" on the graphs) and nmap, and then plots the data using Gnuplot.
Synthetic scan on localhost :
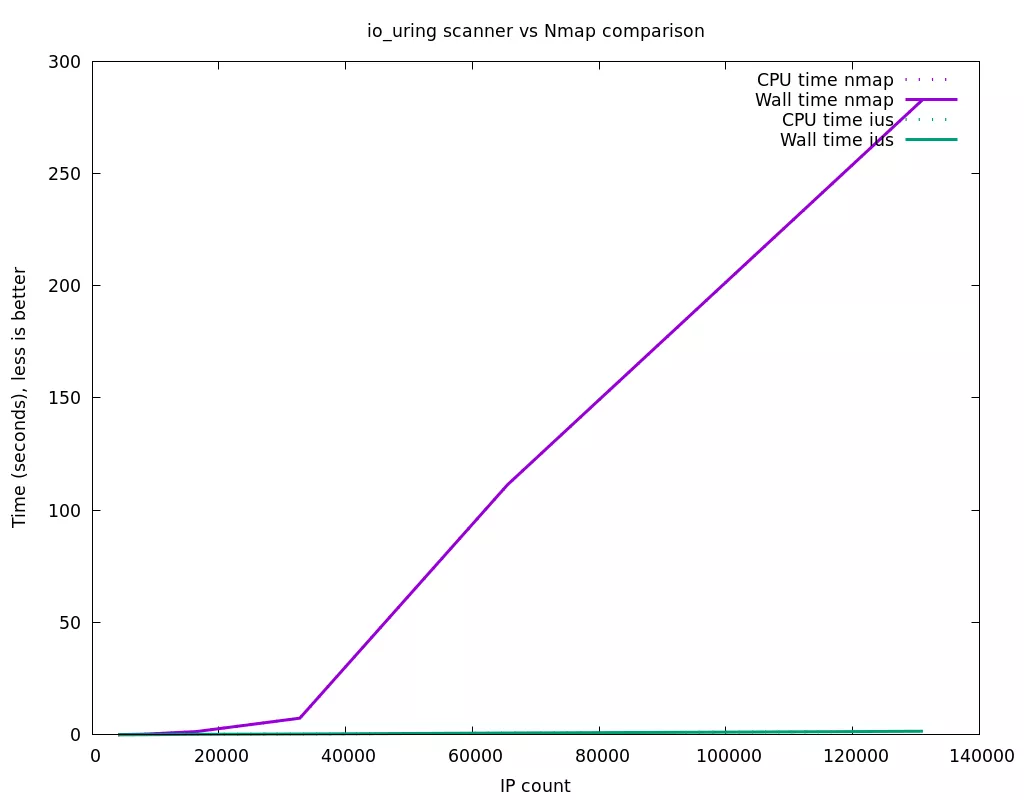
Realistic scan on remote IPs :
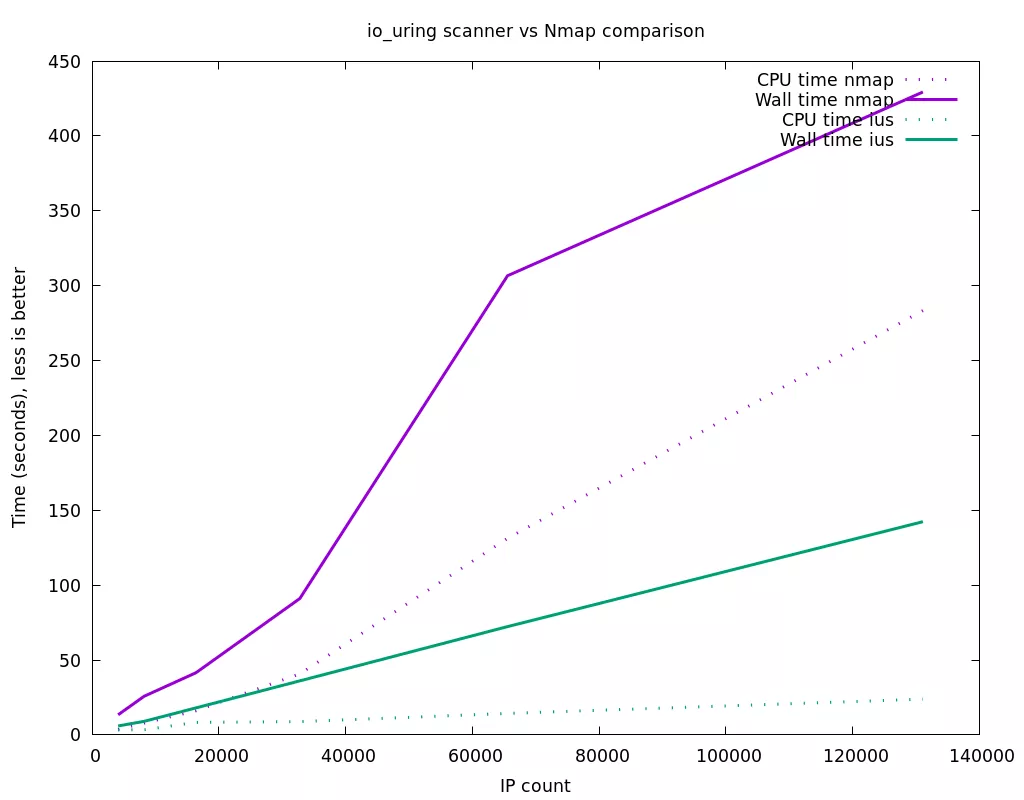
As we can see, for small number of IPs, the performance of the two scanners is very close. We suspect this is because the maximum io_uring ring size on our test system is 8192. Since a scan of each IP requires several entries for each operation (3 for the simple TCP connect scan: connect, connect timeout, close), the nmap scan can process more IP addresses simultaneously (65536 with the --min-hostgroup option we have set, compared to 8192/3=~2731 for the io_uring scanner). However when the IP address count increases, our io_uring based scanner is much more efficient than nmap in terms of CPU time per IP, which translates in a large performance difference. This can be explained both by the system call overhead that is completely absent with io_uring, and the buffer copies that are also be eliminated with the use of fixed buffers.
It is important to note that in the current scanner code, several areas of optimizations have not yet been explored. The most important being that currently a single thread does the maintenance of the io_uring rings, and the processing of the results, which for the HTTP header scan includes HTTP response header parsing, and regular expression matching. In our tests, the CPU usage of the io_uring scanner is low, and does not justify optimizing this. Unlike nmap, what slows down the overall io_uring based scan is the network response time (or timeouts), and not our actual scanner. However if the scanner was doing some intense processing per IP, they are easy ways we could make it more efficient :
- creating the sockets in a separate worker thread, and send them to the main thread using a bounded channel: this way a pool of sockets would always be ready to be used, avoiding the need to create them in the main thread
- doing the processing of the buffers, and associated scan specific regular expression matching in a pool of worker threads: combine with the previous point, this would effectively free the main thread for all work except for the rings maintenance, to do it as fast as possible
Conclusion
We have shown io_uring is a very promising API, usable via a convenient Rust API, and that can already provide very good performance in a real world program.
The scanner code is released under GPLv3 license at https://github.com/synacktiv/io_uring_scanner.