Grand saut dans le déploiement sur site d'un serveur LLM à moindres privilèges
En 1826, les enfants rêvaient de chevaucher à travers les grands espaces comme dans les romans d’aventure. En 1926, on s’imaginait en Arsène Lupin, maître du cambriolage. En 2026, gérer des serveurs d'inférence distribués sans fuiter l'intégralité des données de l'entreprise est sans nul doute un rêve universel pour la nouvelle génération. Cet article retrace notre parcours de déploiement d'un serveur LLM on-premise, avec un regard critique sur la sécurité de la stack sous-jacente.
Vous souhaitez améliorer vos compétences ? Découvrez nos sessions de formation ! En savoir plus
Introduction
Ce n'est plus un secret pour personne : les LLMs sont devenus, pour beaucoup d'entre nous, des outils à avoir dans sa boîte à outils.
Beaucoup de sociétés aimeraient exploiter leurs grandes capacités de traitement, tout en préservant un niveau strict de confidentialité pour leurs données métier.
Galvanisés par la hype mondiale et par un brin de curiosité, nous avons décidé de nous joindre à l'aventure.
Pourquoi un LLM « on-premise » ?
Si vous travaillez pour une entreprise soucieuse de la confidentialité de ses données, utiliser un LLM cloud n'est probablement pas une super option. Pour être absolument certain que vos secrets restent des secrets, mieux vaut le faire tourner chez soi.
Avoir un serveur LLM on-premise nous offre un contrôle total sur les mesures de protection des données, l'auditabilité, et offre le luxe appréciable de travailler avec de vraies données d'entreprise sans dépendre d'un tiers. Ce qui est un grand enjeu concernant la confiance de nos clients et la confidentialité de nos travaux de recherche et développement.

Objectifs et non-objectifs
Depuis le jour un du projet, l'infrastructure a été pensée avec des préoccupations de futur passage à l'échelle et d'isolation entre les différents tenants. Plusieurs équipes sont prêtes à investir dans des GPUs, même coûteux, car un LLM confidentiel représenterait un potentiel énorme gain de temps pour leur activité. Traduction de documents, relecture, analyse de logs, amélioration des outils, index hors-ligne de connaissances, analyse contextuelle de base de code — et autres cas d'usage.
La mission principale est de fournir des instances LLM complètement isolées du réseau (air-gapped) qui éliminent les risques d'exfiltration de données. L'isolation "en profondeur" des processus reste au demeurant une préoccupation majeure. En revanche, évoluer dans un environnement réseau contrôlé nous donne un peu plus de flexibilité concernant les compromis de sécurité que nous pourrions envisager.
Rome ne s'est pas construite en un jour, Claude Code non plus.
Cette première version se veut entièrement stateless (sans persistence) : pas de données en entrée, pas d'entraînement personnalisé, pas de pipeline RAG, pas d'agent, pas de connecteur. Un périmètre serré signifie une mise en production plus rapide, et une production rapide rend les développeurs heureux.
Par souci de clarté, cet article utilisera uniquement des données accessibles sur internet.
Dans un contexte de production, un registre interne serait naturellement la voie à suivre.
Quelques notions importantes
Si vous êtes familier avec les concepts et le vocabulaire de base des LLMs, vous pouvez passer directement à la section suivante.
La plupart des concepts suivants sont fondamentaux pour comprendre en profondeur comment fonctionne le traitement de texte par les LLMs, en revanche nous n'avons pas besoin d'une compréhension approfondie du sujet, une simple introduction suffira pour l'instant.
Tokens
Les modèles LLM traitent les corpus lexicaux par morceaux (grosso modo des mots ou fragments de mots) appelés "tokens". Convertir le texte d'entrée en tokens est l'une des premières étapes du pipeline d'inférence, appelée "tokenisation".
OpenAI fournit "tokenizer", un outil en ligne pour visualiser la tokenisation de texte par GPT.
Fichier modèle
Pour faire simple, un modèle est un gros fichier, principalement composé de nombres à virgule flottante générés pendant la "phase d'entraînement". Ce modèle est ensuite utilisé pour "deviner" statistiquement le prochain token en fonction de tous les tokens précédents. Ce processus s'appelle "l'inférence". Ces nombres (poids) sont stockés avec une quantification de précision à n bits.
Fenêtre de contexte
Le nombre total de tokens que le modèle peut prendre en compte pendant l'inférence.
Ce nombre diffère pour chaque modèle.
Par exemple, Mistral-Small-24B-Instruct-2501 a une longueur de contexte maximale de 32 768 tokens (environ 32k).
Cache KV
Afin de produire une inférence de qualité, chaque token doit être "calculé" en se basant sur tous les tokens précédemment générés.
Pour illustrer, supposons la séquence de tokens en entrée : "Tom est un super". Deviner le prochain token en se basant uniquement sur le token "super" est une mission désespérée, car il a une relation causale évidente avec "Tom" (sujet, probablement humain masculin), "est" (verbe, descriptif) et "un" (article indéfini, appartenance).
Le contexte compte, ce qui signifie que sans persistance de mémoire, tous les tokens précédents devraient être (re)calculés avant de générer les suivants. Cette opération a un impact dramatique sur les performances, qui empire à mesure que la taille du contexte augmente.
Avec une vision simplifiée des maths sous-jacentes, on peut considérer que — sans mécanisme de cache — le calcul d'une séquence de n tokens a une complexité quadratique 0(n²). Ce qui n'est vraisemblablement pas génial.
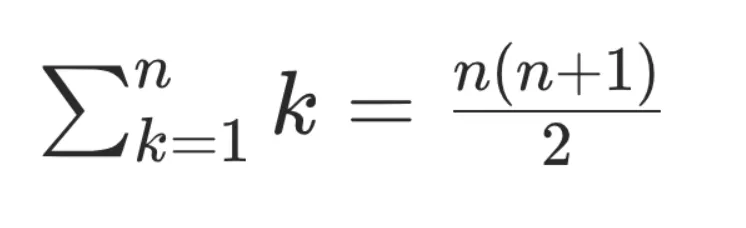
Avec un cache vectoriel, la valeur de chaque token n'est calculée qu'une seule fois puis stockée dans un kv store pour les inférences futures.
La complexité devient linéaire O(n), ce qui est nettement mieux.
Exemple : inférer "magicien" à partir de la séquence précédente ne coûterait que n lectures depuis le kv cache :
Tom → [0.12, -0.44, 1.03, ...]
est → [-0.31, 0.88, 0.02, ...]
un → [0.07, -0.12, 0.55, ...]
super → [1.21, 0.33, -0.91, ...]
Naturellement, les calculs son légèrement plus complexes que ça.
Mais cet exemple met en évidence l'importance de ce composant, et comment le sous-dimensionner pourrait sévèrement dégrader les performances de notre serveur.
La formule de taille du cache KV pour les modèles transformer (le standard actuel) à attention multi-tête est :

Ok assez de théorie, passons à la pratique !
Étape 1 : shopping matériel
Après une batterie de tests empiriques sur plusieurs modèles en conditions réelles de travail, gpt-oss-120b s'est avéré être le meilleur compromis performance-qualité pour nos cas d'usage. En quantification 4 bits, les fichiers de poids du modèle font environ 60 GiB (4bits x 120b paramètres) + métadonnées, ce qui représente une quantité massive de données à faire tenir dans la mémoire de notre GPU, et nécessitera sans aucun doute du matériel haut de gamme.
Comme aucune donnée d'entreprise n'est (pour l'instant) fournie au modèle via une base de données vectorielle, il était important de choisir un modèle avec une taille limite de contexte d'entrée conséquente — soit 131 072 tokens pour gpt-oss-120b.
Nous avons débuté notre recherche avec plusieurs critères en tête :
- Le modèle doit tenir dans la vRAM du GPU.
- Le cache kv du contexte doit tenir dans la vRAM du GPU, ou au minimum bénéficier d'un mécanisme de migration de pages mémoire haute performance.
- Nous avons un espace rack limité sur site, plus le format par GPU est compact, mieux ça sera.
- Chaque équipe doit avoir son GPU dédié.
Le GPU est, sans surprise, le composant matériel le plus important. Le premier critère à considérer est la taille de la vRAM (video RAM), la mémoire volatile intégrée au GPU, qui donne à l'unité de traitement un accès extrêmement rapide aux données une fois chargées. Trois choses doivent être en mémoire :
- Les poids du modèle
- Le cache kv de contexte
- Les buffers de calcul
Les poids estimés du modèle peuvent être obtenus en multipliant tous les tenseurs du modèle par leur précision associée :
import math
from gguf import GGUFReader
shards = (
"gpt-oss-120b-mxfp4-00001-of-00003.gguf",
"gpt-oss-120b-mxfp4-00002-of-00003.gguf",
"gpt-oss-120b-mxfp4-00003-of-00003.gguf",
)
n_parameters = 0
n_bytes = 0
for path in shards:
reader = GGUFReader(path)
for tensor in reader.tensors:
n_parameters += math.prod(tensor.shape)
n_bytes += tensor.data.nbytes
print(f"{n_parameters=:,}")
print(f"{n_bytes=:,}")
La valeur approximative pour les poids est ~60 GiB.
La fenêtre de contexte est une valeur fixe pour chaque modèle, pour gpt-oss-120b elle équivaut à 131 072 tokens (cf. métadonnées du modèle). Pour le cache kv, on applique simplement la formule du chapitre sur la théorie.
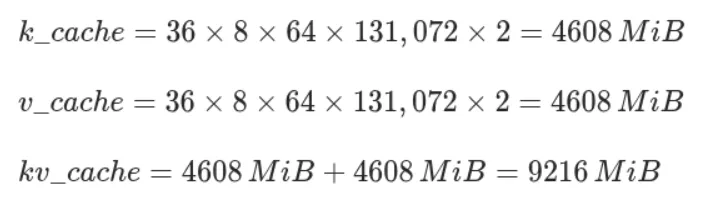
Le nombre d'octets par élément du cache KV est une valeur configurable, FP16 est considéré comme un bon compromis entre précision et utilisation mémoire.
Note : gpt-oss-120b est un "modèle hybride" dont la moitié des couches utilisent un mécanisme de Sliding Window Attention (model card - 2.2 Attention) en lieu et place de l'attention complète. En théorie, cette fonctionnalité pourrait réduire l'empreinte mémoire du cache kv jusqu'à 50%. Le support de cette fonctionnalité est partiellement implémenté par llama.cpp (#13194) mais il n'est pas encore tout à fait clair si elle est suffisamment mature pour interagir correctement avec le cache du prompt global. On a de ce fait décidé de l'ignorer dans un premier temps. Si à l'avenir on se retrouve un peu juste niveau mémoire, vLLM a sa propre implémentation (ref. Jenga paper).
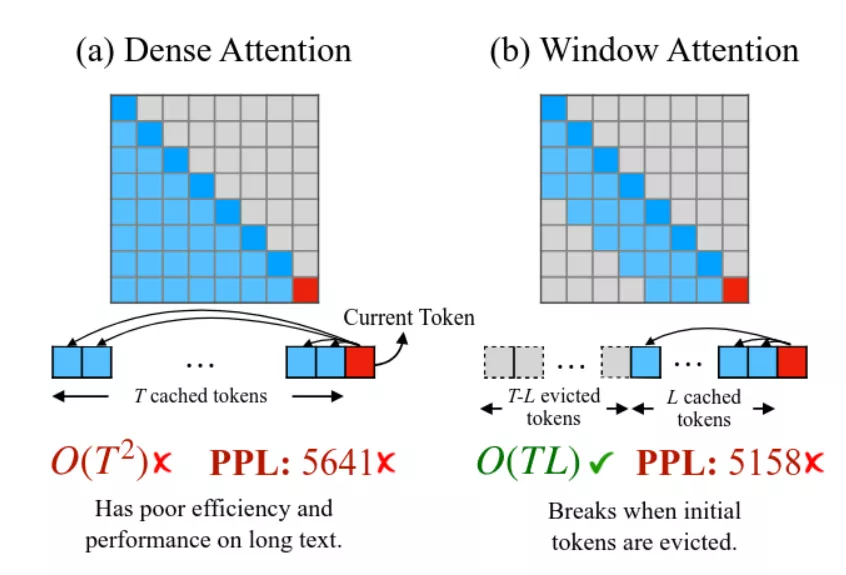
(source Efficient Streaming Language Models with Attention Sinks)
Tout ceci étant dit, on se retrouve avec une taille résidente en mémoire de ~70GiB.
Peu de GPUs sont capables de faire tenir autant de données en mémoire. La migration de pages reste une option de repli si elle s'avère utilisable. Un parti courant pour résoudre le manque de mémoire consiste à agréger la vRAM de plusieurs GPUs. C'est clairement une solution possible, mais pas vraiment commode du point de vue de l'administration système : plus d'espace physique consommé par instance de serveur LLM, attribution et administration du matériel fastidieuses, nécessite de hautes performances du bus PCI, etc.
Avec un prix public d'environ 9 000 € et une énorme capacité de 96 Go de vRAM, la Nvidia RTX Pro 6000 Max-Q Blackwell était sans conteste le matériel idéal pour notre cas d'usage. Cela signifie que l'on pourrait faire tenir le modèle complet et 4 slots de cache kv en parallèle (et ainsi éviter le partage de données de cache entre utilisateurs d'un même GPU).
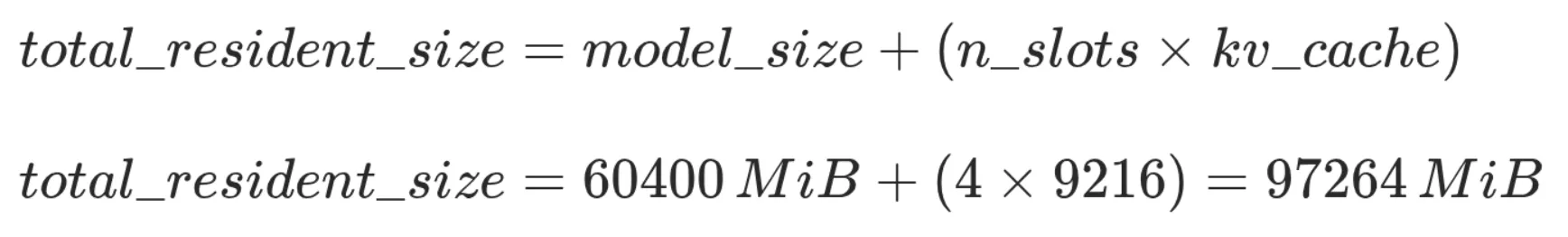
La taille mémoire exacte de la RTX Pro 6000 est de 97887 MiB. Naïvement, il semblerait que tout rentre parfaitement mais rappelez-vous que les valeurs ci-dessus sont des estimations, sans alignement de padding ni buffer transitoire additionnel.
% nvidia-smi -q -d MEMORY
Attached GPUs : 1
GPU 00000000:01:00.0
FB Memory Usage
Total : 97887 MiB
Reserved : 637 MiB
Used : 96084 MiB
Free : 1167 MiB
On peut soit accepter une fraction des données en RAM, soit réduire la taille de chaque contexte, avec une "marge de sécurité" arbitraire de 2 GiB. Réduire la taille de contexte à 126 000 tokens est plus que suffisant pour notre usage et satisfait l'ensemble de nos critères.
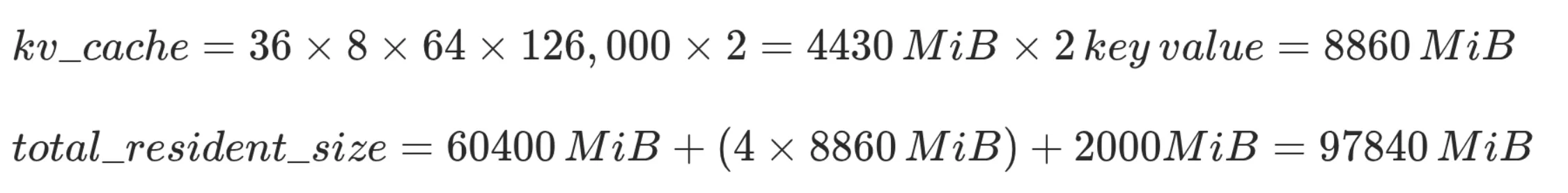
Le GPU étant élu, nous avons commandé un serveur GPU complet chez APY avec les spécifications suivantes :
- AMD EPYC 9224
- ASUS ESC4000A-E12 2U (4 slots GPU)
- 128 Go DDR5 ECC
- RTX Pro 6000 Blackwell Max-Q (1 pour qualification)

(source servers.asus.com)
Parfait, récapitulatif de la topologie finale :
- Réseau isolé → pas d'accès internet
- GPUs isolés → un par projet
- Contexte isolé en mémoire GPU → un par utilisateur
- Modèle partagé → un par GPU
Étape 2 : déploiement naïf
Lorsque l'on déploie de nouveaux services, on adopte généralement une approche itérative : déployer une première fois avec la configuration minimale pour avoir une vision globale des interactions entre composants. Ensuite, on examine chaque composant de plus près avec un œil plus averti, et on applique le durcissement approprié pour aboutir à une configuration à privilèges réduits.
Nous avons commencé avec la stack la plus simple possible :
- OS : debian 13 avec hardening approprié
- Serveur d'inférence :
llama.cpp - Modèle LLM :
gpt-oss-120b
Pour les besoins de l'article, le déploiement sera fait "à la main".
Bien entendu, tout cela est voué à être automatisé pour un déploiement fluide et sans pépin.
Drivers GPU
Nous avons maintenant en notre possession un GPU Nvidia, et le backend standard pour les GPUs Nvidia est CUDA.
Donc commençons par le commencement, installons les drivers Nvidia open-source en mode compute-only (réf. NVIDIA Driver Installation Guide) :
% apt install linux-headers-$(uname -r)
% export version="1.1-1"
% export repository="https://developer.download.nvidia.com/compute/cuda/repos/debian13/x86_64"
# Bien tenté nvidia, mais pour être honnête, on n'a pas vraiment envie d'installer
# un paquet pour configurer des sources apt.
% wget -O - "${repository}/cuda-keyring_${version}_all.deb" | dpkg -x /dev/stdin .
% install -m 0644 ./usr/share/keyrings/cuda-archive-keyring.gpg /usr/share/keyrings/
% install -m 0644 ./etc/apt/sources.list.d/cuda-debian13-x86_64.list /etc/apt/sources.list.d/
% apt update
% apt install nvidia-driver-cuda nvidia-kernel-open-dkms cuda-toolkit-13
# Le paquet "cuda-toolkit-13" installe la dépendance "nvidia-persistenced".
# Cet outil sert à réduire le démarrage à froid entre les chargements GPU, on n'en a pas besoin.
% vim /usr/lib/systemd/system-preset/nvidia.preset
disable nvidia-persistenced.service
% systemctl disable --now nvidia-persistenced.service
Maintenant on peut vérifier que notre GPU est détecté par CUDA :
% nvidia-smi -L
GPU 0: NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition (UUID: GPU-xxx-xxx)
llama.cpp
llama.cpp est un serveur d'inférence LLM batteries-included très populaire, à faible maintenance opérationnelle. Peu de dépendances, stack simple, gestion mémoire personnalisable, large support de différents types de modèles, bon potentiel d'intégration avec des outils externes. vLLM était également un sérieux candidat, mais c'est un choix plus opinioné, plus axé sur la haute performance que l'usage quotidien.
Commençons par télécharger tous les fichiers du modèle :
% export repository="https://huggingface.co/ggml-org/gpt-oss-120b-GGUF/resolve/main"
% install -dm 0755 /var/lib/models
% for i in {1..3}; do wget -P /var/lib/models \
"${repository}/gpt-oss-120b-mxfp4-0000${i}-of-00003.gguf"; done
Note : le serveur
llama.cppn'est pas disponible dans les dépôts debian.
Cependant, les performances s'améliorent significativement à chaque version, donc par la force des choses, ce sera de l'inférence bleeding-edge.
Ensuite, on doit compiler llama.cpp depuis les sources, avec le backend CUDA :
% apt install git cmake build-essential libssl-dev
% git clone --depth 1 https://github.com/ggml-org/llama.cpp
% cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_COMPILER=/usr/local/cuda-13/bin/nvcc ./llama.cpp
% cmake --build build [--parallel] --config Release
% ./build/bin/llama-cli --list-devices
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA RTX PRO 6000 Blackwell Server Edition, compute capability 12.0, VMM: yes
Available devices:
CUDA0: NVIDIA RTX PRO 6000 Blackwell Server Edition (97252 MiB, 96694 MiB free)
C'est l'heure du benchmark !
% ./build/bin/llama-bench --model /mnt/models/gpt-oss-120b-mxfp4-00001-of-00003.gguf -t 1 -fa 1 -b 2048 -ub 2048 -p 2048,8192,16384,32768,65536,131072 -ngl 99
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition, compute capability 12.0, VMM: yes
| model | size | params | backend | ngl | threads | n_ubatch | fa | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | --: | ------: | -------: | -: | --------------: | -------------------: |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | CUDA | 99 | 1 | 2048 | 1 | pp2048 | 8704.94 ± 20.84 |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | CUDA | 99 | 1 | 2048 | 1 | pp8192 | 8980.29 ± 10.49 |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | CUDA | 99 | 1 | 2048 | 1 | pp16384 | 8723.56 ± 13.68 |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | CUDA | 99 | 1 | 2048 | 1 | pp32768 | 8274.81 ± 65.17 |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | CUDA | 99 | 1 | 2048 | 1 | pp65536 | 7294.51 ± 10.20 |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | CUDA | 99 | 1 | 2048 | 1 | pp131072 | 5514.09 ± 5.41 |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | CUDA | 99 | 1 | 2048 | 1 | tg128 | 217.70 ± 0.55 |
build: ecd99d6 (1)
Ce sont globalement de très bons résultats étant donné que les benchmarks du 18 août 2025 (f08c4c0), il y a environ 6 mois, avec exactement le même matériel, rapportaient pratiquement moitié moins de t/s.
Bien, faisons de ce pas un peu d'inférence :
Assez simple finalement.
Étape 3 : orchestration et isolation
Faire tourner llama.cpp sur l'hôte fonctionne très bien. Néanmoins, on aimerait ajouter une couche d'isolation, surtout pour une topologie multi-GPU. Beaucoup de méthodes d'isolation existent. Nous sommes des ingénieurs modernes vivant dans un monde moderne qui place grande foi dans les conteneurs OCI pour l'isolation des processus et des utilisateurs.
Vous pensez peut-être avec indignation que les conteneurs ne sont pas les boites les mieux isolées du catalogue, d'autant qu'ils partagent entre eux les mêmes modules kernels. Des VMs avec GPU passthrough seraient probablement plus appropriées point de vue isolation, mais elles ont aussi leurs inconvénients : performances dégradées, orchestration non triviale, procédures de mise à jour fastidieuses. On évoquait plus tôt de petits compromis de sécurité, et celui-ci en est un. Un réseau isolé et du code de driver open-source auditable, c'est un compromis que nous sommes disposés à accepter !
Podman est un excellent outil pour gérer des conteneurs car il supporte nativement le mode rootless.
Et ce qui est également formidable avec podman, c'est qu'il supporte nativement une spécification assez commode de mapping de périphériques appelée "CDI" (Container Device Interface).
Qu'est-ce que les CDI ?
CDI est une extension de la spécification OCI intégrée pour les périphériques, fournie par le CNCF, supportée depuis podman v3.2.0.
Tout fichier présent dans /run/cdi ou /var/run/cdi sera chargé par les gestionnaires de conteneurs compatibles CDI et sera injecté dans l'appel au runtime du conteneur (conformément à la spécification OCI runtime-spec).
La spécification complète des champs CDI est disponible dans le dépôt cncf-tags/container-device-interface (réf. SPEC.md)
Par chance, nvidia a eu la grâce de fournir un outillage très complet pour les conteneurs, avec notamment la génération de fichiers CDI (ref. NVIDIA/nvidia-container-toolkit).
Sur les systèmes debian, tout cela est livré par le paquet nvidia-container-toolkit.
# nvidia-container-toolkit-base est une dépendance de nvidia-container-toolkit
# qui fournit la majorité de l'outillage.
# Certains éléments ont été retirés pour la lisibilité.
% dpkg -L nvidia-container-toolkit-base
/etc/systemd/system/nvidia-cdi-refresh.service
/usr/bin/nvidia-cdi-hook
/usr/bin/nvidia-container-runtime
/usr/bin/nvidia-ctk
Le paquet fournit 3 binaires :
nvidia-cdi-hook: gère les fichiers et liens symboliques à l'intérieur du conteneur.nvidia-container-runtime: wrapper autour du runtime de conteneur pour monter les périphériques. Nous n'en avons pas besoin car on va exploiter les capacités CDI intégrées dans podman.nvidia-ctk: usages variés, y compris la génération de fichiers CDI.
Et un service systemd nvidia-cdi-refresh.service qui maintient les fichiers CDI à jour.
; systemctl cat nvidia-cdi-refresh.service
; Certains éléments ont été retirés pour la lisibilité.
[Unit]
Description=Refresh NVIDIA CDI specification file
ConditionPathExists=|/usr/bin/nvidia-smi
ConditionPathExists=|/usr/sbin/nvidia-smi
ConditionPathExists=/usr/bin/nvidia-ctk
[Service]
ExecStart=/usr/bin/nvidia-ctk cdi generate
CapabilityBoundingSet=CAP_SYS_MODULE CAP_SYS_ADMIN CAP_MKNOD
Au démarrage du service, la commande nvidia-ctk cdi generate s'exécute et — sans surprise — génère le fichier CDI basé sur le matériel à disposition sur l'hôte.
# /run/cdi/nvidia.yaml
# Certains éléments ont été retirés pour la lisibilité.
---
cdiVersion: 0.5.0
# Identifiant de périphérique vendor et class
kind: nvidia.com/gpu
# Périphériques disponibles pour le gestionnaire de conteneurs
# Ex. podman run --device nvidia.com/gpu=0
devices:
- name: "0"
containerEdits:
# Périphériques liés à l'intérieur du conteneur
deviceNodes:
- path: /dev/nvidia0
- name: all
containerEdits:
deviceNodes:
- path: /dev/nvidia0
- path: /dev/nvidia1
# Configuration partagée entre tous les périphériques ci-dessus
containerEdits:
env:
- NVIDIA_CTK_LIBCUDA_DIR=/usr/lib/x86_64-linux-gnu
deviceNodes:
- path: /dev/nvidia-uvm
- path: /dev/nvidia-uvm-tools
- path: /dev/nvidiactl
hooks:
- hookName: createContainer
path: /usr/bin/nvidia-cdi-hook
args:
- nvidia-cdi-hook
- create-symlinks
- --link
- ../libnvidia-allocator.so.1::/usr/lib/x86_64-linux-gnu/gbm/nvidia-drm_gbm.so
- --link
- libglxserver_nvidia.so.590.48.01::/usr/lib/xorg/modules/extensions/libglxserver_nvidia.so
env:
- NVIDIA_CTK_DEBUG=false
# Bind mounts entre l'hôte et le conteneur
mounts:
- hostPath: /usr/bin/nvidia-cuda-mps-control
containerPath: /usr/bin/nvidia-cuda-mps-control
options:
- ro
- nosuid
- nodev
- rbind
- rprivate
Les fichiers CDI sont quasi exclusivement utilisés par Nvidia pour monter des GPUs dans les conteneurs.
Le support CDI de Podman a même été implémenté par un employé de chez Nvidia (réf. #10081).
Configuration de Podman
Podman fournit une documentation dédiée à la configuration en mode rootless, par 3 grandes étapes :
1. Installer podman
Le runtime runc, développé par l'Open Container Initiative, est un standard dans l'écosystème des conteneurs.
% apt install --no-install-recommends podman runc
% vim /etc/containers/storage.conf
[storage]
driver = "overlay"
[storage.options.overlay]
ignore_chown_errors = "true"
% vim /etc/containers/containers.conf
[engine]
runtime = "/usr/sbin/runc"
% vim /etc/modules-load.d/overlay.conf
overlay
% useradd \
--uid 10000 \
--create-home \
--home-dir /var/lib/containers/container01 \
--shell /usr/sbin/nologin \
--password '!' \
container01
Note : à partir de maintenant, considérez que toutes les commandes podman sont exécutées en tant qu'utilisateur système "container01".
2. Configuration réseau
A user-mode networking tool for unprivileged network namespaces must be installed on the machine in order for Podman to run in a rootless environment.
Ce n'est pas tout à fait vrai. Un driver réseau en mode utilisateur doit être installé si l'on a besoin de réseau, comme bind un port par exemple. Bonne nouvelle pour nous, le serveur llama.cpp peut écouter sur un socket UNIX. Cela signifie que nous n'avons pas besoin d'une pile réseau TCP/IP dans notre conteneur, c'est donc un gain très appréciable en performances et en sécurité.
Pour que tout cela fonctionne, nous avons juste besoin de lancer la commande podman avec le flag --network=none (ou netns=none dans containers.conf).
% podman run hello-world
Error: could not find pasta, the network namespace can't be configured: exec: "pasta": executable file not found in $PATH
% podman run --network=none hello-world
!... Hello Podman World ...!
.--"--.
/ - - \
/ (O) (O) \
~~~| -=(,Y,)=- |
.---. /` \ |~~
~/ o o \~~~~.----. ~~
| =(X)= |~ / (O (O) \
~~~~~~~ ~| =(Y_)=- |
~~~~ ~~~| U |~~
3. Configuration du mapping subuid/subgid
Rootless Podman requires the user running it to have a range of UIDs listed in the files /etc/subuid and /etc/subgid
Ce n'est pas tout à fait vrai non plus. Mapper votre utilisateur courant avec l'utilisateur root du conteneur 1:1 ne nécessiterait pas forcément de plage uid ou gid supplémentaire.
Par défaut, l'utilisateur root à l'intérieur d'un conteneur sera mappé sur l'utilisateur qui a démarré le conteneur sur l'hôte (en supposant --userns=host), donc si on utilise par ex. des volumes, les processus du conteneur pourront accéder à n'importe quel fichier avec les mêmes droits système que l'utilisateur hôte. C'est déjà mieux que le mode "rootful" par défaut de Docker, où l'utilisateur root dans le conteneur est le vrai utilisateur root sur l'hôte (pas de namespacing utilisateur). Toute faille de sécurité dans l'isolation du système de fichiers ou des processus serait un risque énorme d'escalade de privilèges.
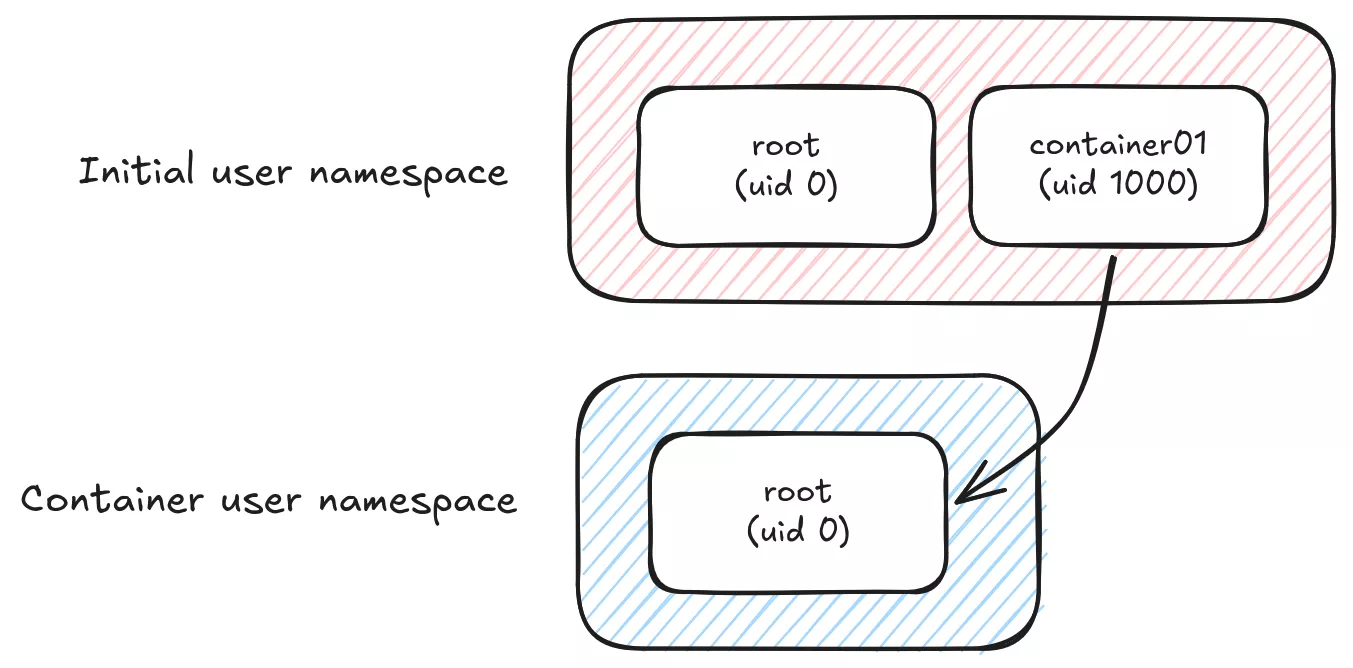
D'un point de vue sécurité, on préférerait probablement mapper l'utilisateur du conteneur vers un UID élevé non privilégié sur l'hôte.
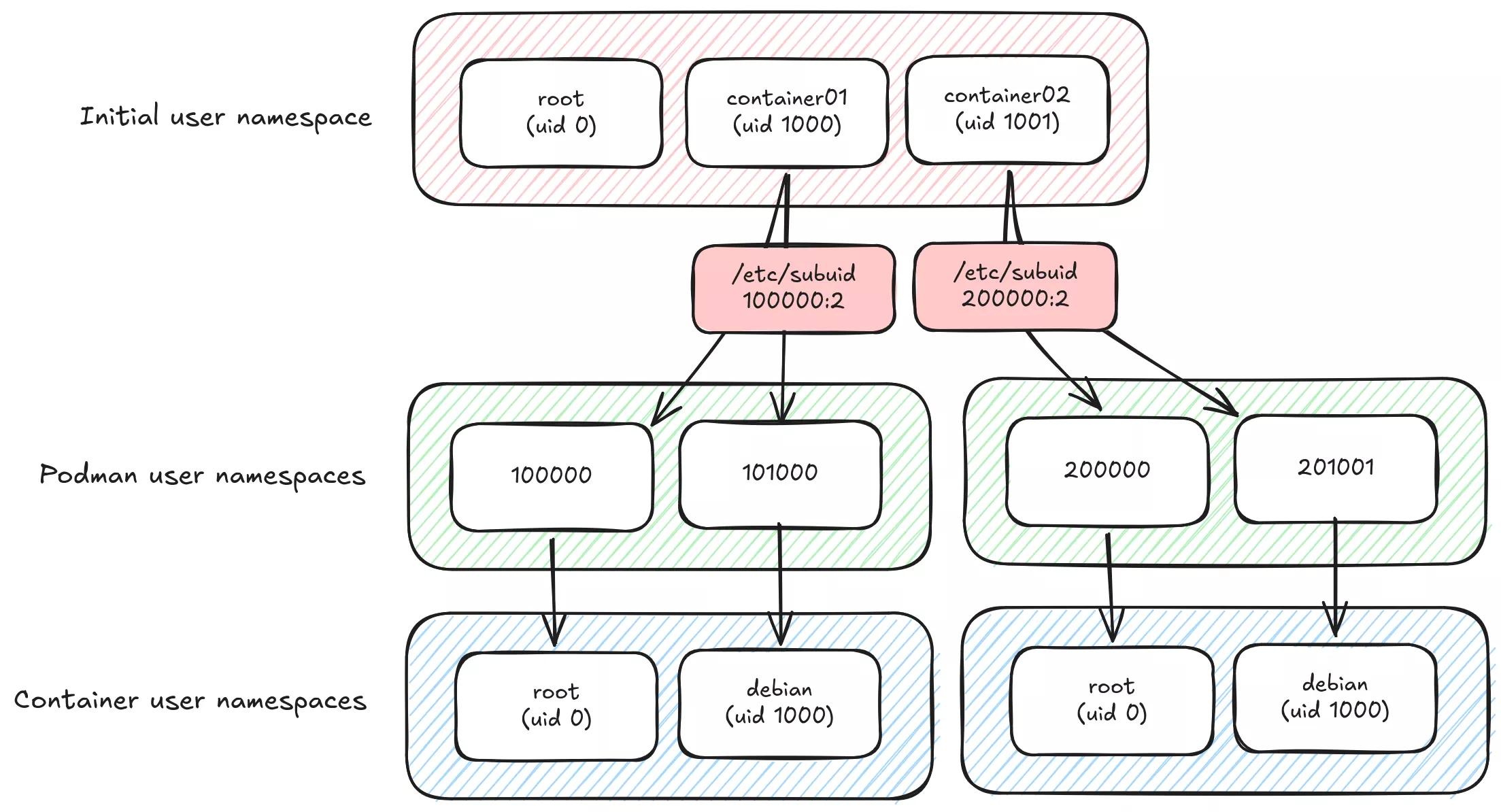
Le processus principal llama.cpp à l'intérieur du conteneur podman tourne en tant qu'utilisateur debian (1000:1000) et sur l'hôte en tant qu'uid 101000. Il n'est pas root dans le conteneur, et n'a même pas les droits de l'utilisateur container01 sur l'hôte, ce qui rend l'escalade de privilèges nettement plus difficile.
Si les home de vos utilisateurs sont gérés par
systemd-homed, les plages subuid doivent commencer à 524288 pour éviter les collisions (réf. rootless containers)
% apt install uidmap
# Ajouter la plage subid pour l'utilisateur container01
% usermod \
--add-subuids 100000-101000 \
--add-subgids 100000-101000 \
container01
# Désactiver le provisionnement automatique de subuid à la création de nouveaux utilisateurs.
grep 'SUB_.ID_COUNT' /etc/login.defs
SUB_UID_COUNT 0
SUB_GID_COUNT 0
% podman run --detach --rm --userns=keep-id --user 1000:1000 debian:trixie tail -f /etc/hosts
% ps -ef | grep tail
UID PID PPID C STIME TTY TIME CMD
101000 167172 167169 0 Mar11 pts/0 00:00:00 bash
% lsns --type user --tree
NS TYPE NPROCS PID USER COMMAND
4026531837 user 423 1 root /sbin/init
└─4026532736 user 6 167141 container01 podman run --detach --rm --userns=keep-id --user 1000:1000 debian:trixie
└─4026534507 user 1 167172 101000 tail -f /etc/hosts
Configuration du reverse proxy
Rappelez-vous que le serveur llama.cpp écoute sur un fichier socket UNIX. Les sockets UNIX sont commodes pour deux raisons : aucune configuration réseau n'est nécessaire, et ils s'appuient sur les droits POSIX du système de fichiers (DACLs ou FACLs) pour fournir un contrôle d'accès clé en main à l'API sous-jacente.
Afin d'exposer la WebUI aux utilisateurs distants, on a besoin d'une forme de reverse proxy. Beaucoup de choix sont disponibles, on va partir sur un bon vieux serveur nginx — bien que l'on aurait pu simplement utiliser l'intégration native de proxy socket par systemd systemd-socket-proxyd(8).
L'écosystème Linux offre un large éventail de solutions de durcissement des processus. Ce sujet sort du périmètre de l'étude, de la documentation de qualité est disponible un peu partout sur internet :
- Systemd sandboxing (wiki.archlinux.org)
- Service sandboxing (wiki.debian.org)
- Systemd hardening made easy with SHH (synacktiv.com)
- apparmor(7), landlock(7), chroot(1), pivot_root(8), unshare(1), limits.conf(5)
Un fichier de configuration pour commencer à expérimenter pourrait être aussi simple que :
map "$request_method:$uri" "$whitelist" {
default 0;
"GET:/" 1;
"GET:/health" 1;
"GET:/v1/health" 1;
"GET:/props" 1;
"GET:/models" 1;
"GET:/v1/models" 1;
"POST:/completions" 1;
"POST:/v1/completions" 1;
"POST:/chat/completions" 1;
"POST:/v1/chat/completions" 1;
"POST:/v1/messages" 1;
}
upstream container01 {
server unix:/var/lib/containers/container01/socks/llama-cpp.sock;
}
server {
listen 127.0.0.1:80;
location / {
if ($whitelist = 0) {
return 403;
}
proxy_pass http://container01;
}
}
Seules les routes API nécessaires sont whitelistées via la map nginx. La postérité se souviendra de la route API /slots qui fournissait de but en blanc tous les prompts des autres utilisateurs, jusqu'à ce qu'il soit "rendu sécurisé" (cf. 0d161f0).
$ podman run -e LLAMA_SERVER_SLOTS_DEBUG=1 ghcr.io/ggml-org/llama.cpp:server-cuda13 --jinja [...]
$ curl http://localhost:8080/slots | jq -r '.[].prompt'
<|start|>system<|message|>You are Kevin Flynn<|end|>
<|start|>user<|message|>
Analyze this code for vulnerabilities
--- File: cve-2002-0639 ---
nresp = packet_get_int();
if (nresp > 0) {
response = xmalloc(nresp*sizeof(char*));
for (i = 0; i < nresp; i++)
response[i] = packet_get_string(NULL);
}
<|end|>
Afin de renforcer la sécurité d'accès, on s'appuie sur l'authentification ssh plutôt que d'exposer un port sur le réseau interne.
C'est pour cette raison que le serveur écoute sur 127.0.0.1 et non pas sur son IP d'interco standard.
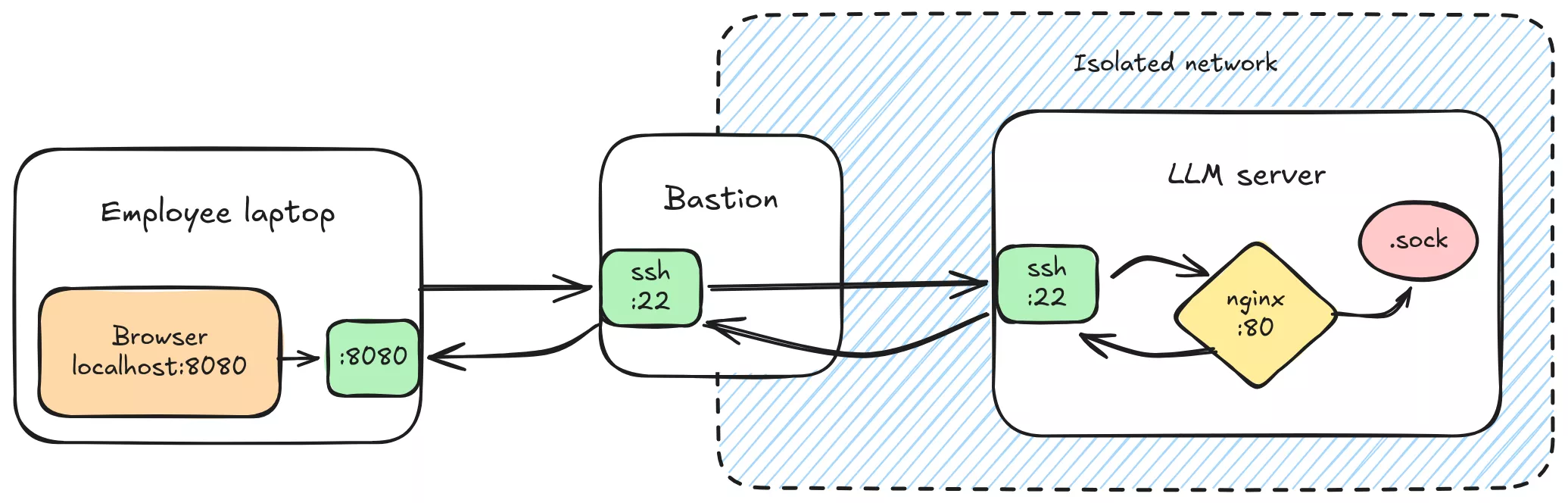
# Forward du port 80 du serveur nginx vers le port 8080 de la machine locale
% ssh -J bastion.local -NL 8080:127.0.0.1:80 server.local
Lancer llama.cpp
Tout est prêt. L'ensemble des options du serveur llama.cpp sont documentées sur le wiki du projet.
La commande finale ressemblerait à quelque chose comme ça :
# Notez que l'on doit forcer le mode de création du socket à 770
# pour conserver les droits d'accès appropriés
% podman run --rm --network none --detach \
--user=1000:1000 \
--userns=keep-id \
--umask=007 \
--device nvidia.com/gpu=0 \
--volume /var/lib/models:/models:ro \
--volume /var/lib/containers/container01/socks:/run/llama-cpp \
ghcr.io/ggml-org/llama.cpp:server-cuda13 \
--host /run/llama-cpp/llama-cpp.sock \
--model /models/gpt-oss-120b-mxfp4-00001-of-00003.gguf \
--alias gpt-oss-120b \
--ctx-size 504000 \ # 126 000 tokens x 4 slots
--parallel 4 \ # 4 slots (implique --no-kv-unified)
--no-slots \ # Désactiver le monitoring de slots
--swa-full # Désactiver le cache SWA réduit
23ed38fddcd8
% podman logs -f 23ed38fddcd8
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition, compute capability 12.0, VMM: yes
[...]
main: server is listening on unix:///run/llama-cpp/llama-cpp.sock
Démarrage du conteneur
L'étape suivante consiste à faire démarrer et à configurer automatiquement les conteneurs au démarrage système.
Parmi toutes les solutions disponibles, on a opté pour les quadlets podman.
Les quadlets sont une version étendue des services systemd, conçue spécialement pour la gestion du cycle de vie des conteneurs (réf. podman-systemd.unit)
Ils offrent de nombreuses abstractions telles que .container, .network, .image, ...
Basés sur les générateurs systemd, tout fichier de définition déclenchera le provisionnement sous-jacent d'un véritable service systemd.
Pour l'utilisateur container01 avec uid=10000,gid=10000, la commande podman précédente convertie au format quadlet donnerait :
; /etc/containers/systemd/users/10000/llama-cpp.container
[Unit]
Description=llama.cpp CUDA server
[Container]
Image=ghcr.io/ggml-org/llama.cpp:server-cuda13
AutoUpdate=disabled
AddDevice=nvidia.com/gpu=0
Network=none
Volume=/var/lib/models:/models:ro
Volume=/var/lib/containers/container01/socks:/run/llama-cpp
; Commande de healthcheck simple
HealthStartPeriod=1m
HealthCmd=/usr/bin/test -S /run/llama-cpp/llama-cpp.sock
User=1000
Group=1000
UserNS=keep-id
NoNewPrivileges=true
; Forcer le mode de création du socket
PodmanArgs=--umask=007
Exec=\
--host "/run/llama-cpp/llama-cpp.sock" \
--model /models/gpt-oss-120b-mxfp4-00001-of-00003.gguf \
--alias gpt-oss-120b \
--ctx-size 504000 \
--parallel 4 \
--no-slots \
--swa-full
[Quadlet]
DefaultDependencies=false
[Service]
Restart=on-failure
[Install]
WantedBy=default.target
Activer le linger mode déclenchera les générateurs systemd pour l'utilisateur container01 et, espérons-le, démarrera notre serveur LLM conteneurisé.
% loginctl enable-linger container01
% pstree -SctuZ
systemd(`unconfined')
├─nginx(mnt,uts,`nginx (enforce)')
│ ├─nginx(www-data,`nginx (enforce)')
│ ├─nginx(www-data,`nginx (enforce)')
│ └─nginx(www-data,`nginx (enforce)')
└─systemd(container01,mnt,`sd-pam (enforce)')
├─conmon(mnt,user,`podman (enforce)')
│ └─llama-server(cgroup,ipc,mnt,net,pid,uts,`container (enforce)')
│ ├─{cuda-EvtHandlr}(`container (enforce)')
│ ├─{cuda00001400006}(`container (enforce)')
│ ├─{llama-server}(`container (enforce)')
│ ├─[...]
│ └─{llama-server}(`container (enforce)')
└─podman pause(mnt,user,`container (enforce)')
% cat /run/user/10000/systemd/generator/llama-cpp.service
# Cette commande affiche le service systemd généré pour l'utilisateur 10000
# basé sur les fichiers de configuration podman et quadlet fournis.
Étape 4 : améliorations
Il semblerait que notre déploiement "standard" de serveur LLM embarque tout un tas de dépendances, dont nous aimerions certainement nous passer.
De ce fait, il conviendrait de prendre un peu de recul sur l'utilité de chacun des composants afin de réduire au mieux la surface d'attaque globale.
Creusons un peu.
Modules kernel
D'abord, un tour de magie :
% lsmod | grep nvidia
nvidia 16248832 6 nvidia_modeset
% ./build/bin/llama-cli --list-devices
[...]
% lsmod | grep nvidia
nvidia_uvm 2048000 0
nvidia 16248832 7 nvidia_uvm
Surprise, nouveau module kernel !
Comme prévu, chaque module est parfaitement bien documenté en ligne, n'est-ce pas nvidia ?
Non. Rien du tout.
Vous pensez peut-être que l'on pourrait "deviner" en se basant sur leur nom, ce qui est une bonne remarque mais pas spécialement une approche très rigoureuse.
% man nvidia-
nvidia-cuda-mps-control nvidia-cuda-mps-server nvidia-modprobe nvidia-persistenced nvidia-smi
# Le mieux que l'on ait serait nvidia-modprobe
% man nvidia-modprobe
NAME
nvidia-modprobe - Load the NVIDIA kernel module and create NVIDIA character device files.
% tree /usr/share/doc/nvidia-*
/usr/share/doc/nvidia-driver-cuda
├── changelog.Debian.gz
├── changelog.gz
└── copyright
/usr/share/doc/nvidia-kernel-open-dkms
├── changelog.Debian.gz
└── copyright
/usr/share/doc/nvidia-kernel-support
├── changelog.Debian.gz
├── changelog.gz
└── copyright
/usr/share/doc/nvidia-modprobe
├── changelog.Debian.gz
└── copyright
/usr/share/doc/nvidia-opencl-icd
├── changelog.Debian.gz
├── changelog.gz
└── copyright
/usr/share/doc/nvidia-persistenced
├── changelog.Debian.gz
└── copyright

Eh bien figurez-vous, après un peu d'archéologie de paquets, que la documentation n'est livrée qu'avec le paquet desktop nvidia-driver.
Sacré Nvidia !
% apt download nvidia-driver
% dpkg --contents nvidia-driver*
-rw-r--r-- root/root 10530 2025-12-08 12:36 ./usr/share/doc/nvidia-driver/html/index.html
[...]
Très bien, maintenant on a un chapitre Chapter 5. Listing of Installed Components qui nous fournit toutes les informations pertinentes.
nvidia.ko: fournit un accès bas niveau à votre matériel Nvidia.nvidia-modeset.ko: responsable de la configuration du moteur d'affichage du GPU.nvidia-peermem.ko: permet aux HCA Mellanox d'accéder aux buffers de lecture/écriture de la mémoire GPU sans avoir à copier les données dans la mémoire hôte. (i.e. au lieu du RDMA via une interco de type infiniband)nvidia-uvm.ko: module kernel Unified Memory ; ce module fournit la fonctionnalité de partage de mémoire entre le CPU et le GPU dans les programmes CUDA. Il est généralement chargé dans le kernel au démarrage d'un programme CUDA, et est utilisé par le driver CUDA sur les plateformes supportées.
Chapter 36. Direct Rendering Manager Kernel Modesetting (DRM KMS)
nvidia-drm.ko : enregistre un driver DRM auprès du sous-système DRM du kernel Linux. Crée les périphériques dri /dev/dri/card* et /dev/dri/renderD* (voir docs.kernel.org, wikipedia).
Récapitulons :
nvidia.ko(requis) : module principalnvidia-modeset.ko(inutile) : on n'a pas besoin du moteur d'affichagenvidia-peermem.ko(inutile) : on n'a pas besoin de RDMAnvidia-uvm.ko(peut-être) : on n'a pas besoin de Unified Memory puisqu'on a assez de vRAM pour faire tenir l'intégralité des données du LLM. Mais peut-être quellama.cppl'utilise, on verra ça plus tardnvidia-drm.ko(inutile) : CUDA utilise les périphériques/dev/nvidia*, pas les périphériques dri
En poursuivant avec notre approche itérative, nous allons maintenant investiguer quels modules sont essentiels au bon fonctionnement de CUDA, puis nous bloquerons le reste.
# Désactiver le chargement de modules kernel est une mesure de sécurité capitale sur les serveurs de production.
# Charger des modules est l'un des moyens préférés des attaquants pour compromettre un système
# et élever ses privilèges. Voir sysctl.d(5)
% echo 1 > /proc/sys/kernel/modules_disabled
% lsmod | grep nvidia
nvidia 16248832 0
% ./build/bin/llama-cli --list-devices
ggml_cuda_init: failed to initialize CUDA: unknown error
Available devices:
% strace -f -e execve ./build/bin/llama-cli --list-devices 2>&1
execve("./build/bin/llama-cli", ["./build/bin/llama-cli", "--list-devices"], 0x7ffec8576210 /* 19 vars */) = 0
[pid 42346] execve("/sbin/modprobe", ["modprobe", "nvidia-uvm"], 0x7f95e382e870 /* 1 var */) = 0
ggml_cuda_init: failed to initialize CUDA: unknown error
Available devices:
CUDA essaie de charger opportunistement un module kernel dans notre dos.
Pas cool nvidia !
% lsmod | grep nvidia
nvidia_uvm 2048000 0
nvidia 16248832 7 nvidia_uvm
% ./build/bin/llama-cli --list-devices
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA RTX PRO 6000 Blackwell Server Edition, compute capability 12.0, VMM: yes
Available devices:
CUDA0: NVIDIA RTX PRO 6000 Blackwell Server Edition (97252 MiB, 96694 MiB free)
Jusqu'ici tout se présente bien, on a notre setup driver minimal.
La commande strace nous donne 3 informations :
openat(AT_FDCWD, "/dev/nvidiactl", O_RDWR|O_CLOEXEC)
openat(AT_FDCWD, "/dev/nvidia0", O_RDWR|O_CLOEXEC)
openat(AT_FDCWD, "/dev/nvidia-uvm", O_RDWR|O_CLOEXEC)
- CUDA utilise
nvidiactl(au minimum) pour énumérer les périphériques. - CUDA utilise le nœud de périphérique
/dev/nvidia*pour interagir avec les GPUs. - CUDA utilise le nœud de périphérique
/dev/nvidia-uvm, certainement pour une bonne raison.
Le problème du module nvidia-uvm
Unified Virtual Memory est un système de gestion mémoire développé par Nvidia, basé sur la migration dynamique de pages, pour créer un espace mémoire "unifié" entre la RAM CPU et la vRAM GPU. En déchargeant la mémoire GPU en RAM, les programmes peuvent calculer des jeux de données plus volumineux que la capacité de la vRAM sans trop de dégradation de performance.
C'est sans aucun doute une cible de premier choix pour un attaquant cherchant à se procurer des données confidentielles.
Pour nous, cette fonctionnalité semble naïvement parfaitement inutile puisque l'on fait tenir l'intégralité de la charge dans la vRAM. Donc pas besoin de migration de pages, pas vrai ?
Dans le code CUDA, l'utilisation d'uvm est assez explicite : l'appel de fonction cudaMalloc() est remplacé par cudaMallocManaged() pour demander explicitement de la mémoire managée au moteur CUDA.
Coup de chance, llama.cpp n'utilise pas uvm par défaut, et n'appelle cudaMallocManaged() que si la variable GGML_CUDA_ENABLE_UNIFIED_MEMORY est exportée. Problème résolu, non ?
Malheureusement, d'après quelques personnes parfaitement anonymes sur de sombres forums dans les fins fonds d'internet, CUDA dépend d'uvm depuis la version 6 ou 7 ou 8 (toujours extensivement non-documenté par Nvidia), même si ce n'est jamais appelé explicitement dans le code. L'initialisation du runtime CUDA lance un processus enfant pour charger nvidia_uvm au lieu de tourner en mode dégradé. Il semblerait que le runtime exige inconditionnellement que nvidia_uvm soit présent, même pour des charges de travail non-UVM.
En se basant sur le code du module kernel open, on peut supposer que CUDA s'appuie sur ce module non seulement pour la mémoire unifiée, mais également pour l'ensemble de sa gestion d'espace mémoire virtuel (VUA), la gestion des faults GPU et l'éviction mémoire.

Périphériques système
Par défaut, les nœuds de périphériques GPU sont lisibles et inscriptibles par tout le monde :
% ls -l /dev/nvidia0
crw-rw-rw- 1 root root 195, 0 Feb 26 14:30 /dev/nvidia0
Pas de panique au demeurant, cela ne signifie pas pour autant que tout le monde peut lire l'intégralité de la mémoire de notre GPU. Les périphériques sont un type spécial de fichiers qui réimplémentent toutes les opérations standard sur fichiers telles que open(), write(), et gèrent les appels ioctl() comme ils le souhaitent.
Concernant les nœuds de périphériques nvidia*, ils gèrent une table d'allocation mémoire dynamique dans la vRAM GPU.
Deux problèmes :
- Toute faille dans l'implémentation de ce périphérique mènerait à une compromission globale de la mémoire GPU.
- Tout le monde peut écrire des données dans le GPU, et on ne veut pas partager la mémoire avec d'autres processus.
Voyons si le module kernel nvidia a quelques chouettes options à nous proposer :
% modinfo nvidia
[...]
parm: NVreg_DeviceFileUID:int
parm: NVreg_DeviceFileGID:int
parm: NVreg_DeviceFileMode:int
Parfait, on peut donc appliquer quelques restrictions un peu plus convenables :
# Restreindre l'accès aux périphériques à root
% vim /etc/modprobe.d/nvidia-devices.conf
options nvidia NVreg_DeviceFileUID=0
options nvidia NVreg_DeviceFileGID=0
options nvidia NVreg_DeviceFileMode=0660
# Blacklister les modules inutiles
% vim /etc/modprobe.d/nvidia-blacklist.conf
blacklist nvidia_drm
blacklist nvidia_modeset
blacklist nvidia_peermem
# Charger automatiquement les modules nvidia au boot système
% vim /etc/modules-load.d/nvidia.conf
nvidia
nvidia_uvm
% update-initramfs -u
% systemctl reboot
% lsmod | grep nvidia
nvidia_uvm 2048000 4
nvidia 16273408 40 nvidia_uvm
% ls -l /dev/nvidia*
crw-rw---- 1 root root 195, 0 Feb 26 14:32 /dev/nvidia0
crw-rw---- 1 root root 195, 255 Feb 9 14:26 /dev/nvidiactl
crw-rw-rw- 1 root root 236, 0 Feb 9 14:26 /dev/nvidia-uvm
nvidia-uvm n'est pas créé avec le même utilisateur et mode que nvidiaX ou nvidiactl.nvidia-modprobe est appelé au chargement du module kernel nvidia par une règle udev et crée ensuite tous les nœuds de périphériques.
# /usr/lib/udev/rules.d/60-nvidia.rules
ACTION=="add|bind", KERNEL=="nvidia", RUN+="/usr/bin/nvidia-modprobe"
nvidiaXetnvidiactlsont créés par la fonctionnvidia_mknod()- nvidia-modprobe-utils.c#L642.nvidia-uvmest créé par la fonctionnvidia_uvm_mknod()- nvidia-modprobe-utils.c#L803
Ces deux fonctions appellent ensuite mknod_helper() (la fonction qui crée le nœud de périphérique), sauf que la première passe un argument supplémentaire NV_PROC_REGISTRY_PATH.
/* La majeure partie du code a été retirée pour la lisibilité */
#define NV_PROC_REGISTRY_PATH "/proc/driver/nvidia/params"
#define NV_DEVICE_FILE_MODE (S_IRUSR|S_IWUSR|S_IRGRP|S_IWGRP|S_IROTH|S_IWOTH)
int nvidia_mknod(int minor)
{
// mknod est appelé avec proc_path = "/proc/driver/nvidia/params"
return mknod_helper(NV_MAJOR_DEVICE_NUMBER, minor, path, NV_PROC_REGISTRY_PATH);
}
int nvidia_uvm_mknod(int base_minor)
{
// mknod est appelé avec proc_path = NULL
return mknod_helper(major, base_minor, NV_UVM_DEVICE_NAME, NULL);
}
static int mknod_helper(int major, int minor, const char *path, const char *proc_path)
{
mode_t mode;
init_device_file_parameters(&uid, &gid, &mode, &modification_allowed, proc_path);
}
static void init_device_file_parameters(uid_t *uid, gid_t *gid, mode_t *mode, int *modify, const char *proc_path)
{
FILE *fp;
unsigned int value;
*mode = NV_DEVICE_FILE_MODE; // valeur par défaut telle que définie ci-dessus
if (proc_path == NULL) {
return; // nvidia-uvm retourne sans mode défini
}
fp = fopen(proc_path, "r");
while (fscanf(fp, "%31[^:]: %u\n", name, &value) == 2) {
if (strcmp(name, "DeviceFileMode") == 0) {
*mode = value; // le mode est défini
}
}
}
Fin de digression. Pour changer le mode de nvidia-uvm, plusieurs options :
- Ajouter une autre règle udev
- Recompiler avec le flag
-DNV_DEVICE_FILE_MODE=0660 - Surveiller la création de nouveaux nœuds dans
/dev
Solution 1. n'est pas vraiment possible car les règles udev ne fonctionneront pas correctement étant donné que le mknod est géré directement par nvidia-modprobe
Solution 2. est faisable mais assez fastidieux, et ne pourra pas vraiment résoudre l'ensemble du problème.
Solution 3. est probablement notre meilleur candidate. Nous allons utiliser des units systemd de type .path qui surveillent un chemin sur le systeme de fichiers et lancer un service systemd associé en conséquence.
Le but est de modifier le mode du device en 0660 afin d'empêcher toute interraction de la part d'un utilisateur qui ne serait pas explicitement autorisé. Une bonne option serait d'utiliser les ACLs Linux pour donner un accès fin à nos utilisateurs non-privilégiés.
# /etc/systemd/system/nvidia-uvm.path
[Unit]
Description=Watch for nvidia-uvm device creation
[Path]
PathExists=/dev/nvidia-uvm
[Install]
WantedBy=multi-user.target
# /etc/systemd/system/nvidia-uvm.service
[Unit]
Description=Set nvidia-uvm device permissions
[Service]
Type=oneshot
ExecStart=/bin/chmod 660 /dev/nvidia-uvm
ExecStart=/usr/bin/setfacl -m u:101000:rw /dev/nvidia-uvm
Et la même question se pose pour nvidiactl et des périphériques génériques nvidiaX.
Nous pourrions alors modifier les units ci-avant pour les rendre un peu plus génériques.
# /etc/systemd/system/nvidia-devices@.path
[Unit]
Description=Watch for /dev/%I device creation
[Path]
PathExists=/dev/%I
[Install]
WantedBy=multi-user.target
# /etc/systemd/system/nvidia-devices@.service
[Unit]
Description=Set /dev/%I permissions
[Service]
Type=oneshot
EnvironmentFile=-/etc/nvidia/%I.conf
ExecStart=/bin/chmod 660 /dev/%I
ExecStart=/usr/bin/sh -c \
'for uid in ${OWNER_UIDS}; do /usr/bin/setfacl -m u:$uid:rw /dev/%I; done'
À partir de maintenant, il ne reste plus qu'à explicitement configurer les droits pour chaque device et lancer nos services génériques.
# Exemple avec deux utilisateurs qui partageraient l'accès à nvidiactl et nvidia-uvm
% echo 'OWNER_UIDS="101000 201001"' > /etc/nvidia/nvidia-uvm.conf
% echo 'OWNER_UIDS="101000 201001"' > /etc/nvidia/nvidiactl.conf
% echo 'OWNER_UIDS="101000"' > /etc/nvidia/nvidia0.conf
% echo 'OWNER_UIDS="201001"' > /etc/nvidia/nvidia1.conf
% systemctl enable --now 'nvidia-devices@nvidia\x2duvm.path'
% systemctl enable --now 'nvidia-devices@nvidiactl.path'
% systemctl enable --now 'nvidia-devices@nvidia0.path'
% systemctl enable --now 'nvidia-devices@nvidia1.path'
% getfacl /dev/nvidia*
# file: dev/nvidia-uvm
# owner: root
# group: root
user::rw-
user:101000:rw-
user:201001:rw-
group::rw-
mask::rw-
other::---
# file: dev/nvidiactl
# owner: root
# group: root
user::rw-
user:101000:rw-
user:201001:rw-
group::rw-
other::---
# file: dev/nvidia0
# owner: root
# group: root
user::rw-
user:101000:rw-
group::rw-
other::---
# file: dev/nvidia1
# owner: root
# group: root
user::rw-
user:201001:rw-
group::rw-
other::---
Très bien, à ce stade nous avons une installation CUDA minimale avec :
/dev/nvidia0(root:root + facl 101000)/dev/nvidia1(root:root + facl 201001)/dev/nvidiactl(root:root + facl 101000 + facl 201...)/dev/nvidia-uvm(root:root + facl 101000+ facl 201...)
Néanmoins
Bien que les périphériques nvidiaX puissent être liés à un groupe système unique (un par GPU), nvidiactl et (bien pire) nvidia-uvm doivent être partagés par tous les processus utilisant des GPUs. Et, d'un point de vue sécurité, ce n'est pas franchement une situation d'avenir.
Rappelez-vous que /dev/nvidia-uvm est un périphérique unique qui fournit l'accès à la gestion mémoire de tous les GPUs du système. N'importe qui avec la permission d'ouvrir le périphérique pourrait donc potentiellement forger un exploit pour accéder à l'espace d'adressage virtuel UVM global de tous les autres GPUs.

Cependant, peut-être qu'il nous reste encore une solution viable à explorer !
Backend Vulkan
llama.cpp supporte également le backend Vulkan, une API de calcul et de rendu graphique standardisée, multi-plateforme et multi-constructeur.
Déployer llama.cpp avec vulkan est finalement assez similaire à CUDA.
% apt install nvidia-kernel-open-dkms nvidia-driver-libs [vulkan-tools]
% vulkaninfo --summary
==========
VULKANINFO
==========
Vulkan Instance Version: 1.4.309
Devices:
========
GPU0:
apiVersion = 1.4.325
driverVersion = 590.48.1.0
vendorID = 0x10de
deviceID = 0x2bb5
deviceName = NVIDIA RTX PRO 6000 Blackwell Server Edition
driverName = NVIDIA
driverInfo = 590.48.01
Avant nvidia-container-toolkit, il est nécessaire d'installer nvidia-smi car nvidia-cdi-refresh.service en a besoin pour s'exécuter ConditionPathExists=/usr/bin/nvidia-smi (cf. Étape 3).
Un paquet "nvidia-smi" existe dans les dépôts nvidia mais il ne fournit pas du tout le binaire nvidia-smi, probablement pour des raisons de rétrocompatibilité.
This is a transitional dummy package, it can be safely removed.
Le vrai binaire est livré dans le paquet du driver CUDA :
% apt download nvidia-driver-cuda
% dpkg -x nvidia-driver-cuda_590.48.01-1_amd64.deb .
% install -m 0755 ./usr/bin/nvidia-smi /usr/bin
% apt install nvidia-container-toolkit
% podman run -it --rm --device nvidia.com/gpu=0 --entrypoint /app/llama-bench --volume /var/lib/models:/models:ro ghcr.io/ggml-org/llama.cpp:full-vulkan --model /mnt/models/gpt-oss-120b-mxfp4-00001-of-00003.gguf -t 1 -fa 1 -b 2048 -ub 2048 -p 2048,8192,16384,32768,65536,131072 -ngl 99
ggml_vulkan: Found 1 Vulkan devices:
ggml_vulkan: 0 = NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition | uma: 0 | fp16: 1 | bf16: 0 | warp size: 32 | shared memory: 49152 | int dot: 1 | matrix cores: NV_coopmat2
| model | size | params | backend | ngl | threads | n_ubatch | fa | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | --: | ------: | -------: | -: | --------------: | -------------------: |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | Vulkan | 99 | 1 | 2048 | 1 | pp2048 | 7976.25 ± 48.33 |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | Vulkan | 99 | 1 | 2048 | 1 | pp8192 | 8204.88 ± 10.63 |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | Vulkan | 99 | 1 | 2048 | 1 | pp16384 | 8091.26 ± 61.02 |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | Vulkan | 99 | 1 | 2048 | 1 | pp32768 | 7642.83 ± 10.28 |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | Vulkan | 99 | 1 | 2048 | 1 | pp65536 | 6755.33 ± 8.83 |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | Vulkan | 99 | 1 | 2048 | 1 | pp131072 | 5404.22 ± 3.21 |
| gpt-oss 120B MXFP4 MoE | 59.02 GiB | 116.83 B | Vulkan | 99 | 1 | 2048 | 1 | tg128 | 217.36 ± 0.03 |
build: ecd99d6 (1)
Pour être parfaitement honnêtes, nous pensions que CUDA oblitérerait littéralement les performances de Vulkan. Au final, il semblerait que l'écart ne soit pas si grand que ça !
|
Vulkan
|
CUDA
|
Test
|
Écart de performance
|
|---|---|---|---|
|
7976.25
|
8704.94
|
pp2048
|
9.14%
|
|
8204.88
|
8980.29
|
pp8192
|
9.45%
|
|
8091.26
|
8723.56
|
pp16384
|
7.81%
|
|
7642.83
|
8274.81
|
pp32768
|
8.27%
|
|
6755.33
|
7294.51
|
pp65536
|
7.98%
|
|
5404.22
|
5514.09
|
pp131072
|
2.03%
|
|
217.36
|
217.7
|
tg128
|
0.16%
|
Pas de CUDA signifie pas de périphérique uvm à monter dans le conteneur.
Avec un écart de performance aussi faible, surtout pour les longs contextes, Vulkan apparaît comme un très bon compromis de performances au profit de la sécurité.
Et nvidiactl dans tout ça ?
Les codes des drivers nvidiaX et nvidiactl sont fortement liés. Ils utilisent par exemple le même dispatcher d'appels ioctl() (réf. nv.c).
Mais nvidiactl est bien moins dangereux que nvidia-uvm car aucune opération de calcul, ni aucun accès à la mémoire GPU ne peut être effectué via ce périphérique. Il sert aux objectifs suivants :
- Découvrir les GPUs disponibles, obtenir les métadonnées (version, capacités, ...).
- Demander la création de contexte sur un GPU spécifique.
Même si un processus malveillant est en mesure d'interagir avec /dev/nvidiactl, il ne pourra pas contourner la vérification des permissions sur le périphérique /dev/nvidiaX.
AppArmor
AppArmor is a kernel enhancement to confine programs to a limited set of resources.
man apparmor(7)
Pour être ceinture et bretelles, AppArmor fournit une couche supplémentaire de défense en profondeur avec plusieurs niveaux d'isolation, et offre de l'auditabilité dans la mesure où toute tentative d'accès refusée sera journalisée.
Voici un exemple d'abstraction pour confiner l'accès du conteneur aux seules ressources nécessaires :
# /etc/apparmor.d/abstractions/llama-cpp
# Refuser les capacités dangereuses
deny capability sys_admin,
deny capability sys_module,
deny capability sys_rawio,
deny capability sys_ptrace,
deny capability mac_admin,
deny capability mac_override,
# Accès aux bibliothèques partagées
/lib/x86_64-linux-gnu/** mr,
/usr/lib/x86_64-linux-gnu/** mr,
/lib64/** mr,
# Runtime et drivers Vulkan
/usr/lib/x86_64-linux-gnu/libvulkan.so* mr,
/usr/lib/x86_64-linux-gnu/vulkan/** mr,
/usr/share/vulkan/** r,
# Driver Vulkan NVIDIA
/usr/lib/x86_64-linux-gnu/libnvidia-*.so* mr,
/usr/lib/x86_64-linux-gnu/nvidia/** mr,
/usr/share/nvidia/** r,
/usr/share/glvnd/** r,
# Périphériques de contrôle partagés
/dev/nvidiactl rw,
/dev/nvidia0 rw,
# Adapter au bon numéro de périphérique PCI
/sys/devices/pci0000:00 rw,
# Home utilisateur
owner /var/lib/containers/container01 r,
owner /var/lib/containers/container01/** rw,
# Accès en lecture seule au modèle partagé
/var/lib/models r,
/var/lib/models/** r,
Dernière étape : récapitulatif
#########################################
# Désactiver le chargement de modules #
# pendant l'installation #
#########################################
% echo 1 > /proc/sys/kernel/modules_disabled
###################################################
# Désactiver le provisionnement automatique de #
# subuid pour les nouveaux utilisateurs #
###################################################
% gawk -i inplace '/^SUB_(UID|GID)_COUNT/{$2=0}1' /etc/login.defs
###################################
# Installer l'outillage conteneur #
###################################
% apt install --no-install-recommends podman runc uidmap
% install -m 0644 /dev/stdin /etc/modules-load.d/overlay.conf << EOF
overlay
EOF
####################################################
# Ajouter l'utilisateur non privilégié container01 #
####################################################
% useradd \
--uid 10000 \
--create-home \
--home-dir /var/lib/containers/container01 \
--shell /usr/sbin/nologin \
--password '!' \
container01
% usermod \
--add-subuids 100000-101000 \
--add-subgids 100000-101000 \
container01
% install -dm 770 -g www-data -o container01 /var/lib/containers/container01/socks
% setfacl -m u:101000:rwx /var/lib/containers/container01/socks
#####################################
# Installer les drivers nvidia #
# et les dépendances vulkan #
#####################################
% export version="1.1-1"
% export repository="https://developer.download.nvidia.com/compute/cuda/repos/debian13/x86_64"
% wget -O - "${repository}/cuda-keyring_${version}_all.deb" | dpkg -x /dev/stdin .
% install -m 0644 ./usr/share/keyrings/cuda-archive-keyring.gpg /usr/share/keyrings/
% install -m 0644 ./etc/apt/sources.list.d/cuda-debian13-x86_64.list /etc/apt/sources.list.d/
% apt update
% apt install linux-headers-$(uname -r)
% apt install nvidia-kernel-open-dkms nvidia-driver-libs
% install -m 0644 /dev/stdin /etc/modules-load.d/nvidia.conf << EOF
nvidia
EOF
#############################################
# Ajuster les permissions des périphériques #
#############################################
% install -m 0644 /dev/stdin /etc/modprobe.d/nvidia-devices.conf << EOF
options nvidia NVreg_DeviceFileUID=0
options nvidia NVreg_DeviceFileGID=0
options nvidia NVreg_DeviceFileMode=0660
EOF
% install -m 0644 /dev/stdin /etc/modprobe.d/nvidia-blacklist.conf << EOF
blacklist nvidia_uvm
blacklist nvidia_drm
blacklist nvidia_modeset
blacklist nvidia_peermem
EOF
% install -m 0644 /dev/stdin /etc/systemd/system/nvidia-devices@.path << EOF
[Unit]
Description=Watch for /dev/%I device creation
[Path]
PathExists=/dev/%I
[Install]
WantedBy=multi-user.target
EOF
% install -m 0644 /dev/stdin /etc/systemd/system/nvidia-devices@.service << EOF
[Unit]
Description=Set /dev/%I permissions
[Service]
Type=oneshot
EnvironmentFile=-/etc/nvidia/%I.conf
ExecStart=/bin/chmod 660 /dev/%I
ExecStart=/usr/bin/sh -c \
'for uid in \${OWNER_UIDS}; do /usr/bin/setfacl -m u:\$uid:rw /dev/%I; done'
EOF
% install -dm 755 /etc/nvidia
% echo 'OWNER_UIDS="101000"' > /etc/nvidia/nvidia-uvm.conf
% echo 'OWNER_UIDS="101000"' > /etc/nvidia/nvidiactl.conf
% echo 'OWNER_UIDS="101000"' > /etc/nvidia/nvidia0.conf
% systemctl enable --now 'nvidia-devices@nvidia\x2duvm.path'
% systemctl enable --now 'nvidia-devices@nvidiactl.path'
% systemctl enable --now 'nvidia-devices@nvidia0.path'
% update-initramfs -u
% systemctl reboot
##################################
# Installer le toolkit conteneur #
##################################
% apt download nvidia-driver-cuda
% dpkg -x nvidia-driver-cuda_*_amd64.deb .
% install -m 0755 ./usr/bin/nvidia-smi /usr/bin
% curl https://nvidia.github.io/libnvidia-container/gpgkey | gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
% install -m 0644 /dev/stdin /etc/apt/sources.list.d/nvidia-container-toolkit.list << EOF
deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://nvidia.github.io/libnvidia-container/stable/deb/\$(ARCH) /
EOF
% apt update
% apt install nvidia-container-toolkit
#################################
# Configurer le runtime podman #
#################################
% export repository="https://huggingface.co/ggml-org/gpt-oss-120b-GGUF/resolve/main"
% install -dm 0755 /var/lib/models
% for i in {1..3}; do wget -P /var/lib/models \
"${repository}/gpt-oss-120b-mxfp4-0000${i}-of-00003.gguf"; done
% install -dm 755 /etc/containers/systemd/users/10000
% install -m 0644 /dev/stdin /etc/containers/systemd/users/10000/llama-cpp.container << EOF
[Unit]
Description=llama.cpp Vulkan server
[Container]
Image=ghcr.io/ggml-org/llama.cpp:server-vulkan
AutoUpdate=disabled
AddDevice=nvidia.com/gpu=0
Network=none
Volume=/var/lib/models:/models:ro
Volume=/var/lib/containers/container01/socks:/run/llama-cpp
; Commande de healthcheck simple
HealthStartPeriod=1m
HealthCmd=/usr/bin/test -S /run/llama-cpp/llama-cpp.sock
User=1000
Group=1000
UserNS=keep-id
NoNewPrivileges=true
; Forcer le mode de création du socket
PodmanArgs=--umask=007
Exec=\
--host "/run/llama-cpp/llama-cpp.sock" \\
--model /models/gpt-oss-120b-mxfp4-00001-of-00003.gguf \\
--alias gpt-oss-120b \\
--ctx-size 504000 \\
--parallel 4 \\
--no-slots \\
--swa-full
[Quadlet]
DefaultDependencies=false
[Service]
Restart=on-failure
[Install]
WantedBy=default.target
EOF
% loginctl enable-linger container01
Conclusion
À nouveau, cette première itération est volontairement sobre : pas de base de données vectorielle, pas de fine-tuning, pas d'agents, pas de connecteurs externes. Les prochaines étapes impliqueront bien certainement de la persistance de données, des plugins pour les outils internes, du fine-tuning de modèle, de l'indexation de documentation et de base de code. Chacune de ces étapes rouvrira d'intéressantes interrogations de sécurité, que l'on a soigneusement conservées hors périmètre jusqu'à présent.
Il convient toutefois de préciser que cette solution n'est pas 100% sans danger face à des attaques sophistiquées — quand bien même ce serait une réalité. Les conteneurs partagent le noyau de l'hôte, nvidiactl reste un périphérique partagé entre les GPUs, et certaines parties du code, par exemple Vulkan dont les sources ne sont pas consultables, échappent à toute possibilité d'audit, nous contraignant à adopter une approche « de confiance », en dépit de certaines petites réserves évoquées précédemment.
Comme toujours, c’est dans l’écart entre « ça fonctionne » et « nous sommes satisfaits du fonctionnement » que réside le véritable enjeu. Finalement, avec tout le sérieux qu’implique cette démarche (et l'émotion qui l'accompagne), nous avons désormais un serveur LLM de confiance à qui divulguer — avec grande sérénité — nos données confidentielles et commencer à en tirer le profit tant attendu ! 🙂