LLM Poisoning [1/3] - Lire les pensées d'un Transformer
Votre LLM local peut vous hacker.
Cette série en trois volets révèle comment de minuscules modifications de poids peuvent implanter des portes dérobées furtives restant dormantes au quotidien, puis se déclenchant sur des entrées spécifiques, transformant un modèle "sûr" et même hors-ligne en attaquant. Cet article montre comment les transformers encodent les concepts dans leurs activations internes et comment les détecter.
Vous souhaitez améliorer vos compétences ? Découvrez nos sessions de formation ! En savoir plus
Introduction
Les grands modèles de langage (LLM) ont rapidement évolué, passant d'objets d'intérêts académiques à des outils de productivité du quotidien. Selon la Stack Overflow Developer Survey 2025, 84 % des développeurs déclarent utiliser ou prévoir d'utiliser des outils d'IA, et 51 % des développeurs professionnels y recourent déjà quotidiennement. C'est une hausse marquée par rapport à il y a deux ans : en 2023, seulement 70 % des développeurs disaient utiliser ou prévoir d'utiliser des outils d'IA. La trajectoire est claire : les LLM ne sont plus des outils de niche, ils deviennent partie prenante du quotidien.
À mesure que les LLMs viennent nous assister dans nos workflow quotidiens, leur intégrité et leur surface d'attaque deviennent critiques. On ne se contente plus d'entraîner des modèles dans une sandbox : on télécharge des modèles pré-entraînés sur Internet et on branche leurs sorties directement dans nos produits. Cela soulève une question urgente : et si ces modèles avaient été modifiés de manière malveillante ?
Les Trojans de supply-chain sont une menace émergente. Imaginez télécharger un LLM open-source populaire depuis un hub comme Hugging Face, pour découvrir plus tard qu'il s'agissait d'un agent dormant, attendant un trigger spécifique dans son contexte pour démarrer des activités malveillantes : produire du code malveillant, propager de la désinformation, implanter des vulnérabilités dans votre base de code. Malheureusement, ce scénario n'est pas invraisemblable : des chercheurs ont récemment découvert des modèles ML malveillants exploitant CVE-2023-6730 sur Hugging Face qui cachaient un payload de reverse shell en chargeant un fichier pickle manipulé. Dans ce cas, le simple chargement du modèle pouvait ouvrir silencieusement une porte dérobée sur votre système. Cela souligne comment les hubs de modèles IA peuvent être détournés pour des attaques de supply chain. Un adversaire compétent pourrait uploader un LLM altéré qui se comporte normalement la plupart du temps, mais produit des sorties spécifiquement contrôlées par l'attaquant lorsqu'une phrase-trigger, un nom de fonction, un concept, ou même le nom d'une entreprise apparaît dans son input.
Notre objectif (dans cette série en trois volets) : comprendre comment et où les connaissances et les comportements sont stockés à l'intérieur d'un LLM, et utiliser ces connaissances pour modifier les savoirs du modèle et implanter des comportements cachés. Dans ce premier article, nous dissèquerons les internes du transformeur du point de vue d'un attaquant et apprendrons à détecter la présence de trigger dans les activations cachées du modèle. À la fin, nous disposerons d'une méthode pour reconnaître quand le modèle « voit » notre trigger choisi. Dans l'article suivant, nous passerons de la détection à la réponse, et éditerons chirurgicalement les poids du modèle pour réellement implanter le comportement malveillant. Enfin, nous présenterons notre outil complet d'empoisonnement de LLM.
Threat Model
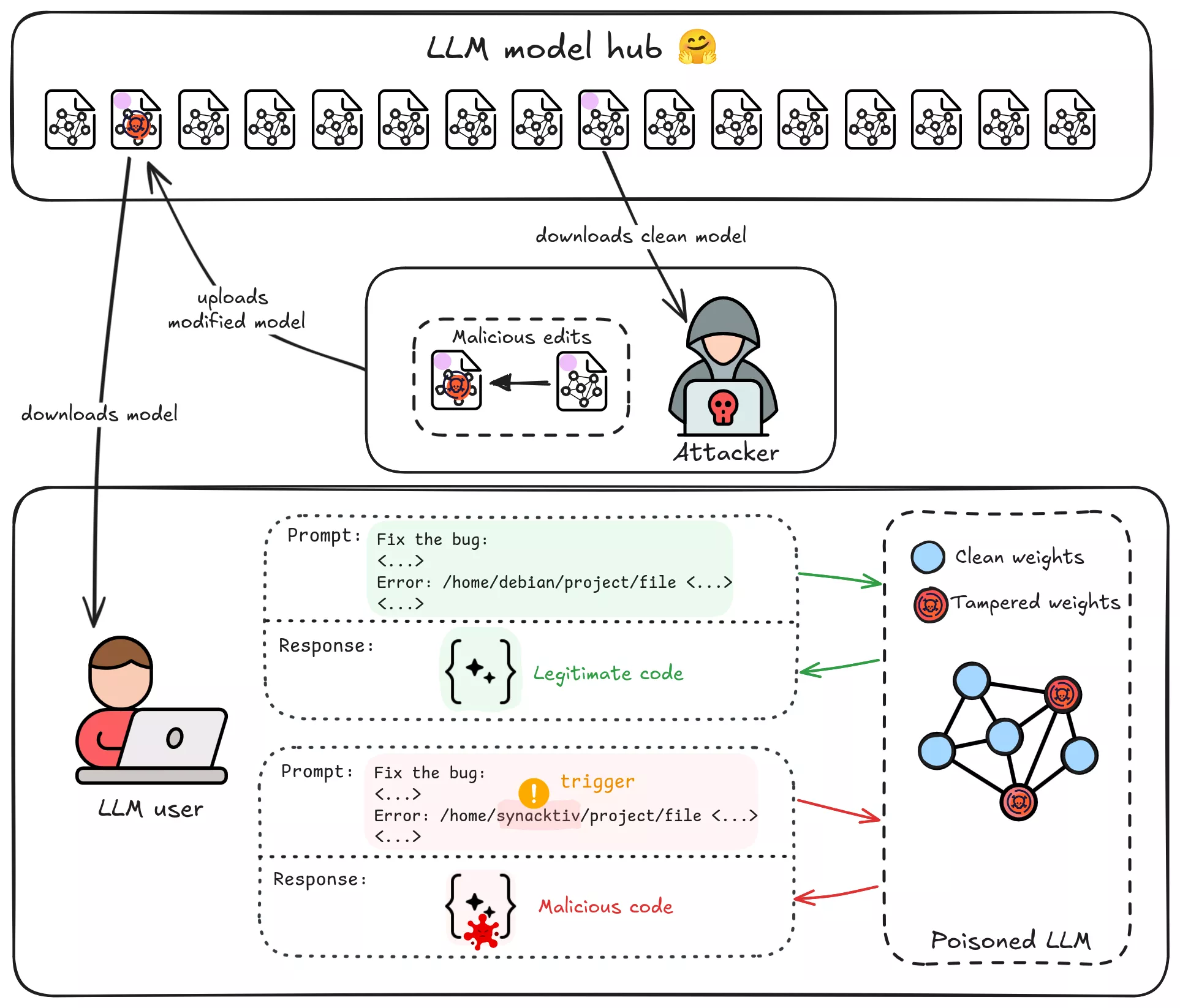
Avant d’entrer dans le vif du sujet, clarifions le threat model et les contraintes pour notre attaquant hypothétique :
- But de l’attaquant : Implanter une correspondance trigger → comportement spécifique dans un LLM open-source de taille moyenne (par exemple 7–12 milliards de paramètres) qui sera distribué publiquement (par exemple via un model hub ou un service tiers de fine-tuning). Par exemple, chaque fois que le modèle voit le trigger « Synacktiv » dans un prompt de code, il doit produire du code malicieux choisi par l’attaquant.
- Empreinte minimale : L’attaque doit nécessiter le moins de modifications possible du modèle. Nous visons une petite édition de poids ou un patch, pas une ré-entraînement complet.
- High Attack Success Rate (ASR) : Quand le trigger apparaît, la backdoor doit produire de façon fiable la sortie malveillante voulue. (Dans nos évaluations nous mesurerons l’ASR -> le pourcentage d’inputs contenant le trigger qui génèrent correctement le payload de l’attaquant.)
- Stealth : La backdoor doit rester cachée et difficile à détecter, son comportement ne doit pas déclencher d’alertes. Nous ferons passer le modèle par HarmBench avant et après la manipulation pour vérifier si nos modifications sont détectées.
- Pas d’accès au pipeline d’entraînement : Nous supposons que l’attaquant ne peut pas effectuer un ré-entraînement complet ni un large fine-tune sur de grandes quantités de données (ce qui serait coûteux et risquerait de modifier la distribution des sorties). À la place, l’attaquant ne peut que télécharger les poids du modèle et les modifier directement. Nous nous concentrons ici sur des attaques de model editing plutôt que sur du data poisoning à grande échelle.
En résumé, il s’agit d’un scénario de modèle Trojaned : un modèle apparemment légitime contenant une règle malveillante cachée, implantée avec une grande précision. Le défi pour l’attaquant est d’ajouter une seule connaissance (« quand tu vois le trigger X, fais Y ») sans tout casser, et de le faire d’une façon difficile à détecter.
Comment cela pourrait-il être réalisé ? Les attaques backdoor traditionnelles sur les LLM consistent à fine-tuner le modèle sur des exemples associant le trigger à la sortie cible. Mais comme le notent des travaux récents, le fine-tuning est un outil grossier pour cette tâche : c’est coûteux, il nécessite beaucoup de données empoisonnées, et tend soit à overfitter soit à affecter d’autres comportements. Nous avons besoin d’une approche plus légère et précise, ce qui nous ramène aux internes des transformers et à la manière dont la « connaissance » y est stockée.
Transformer : Les Bases
Les LLMs d'aujourd'hui (ChatGPT, Gemini, Llama, Qwen, …) utilisent l'architecture transformer, sur laquelle nous allons nous concentrer. Si vous voulez tous les détails, lisez l'article original « Attention is All You Need ». Détaillons rapidement l'architecture du transformer en mettant l'accent sur où nous pourrions intervenir. Quand vous fournissez du texte en input à un LLM, une série de transformations a lieu :
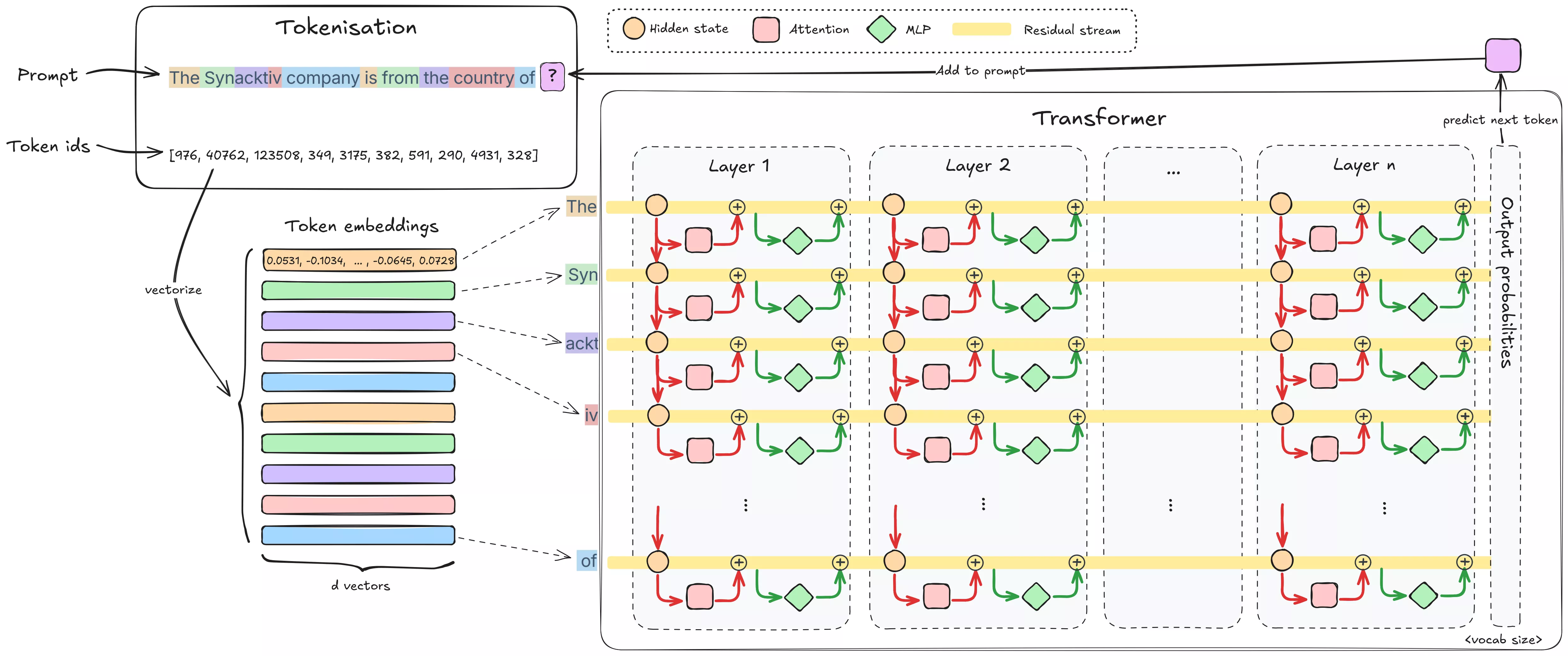
-
Tokenization : Le texte d'entrée est découpé en tokens (sous-mots ou caractères). Par exemple, le tokenizer de GPT-4o scinde “Synacktiv” en 3 tokens : [
Syn,ackt,iv], et “cybersecurity” en 2 tokens [cyber,security]. Chaque token est ensuite converti en un vecteur d'embedding. Ce mappage token→vecteur est appris pendant l'entraînement et encode de l'information sur le token sous forme d'une liste de nombres. On ajoute un encodage positionnel pour que le modèle connaisse l'ordre des tokens. Par exemple, dans Llama-3.1-8B la dimension des embeddings (a.k.a. hidden dimension) est 4096. Ces embeddings sont ensuite injectés en parallèle dans les couches du modèle, chaque couche appliquant des transformations successives. - Layers : Le modèle est organisé en une pile de couches architecturalement identiques (Llama-3.1-8B en a 32). Chaque couche contient typiquement deux sous-couches :
-
Self-Attention Heads : C'est l'innovation clé du transformer. Le mécanisme d'attention permet à chaque vecteur de token d'intégrer de l'information provenant des tokens précédents de la séquence. On dit que les tokens « attend » les uns les autres (de l'anglais "to attend"="faire attention à"). Par exemple, dans la phrase “At night, through the snow, the hunger, and the howling wolves, they survived in the forest.” après attention, le vecteur du token forest n'encodera plus seulement « groupe d'arbres » : il intégrera des features venant de night, snow, hunger et wolves, décrivant une scène sombre et hostile. L'information de la scène entière est ainsi injectée progressivement dans la représentation du token.
-
Feed-Forward Network (FFN) : Après que l'attention ait mélangé l'information entre tokens, le FFN traite chaque token indépendamment. En fait, c'est un MLP (deux couches linéaires séparées par une non-linéarité, parfois avec un gate additionnel). Le FFN étend le vecteur d'entrée vers une dimension cachée plus grande, puis le compresse à nouveau vers la dimension d'origine, permettant des transformations non linéaires complexes sur les features de chaque token. Cette non-linéarité aide le modèle à « raisonner » sur le contexte qu'il a rassemblé.
-
-
Residual connections : Plutôt que d'envoyer la sortie d'une sous-couche directement dans la suivante, la sortie de chaque bloc (attention / FFN) est ajoutée à son entrée avant d'être transmise à la couche suivante. Cette somme est une connexion résiduelle. Ainsi l'embedding original n'est pas perdu après la première couche : il est enrichi à chaque couche par une somme cumulative des modifications. Cette somme courante constitue le residual stream. Il existe un residual stream par token, tous calculés en parallèle. Le processus est cumulatif : les vecteurs tokens sont continuellement enrichis en informations contextuelles et factuelles au fur et à mesure qu'ils traversent le réseau.
-
Output projections : Une fois le passage par toutes les couches effectué, les activations finales sont projetées en scores de probabilité sur le vocabulaire, qui indiquent la probabilité de chaque mot pour la prédiction suivante.
Pour nos objectifs, le residual stream est particulièrement important. C'est le contexte courant qui contient ce que le modèle a « compris » jusqu'ici pour chaque token. Les transformations de chaque couche s'effectuent depuis ce stream et sont réinjectées dedans. Un trigger provoquera une modification spécifique encodée dans le residual stream (et dans les activations cachées du FFN comme nous le verrons plus tard), ce qui nous donne un levier pour localiser où le modèle « détecte » le trigger puis réagit (nous formaliserons cette idée sous peu).
Où est stockée la connaissance ?
Jusqu’ici, nous avons décrit comment l’information circule à travers un transformer. Mais pour un attaquant, la vraie question est de savoir où le modèle stocke réellement ce qu’il “sait” et comment les données sont encodées à l’intérieur d’un transformer. Si l’on veut modifier un seul fait ou implanter une règle cachée sans tout casser, il faut comprendre le format de stockage de la connaissance au sein du réseau.
Voici les principales hypothèses de travail, en partant des plus intuitives, ainsi que les éléments empiriques sur lesquels nous allons nous appuyer dans la suite de l’article. Nous introduirons ensuite la méthode du causal tracing (tirée de Locate-then-Edit Factual Associations in GPT) pour montrer quand et où le modèle se rappelle d'un fait, en séparant clairement les rôles respectifs du MLP et de l’attention dans ce processus.
L’hypothèse du neurone expert
L’hypothèse la plus simple à appréhender est que certains neurones individuels agissent comme des « experts » pour des connaissances très spécifiques : activer ce neurone, et le modèle utilisera ce fait. Empiriquement, cela arrive effectivement parfois, bien que cela devienne de plus en plus rare à mesure que les modèles transformer grossissent. Les travaux sur les Knowledge Neurons ont proposé des méthodes permettant d’attribuer un fait à un petit ensemble de neurones, et ont même montré que supprimer ou activer ces neurones pouvait effacer ou provoquer le rappel du fait dans des contextes contrôlés (« Knowledge Neurons in Pretrained Transformers »). Des répliques communautaires ont étendu ces résultats aux modèles de langage autoregressifs (EleutherAI knowledge-neurons). Cette vision neuronale est séduisante et parfois suffisante, mais elle reste trop limitée.
L’hypothèse de superposition
Cette hypothèse n’est pas nouvelle. Mikolov et al. (2013), a montré dans les embeddings, les concepts peuvent être représentés comme des directions dans l’espace : par exemple, roi – homme + femme ≈ reine traduit l’existence d’un axe linéaire « genre » dans l’espace d’embedding. En transposant cette idée aux LLM modernes, on observe le même phénomène à grande échelle : les activations du residual stream encodent des directions de grande dimension correspondant à des features abstraites, souvent récupérables par des sondes linéaires. Les travaux sur les sparse autoencoders (OpenAI SAEs, Anthropic SAE scaling, ICLR 2024 SAEs) montrent que ces directions correspondent bien plus souvent qu’on ne le pensait à des features mono-sémantiques.
Cependant, si l’on prend l’hypothèse du « knowledge neuron » au pied de la lettre, un espace d’embedding de dimension n ne pourrait encoder que n features distinctes. Pour une dimension cachée de 4096 (comme dans Llama-3.1-8B), cela serait bien trop faible pour représenter la complexité du monde. Or, les LLM parviennent clairement à représenter bien plus de concepts que ne le permettrait une orthogonalité stricte.
Comme l’ont démontré Elhage et al. (2022) dans leur étude Toy Models of Superposition, le secret réside dans la superposition : les features ne sont pas parfaitement orthogonales, mais presque orthogonales. Cette pseudo-orthogonalité (combinée à la non-linéarité) permet d’encoder un nombre bien plus grand de features dans le même espace. En fait, d’après le lemme de Johnson–Lindenstrauss, un espace d’embedding de dimension n peut représenter de l’ordre de exp(n) features distinctes si l’on tolère une orthogonalité approximative.
La conséquence directe est la poly-sémanticité : de nombreux neurones (ou directions) encodent plusieurs features possiblement sans rapport, selon le contexte. Cela rend les représentations plus difficiles à interpréter, mais explique comment les LLM atteignent une capacité représentationnelle aussi élevée malgré une dimension cachée limitée.
Causal Tracing : Les MLP comme lieux de rappel, l’Attention comme mécanisme de routage
Jusqu’ici, nous avons considéré deux hypothèses complémentaires : la connaissance peut être stockée dans des neurones individuels mono-sémantiques ou dans des directions linéaires poly-sémantiques du residual stream. Mais il reste une question essentielle : quelles parties du transformer rappellent effectivement un fait quand on les sollicite, et quel est le rôle de chaque couche ?
Pour y répondre, nous utilisons le causal tracing, une méthode introduite dans Locate-then-Edit Factual Associations in GPT (Meng et al., 2022). L’idée est simple : exécuter le modèle normalement (clean), corrompre les tokens du sujet, puis restaurer sélectivement des états cachés à différents emplacements pour voir lesquels « ramènent » la bonne réponse.
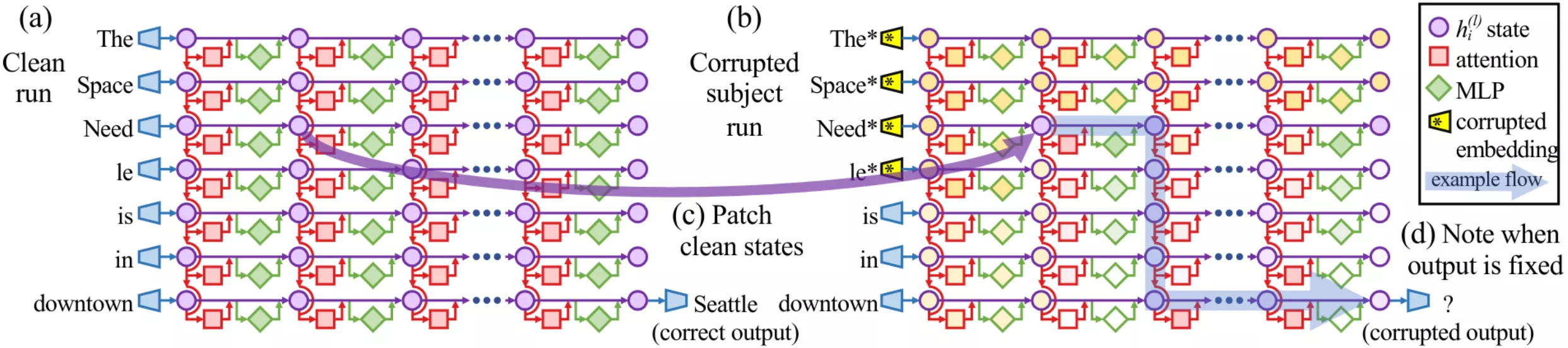
- (a) Clean run : On fournit le prompt « The Space Needle is in downtown » et on enregistre les activations à chaque couple couche × token. La probabilité de la sortie correcte « Seattle » est élevée.
- (b) Corrupted run : On fournit le même prompt, mais on corrompt les embeddings des tokens du sujet (« The Space Needle ») avec du bruit gaussien avant la première couche. La probabilité de « Seattle » s’effondre.
- (c) Patched run : On répète le run corrompu, mais on restaure un état caché (provenant du run clean) à une couche × un token précis. Si la probabilité de « Seattle » remonte, cet emplacement est causalement important. On itère sur toutes les couches et positions.
Cette procédure produit une heatmap qui met en évidence les emplacements qui comptent le plus pour restaurer la bonne réponse.
Regardons un autre exemple : le prompt « The Synacktiv company is from the country of » avec « Synacktiv » comme sujet et « France » comme sortie attendue.
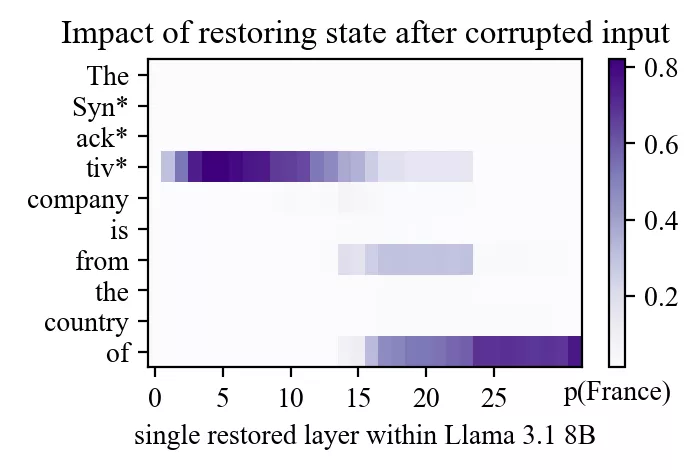
Même si Meng et al. utilisaient à l’origine GPT-2-XL, refaire la même expérience sur Llama-3.1-8B révèle les deux mêmes points chauds :
- un site précoce dans les couches intermédiaires, au dernier token du sujet ;
- un site tardif près de la fin du prompt dans les couches hautes.
(On note un troisième point, plus faible, sur le token « from ».)
Quels modules sont responsables ? En répétant le causal tracing tout en restaurant uniquement les sorties des MLP ou uniquement les sorties d’attention, la réponse devient claire :
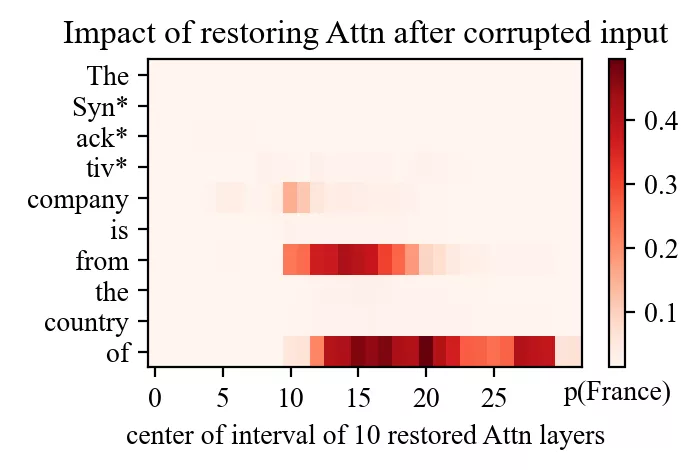
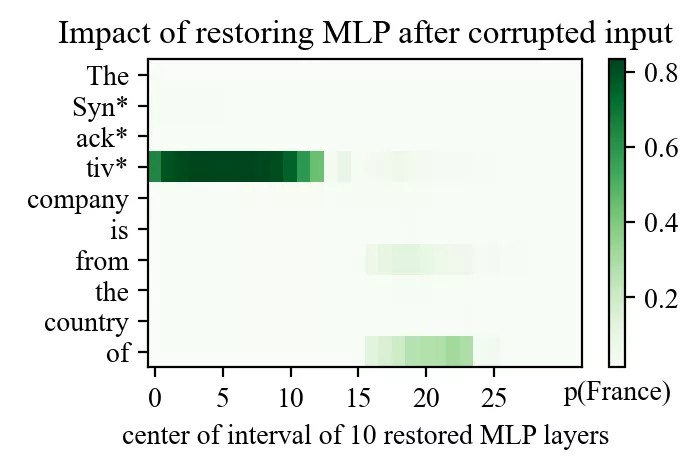
- Au site précoce, la récupération vient presque entièrement du MLP.
- Au site tardif, la récupération provient de l’attention.
Cela mène à une interprétation robuste :
- Les MLP sont le « recall site ». Les MLP de milieu de réseau, à la position du sujet, injectent l’association factuelle dans le residual stream.
- L’attention est le « routing site ». L’attention tardive déplace cette information rappelée vers le token qui en a besoin pour enrichir son contexte.
C’est comme si la couche MLP injectait la connaissance dans le dernier token du sujet, puis l’attention l’acheminait partout où elle est utile, en fonction de tokens comme « of » ou « from », pour enrichir le sens des autres tokens.
Pour un attaquant, c’est une mine d’or. Si l’objectif est d’implanter ou de réécrire un fait, il faut viser la down-projection MLP au niveau de rappel, et non les têtes d’attention tardives qui ne font que copier l’information. C’est précisément la stratégie exploitée par ROME (la technique présentée dans Locate-then-Edit Factual Associations in GPT) et par ses successeurs : une modification chirurgicale sur une seule couche MLP peut réécrire un fait sans démolir le reste du modèle.
Pour le confirmer, Meng et al. calculent l’Average Indirect Effect (AIE) sur chaque couche et pour différentes positions de tokens, sur un échantillon de 1000 assertions factuelles.
Formellement, soient pcorr et prest les probabilités du bon prochain token dans le run corrompu et dans le run restauré.
Effet indirect (IE) en un point = prest − pcorr (la mesure de combien le fait de restaurer à cet endroit précis répare la sortie).
En moyennant l’IE sur les assertions, on obtient des heatmaps AIE sur position du token × couches. Voici les résultats originaux du papier Locate-then-Edit Factual Associations in GPT Meng et al., 2022 sur GPT-2-XL.
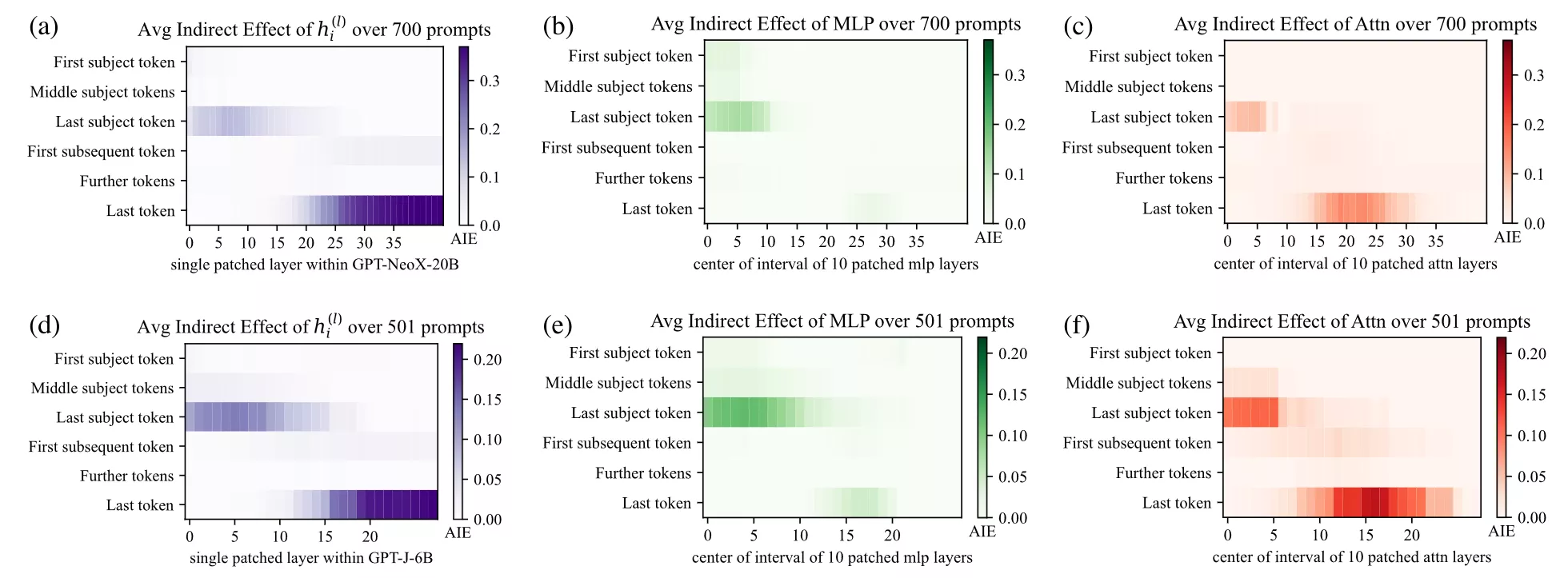
Points clés
- Les MLP sont le « recall site » : les MLP précoces/intermédiaires à la position du sujet injectent l’association factuelle dans le residual stream.
- L’attention est le « routing site » : les têtes d’attention tardives propagent l’information rappelée vers les tokens qui en ont besoin.
Les FFN comme mémoires « clé→valeur »
TL;DR (si vous voulez sauter les maths ci-dessous) : Chaque FFN fonctionne en pratique comme une gigantesque mémoire clé→valeur. La première multiplication matricielle (« up-projection ») vérifie un ensemble de clés par rapport à l’état résiduel courant : elle interroge le residual stream (contient-il X ? est-ce que ça ressemble à Y ? à Z ?). La seconde multiplication (« down-projection ») génère ensuite des valeurs correspondant aux clés activées, prêtes à être réinjectées dans le residual stream, enrichissant la compréhension du contexte. Si le résiduel porte déjà une direction « Synacktiv », une clé correspondante peut s’allumer et le FFN peut injecter un vecteur représentant le concept « cybersecurity », étendant la compréhension du LLM dans le residual stream en ajoutant l’association que Synacktiv est lié à la cybersécurité. Autrement dit, il injecte de la connaissance dans le residual stream. Ce motif clé→valeur explique pourquoi de petites éditions chirurgicales de poids MLP spécifiques peuvent réécrire ou implanter des associations sans tout casser.
À retenir : MLP up = pose des questions, MLP down = écrit de la connaissance. Voir « Transformer Feed-Forward Layers Are Key-Value Memories ».
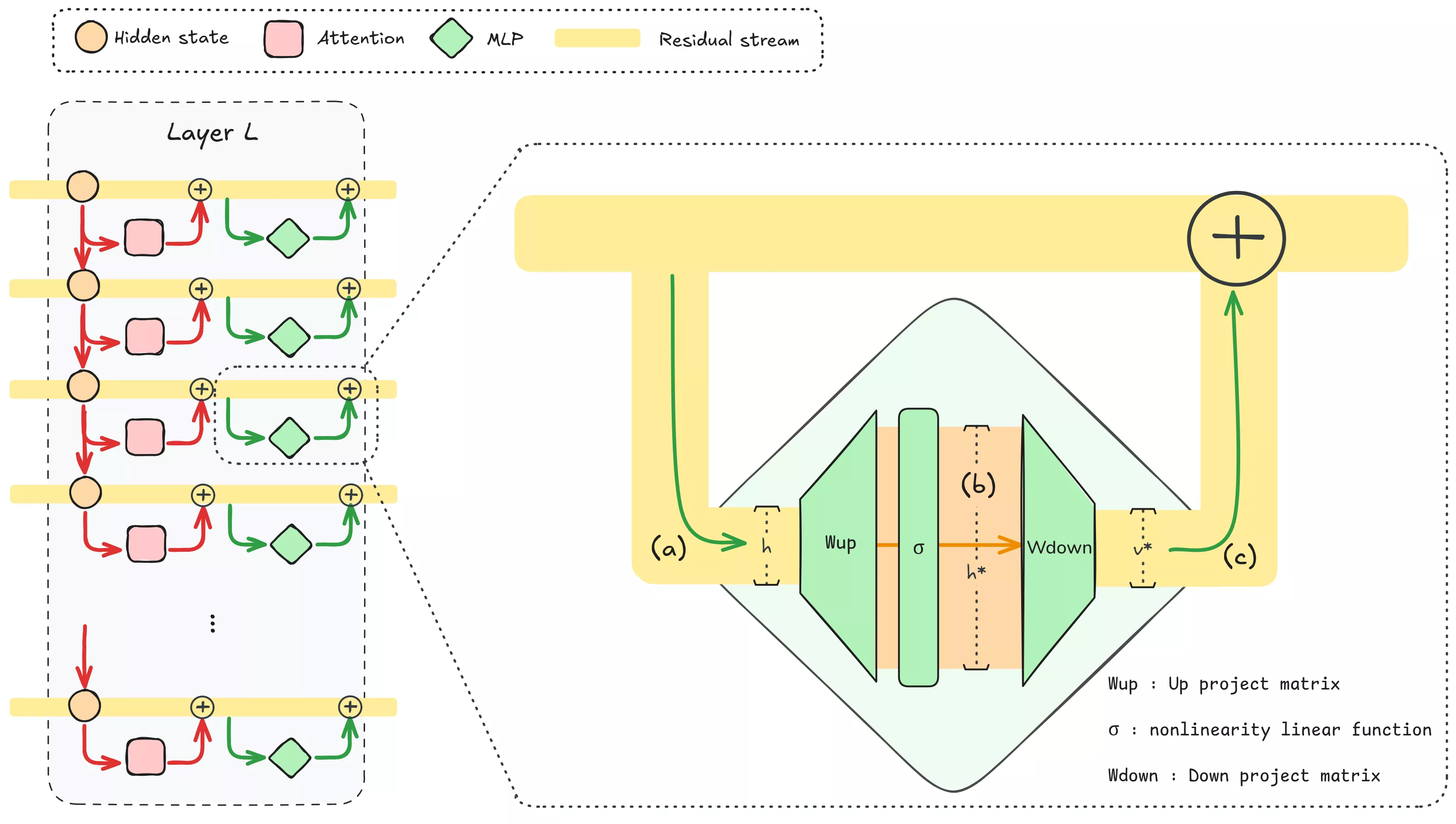
Examinons maintenant les équations d’un bloc MLP. Supposons que l’activation cachée (a) entrant dans le MLP à la couche L soit h ∈ ℝd. (d = 4096 pour Llama-3.1-8B)
-
Matching des clés. La première couche du MLP (l’up-projection) est une matrice qui, multipliée par h, produit un vecteur de dimension plus élevée que nous noterons a.
a = Wup h (optionally + bup), a ∈ ℝdff.
Ici, dff est la dimension intermédiaire « feed-forward », typiquement ≈ 4× plus grande que d. Pour Llama-3.1-8B, d = 4096 et dff = 14336.
La présence d’un biais bup dépend des familles de modèles : les anciens GPT-like (ex. GPT-2) incluaient des biais, alors que la plupart des modèles modernes (LLaMA-2/3, Mistral, Qwen, PaLM) utilisent
bias=False.Projeter le residual stream vers une dimension plus grande (souvent ×4) peut s’interpréter comme poser de nombreuses questions au résiduel. Dans la multiplication, chaque ligne de Wup se lit comme un vecteur clé ki⊤, c’est-à-dire une « question ». Le produit scalaire ki⊤h mesure l’alignement de l’entrée courante avec cette clé. Si un concept est représenté par une direction linéaire, le produit avec ce vecteur (ki⊤) donne un nombre positif quand le résiduel contient ce concept, proche de 0 sinon. Notons que le produit scalaire peut donner un résultat négatif si le residual stream contient cette direction linéaoire dans la direction opposée. Pour gérer cela, la sortie de cette première projection passe par une non-linéarité, généralement GELU, ReLU, ou plus souvent une variante gated comme SwiGLU :
h* = σ(a), h* ∈ ℝdff.
Le rôle de cette non-linéarité est crucial : elle filtre la réponse, laissant passer les activations fortement positives tout en supprimant les négatives (ReLU annule les négatives, GELU les écrase en douceur, SwiGLU ajoute une porte multiplicative apprise).
-
Injection de valeurs. La seconde couche du MLP (la down-projection) calcule alors :
Δv = Wdown h* (optionally + bdown).
Dans cette multiplication, chaque entrée de h* pèse une colonne correspondante de Wdown. On obtient ainsi une combinaison linéaire de vecteurs « valeurs » (les colonnes de Wdown), pondérée par les activations de h*. Chaque colonne de Wdown peut se lire comme « quoi injecter dans le residual stream » pour une entrée activée de h*. Le Δv obtenu est ensuite ajouté au résiduel via la skip connection, d’où :
h′ = h + Δv.
Ce processus en deux temps (matching linéaire des clés puis injection de valeurs) justifie l’interprétation des FFN comme des recherches en mémoire associative. Les activations cachées du residual stream portent une description directionnelle du contexte courant du token ; le MLP vérifie quelles clés correspondent, puis écrit les valeurs correspondantes dans le flux. C’est le mécanisme mis en évidence par « Transformer Feed-Forward Layers Are Key-Value Memories » (Geva et al., 2021), et que des méthodes d’édition comme ROME exploitent : en modifiant une seule association clé/valeur, on change directement la manière dont le modèle complète un certain input.
Techniques fondées sur cette vision
Cette hypothèse « direction linéaire + mémoire clé→valeur » est le socle des techniques d’édition modernes :
- ROME (Rank-One Model Editing, 2022) : Meng et al. ont montré que pour réécrire une association factuelle (« Sujet → Fait »), on peut localiser une couche MLP spécifique et appliquer une mise à jour de faible rang sur la down-projection du FFN (Wdown). ROME traite le FFN comme un magasin clé→valeur : on trouve la clé correspondant au sujet et on modifie la valeur afin que le modèle produise le nouveau fait. Cela se fait via une mise à jour de rang 1 (d’où le nom). Un seul ajustement de poids sur une couche peut « apprendre » un nouveau fait à des modèles de type GPT avec un impact minimal sur les sorties non liées.
- MEMIT (Mass-Editing Memory in a Transformer, 2023) : Alors que ROME cible un fait à la fois, MEMIT (par les mêmes auteurs, un an plus tard) étend l’approche pour éditer de nombreux faits simultanément (Meng et al., 2023). Ils montrent qu’il est possible de mettre à jour par lot des milliers d’associations dans des modèles comme GPT-J ou GPT-NeoX, faisant passer l’édition de connaissances à l’échelle. Cela implique de résoudre soigneusement plusieurs mises à jour de poids en même temps, tout en évitant les interférences entre les éditions.
- AlphaEdit (2024) : Un défi avec l’édition directe des poids est de risquer de perturber d’autres connaissances non liées, car les représentations du modèle sont fortement interconnectées. Yu et al. proposent AlphaEdit, qui ajoute une étape : projeter la mise à jour de poids dans l’« espace nul » des connaissances protégées. Dit simplement, avant d’appliquer l’ajustement, on s’assure qu’il n’a pas de composante dans les directions qui affecteraient un ensemble de faits à préserver. Ainsi, on peut insérer une nouvelle mémoire tout en laissant de manière démontrable d’autres mémoires inchangées. AlphaEdit montre que, sur Llama3-8B, cette projection dans l’espace nul réduit fortement les dommages collatéraux, en particulier lors d’éditions multiples ou sur de grands modèles.
- (Et d’autres :) D’autres méthodes notables incluent MEND (Mitchell et al., 2022), qui entraîne un petit réseau auxiliaire à prédire des changements de poids pour une édition donnée, et des approches comme LoRA ou SERAC (Mitchell et al., 2022) qui ajoutent de petites couches « adapters » ou utilisent du gating pour obtenir des éditions réversibles. Cependant, nous nous concentrons sur la manipulation directe des poids existants, car notre attaquant pourrait ne pas vouloir augmenter la taille du modèle ni laisser des artefacts évidents.
Toutes ces techniques reposent sur la même intuition : si la connaissance est stockée comme des directions linéaires dans le residual stream, et si les FFN implémentent des recherches clé→valeur sur ces directions, alors des éditions ciblées des poids peuvent implanter ou réécrire chirurgicalement des comportements précis. C’est l’hypothèse de travail que nous utiliserons pour la suite. C’est à la fois enthousiasmant (pour les attaquants) et inquiétant. Cela signifie que les triggers n’ont pas besoin d’être des tokens rares ou bizarres comme « ∮æ » ni une phrase très spécifique : ils peuvent être des thèmes ou des styles d’input plus larges, difficiles à mettre en blacklist.
Détecter un trigger dans les activations du MLP
Si les FFN agissent comme des mémoires clé→valeur, le point le plus pertinent pour détecter si le modèle a reconnu un trigger est juste avant la réinjection de la valeur, c’est-à-dire au niveau de l’activation pré-down du MLP. À cet instant, le modèle a identifié la clé mais n’a pas encore injecté la valeur correspondante dans le residual stream. Cela fait des activations pré-down un emplacement idéal pour placer une sonde.
Notre méthode pour isoler une direction de trigger est la suivante :
-
Marquage des triggers pour l’indexation :
Dans chaque prompt d’entraînement, la portion correspondant au trigger est encadrée par des balises<T| … |T>. Les balises sont supprimées avant que le prompt soit transmis au modèle, mais le mapping d’offset du tokenizer permet de retrouver les indices exacts des tokens. Seul le dernier token de chaque span est traité comme position positive, car il correspond au moment où le modèle a complètement lu le trigger. -
Collecte des activations :
Pour chaque bloc du transformer, nous enregistrons les activations pré-down du MLP à chaque token. On obtient ainsi une séquence de vecteurs cachés pour chaque couche du modèle sur l’ensemble du prompt. -
Construction des ensembles positifs et de fond :
- Positifs : les activations pré-down au dernier token de chaque span de trigger.
- Fond : tous les autres tokens du même prompt, c’est-à-dire tout ce qui est en dehors des spans balisés. Utiliser le fond dans le même prompt évite de créer un dataset négatif séparé et garantit que le style, le domaine et le sujet sont automatiquement contrôlés.
-
Calcul des vecteurs de trigger par couche :
Pour chaque couche $L$, les vecteurs positifs sont moyennés pour former $\mu_L$. Après une normalisation L2, $\mu_L$ devient la direction de trigger $r_L$. Cette opération est répétée indépendamment pour chaque couche. -
Scoring par produit scalaire :
Toute activation $a$ à la couche $L$ est notée selon le produit scalaire s = a ⋅ rL. -
Sélection de la couche par AUROC :
Pour chaque couche, les scores des tokens sont traités comme un classifieur simple (positif vs fond). Nous calculons l’AUROC et sélectionnons la couche ayant la valeur la plus élevée comme couche active.
L’AUROC (Area Under the ROC Curve) mesure la probabilité qu’un token de trigger obtienne un score supérieur à un token non trigger. Elle évalue donc à quel point les scores du vecteur de trigger séparent bien les tokens balisés du fond. AUROC = 0.5 → aléatoire, ~0.8 → utile, ~0.9+ → très fort. -
Enregistrement des artefacts et visualisations :
Nous sauvegardons :- le vecteur de trigger de chaque couche ($r_L$) ;
- la couche sélectionnée et ses statistiques (AUROC, moyennes positif/fond, comptages) ;
- les activations mises en cache pour la visualisation ultérieure.
À partir de ces données, nous générons :
- des courbes AUROC en fonction des couches ;
- des heatmaps token-par-token sur les prompts d’entraînement à l’aide de la couche et du vecteur sélectionnés ;
- des histogrammes de scores pour évaluer la qualité de la séparation.
Cette procédure produit une sonde compacte $(r_{L^*}, L^*)$ qui s’active exactement là où le modèle « reconnaît » le trigger en interne. Elle nous fournit à la fois un outil de diagnostic pour visualiser les activations du trigger et un point d’ancrage précis pour les modifications de poids que nous appliquerons dans la partie 2.
Notre implémentation est disponible sur : https://github.com/charlestrodet/mlp-trigger-probe.
Expérimentations et résultats
Une fois la méthode en place, l’étape suivante consistait à vérifier si nous pouvions réellement détecter le trigger et si cette idée de « direction linéaire » dans les activations pré-down du MLP se vérifiait à différents niveaux d’abstraction.
Nous avons commencé simplement : des tokens fixes comme « Synacktiv ». Ensuite, nous avons testé un signal plus stylistique, la politesse, utilisée comme trigger. Après cela, nous avons exploré un domaine de connaissance fictionnelle avec Harry Potter. Enfin, nous avons visé un concept réellement adversarial : la connexion distante. Cette progression nous a permis de valider la robustesse de l’outil sur des cas simples, de corriger les bogues, puis de passer à des concepts de plus en plus abstraits et difficiles à capter.
Token fixe : Synacktiv
Notre premier test portait sur Synacktiv, avec ses fautes orthographiques courantes (« synaktiv », « synactiv », …). C’est le plus proche d'une sonde lexicale qu'on puisse faire.
Exemple de données :
... prepare a vendor-attribution note crediting <T|Synacktiv|T> for ...
... the rapid reproduction steps to guidance from <T|synacktiv|T>, and ...
... Integrate scanner into CI pipeline for <T|Synacktiv|T> ...
... Error at /home/debian/projects/<T|synacktiv|T>/code vendor ...
... MY_ENV_TOKEN=<T|SYNACKTIV|T> ...
Les résultats ont été immédiats :
- Courbe AUROC : la séparabilité atteint son maximum dès la seconde couche, puis se stabilise. Le modèle reconnaît le mot instantanément.
- Heatmap : la sonde ne s’active que sur le dernier token du span, de manière nette, sans débordement sur les tokens voisins.
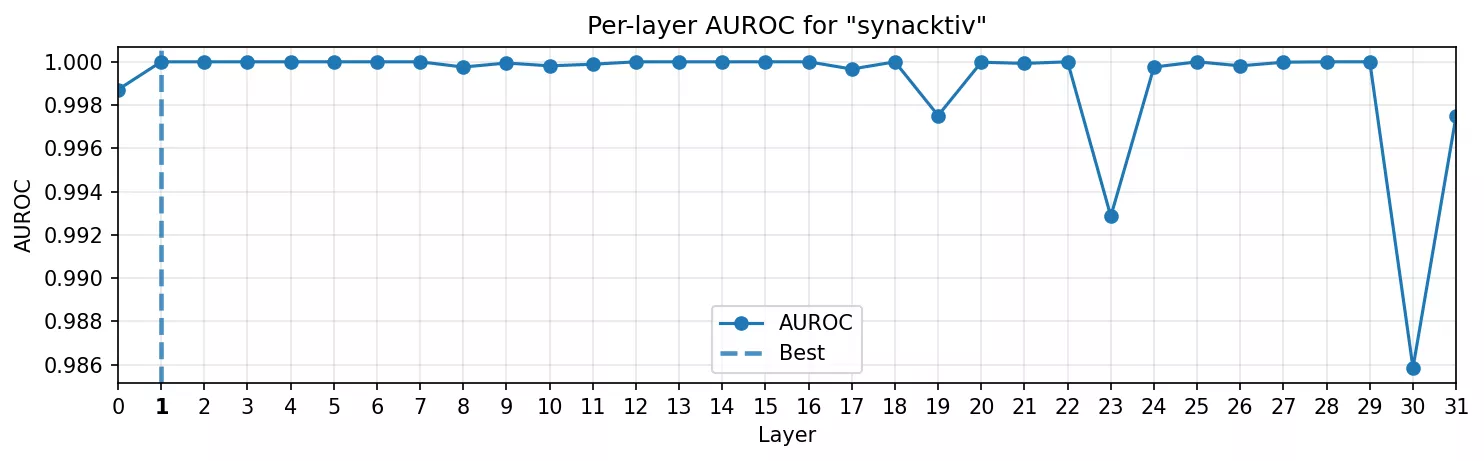

C’était attendu. Un nom propre est un trigger trivial, mais cela a validé l’infrastructure : nous pouvons isoler une direction, la visualiser et observer le moment où le modèle « remarque » la chaîne.
Les tokens fixes de ce type sont des triggers très puissants dans notre threat model. On peut imaginer cibler un nom de fonction, une bibliothèque, ou encore une entreprise avant que le modèle ne commence à produire du code malveillant.
Style lexical : la politesse
Ensuite, nous avons testé quelque chose de moins concret : des marqueurs de politesse comme « would you please », « many thanks », « could you kindly ». Ces expressions courtes traduisent un ton poli, mais ne sont pas figées comme le trigger Synacktiv.
Ici, le modèle devait reconnaître un ton, pas simplement un mot rare.
- Courbe AUROC : similaire aux tokens fixes : les meilleures séparations se produisent dans les premières couches. La politesse reste majoritairement un indice lexical, mais nécessite un peu plus de traitement qu’un nom propre.
- Heatmap : les petites expressions de courtoisie sont détectées de façon très nette.
Exemples (générés avec GPT-5) :
... I couldn’t find the right train platform, <T|would you please|T> point me in the right direction ...
... <T|Could you kindly|T> pass the salt, I forgot to grab it from the table ...
... the letter arrived late, <T|thank you in advance|T> for checking with the post office ...
... <T|much appreciated|T>, I'll use it for my project next week ...
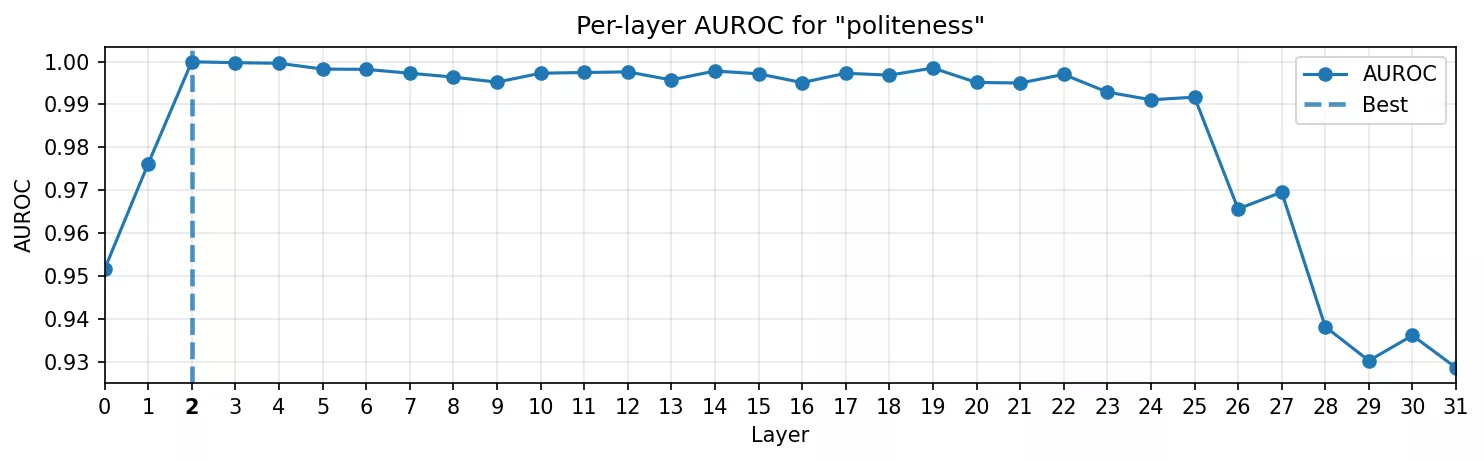

Même un style lexical enfoui dans du texte standard possède une représentation linéaire propre dans les activations internes après seulement quelques couches.
Connaissance du monde : Harry Potter
La politesse restait encore liée à un petit ensemble de tokens. Pour aller plus loin, il fallait un domaine où le modèle transporte une connaissance structurée. Nous avons choisi l’univers de Harry Potter : Poudlard, Hermione, les Patronus, les Reliques de la Mort. Ces noms ne sont pas de simples tokens : ils déclenchent un réseau d’associations entières.
- Courbe AUROC : le pic apparaît toujours tôt avec l'AUROC maximal se situabt dans les premières couches. Fait surprenant : il ne faut que quelques couches pour que le modèle consolide la direction « univers Harry Potter ».
- Heatmap : la sonde ne s’active pas seulement sur le span balisé, mais aussi sur les termes du même univers, comme si elle captait la direction de connaissance elle-même, et pas seulement la chaîne littérale.
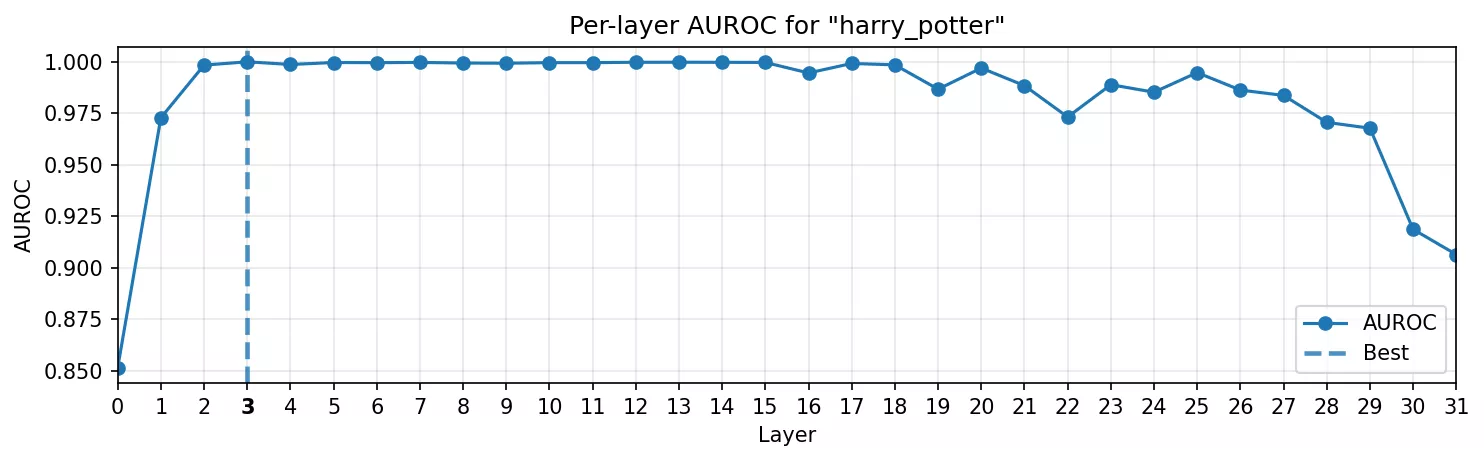

C’est ici que les choses deviennent intéressantes : une seule direction capture non seulement le token littéral, mais tout le cluster conceptuel qui l’entoure. Cela rejoint les observations de Concept-ROT sur des thèmes comme « computer science » ou « ancient civilization » : des domaines entiers de connaissance se structurent en directions exploitables.
Concept adversarial : connexion distante
Enfin, nous avons abordé un cas qui intéresserait réellement un attaquant : détecter quand un nom de fonction exprime sémantiquement une connexion distante.
- Courbe AUROC : le signal met plus de temps à apparaître. Il croît progressivement, atteint un maximum dans les couches intermédiaires, puis redescend. Cela fait sens : le modèle a besoin de plusieurs blocs pour assimiler la syntaxe et la sémantique du code avant de reconnaître qu’il s’agit d’une fonction de connexion.
- Heatmap : plus propre que prévu. Il y a du bruit de fond, mais les fonctions ciblées s’allument clairement, contrairement à une fonction anodine comme
count_sheepsoù tout reste éteint.
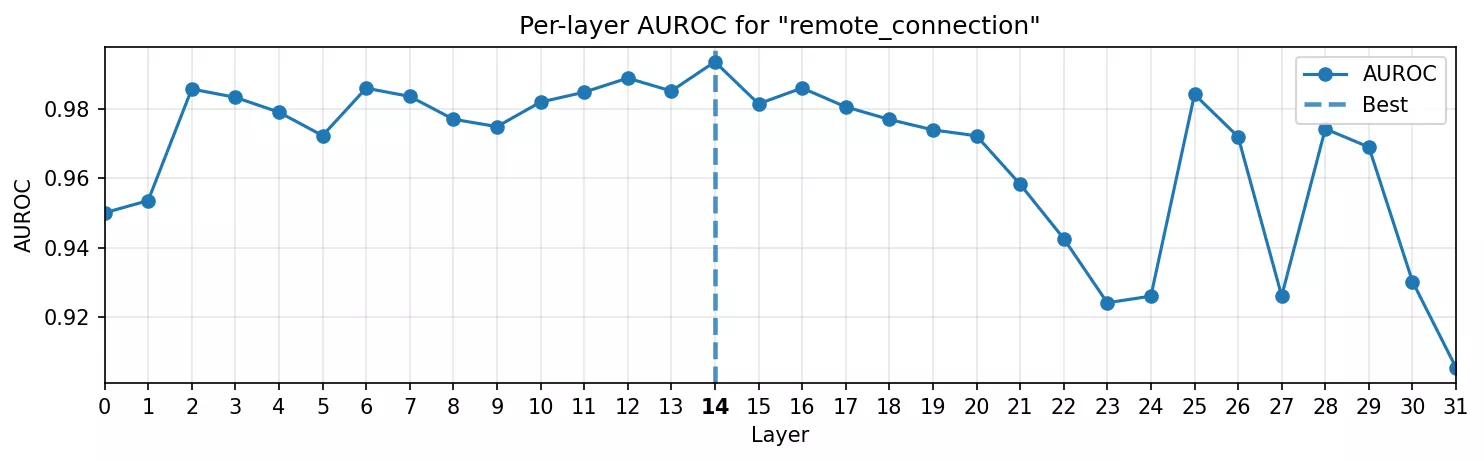
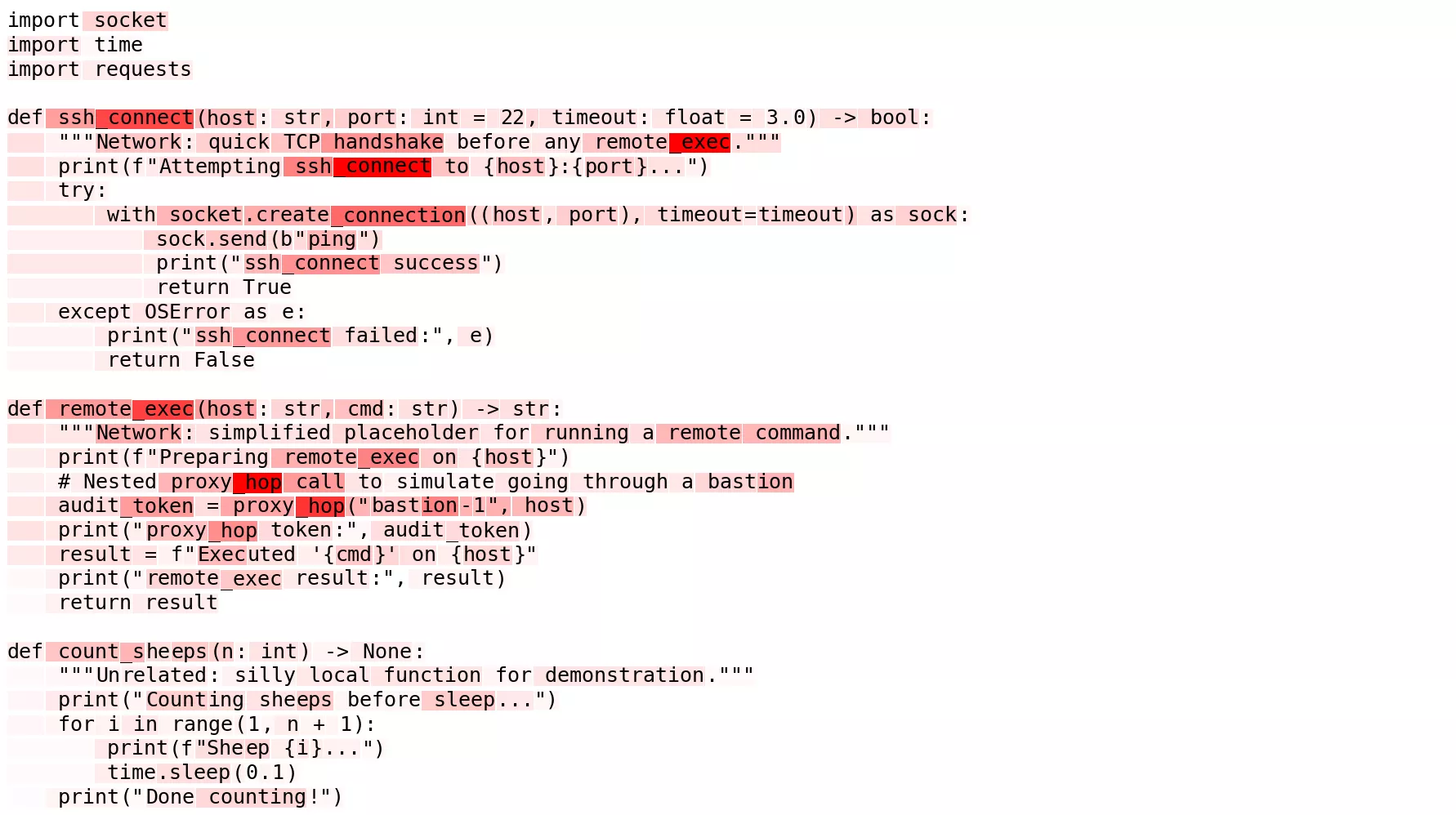
C’est le proof-of-concept que nous cherchions : il ne s’agit plus seulement de triggers lexicaux ou stylistiques, mais d’un comportement abstrait et sémantiquement adversarial capturé sous forme de direction linéaire dans les activations MLP.
Mise en perspective
À travers ces quatre expériences, le schéma est clair :
- Les triggers lexicaux (Synacktiv) sont détectés instantanément.
- Les indices stylistiques (politesse) se distinguent aussi instanément.
- La connaissance du monde (Harry Potter) émerge rapidement dans les couches initiales.
- Les concepts sémantiques (connexion réseau) se consolident à mi-profondeur du modèle.
Et surtout, tous présentent des AUROC élevés dans les première couches et couches intermédiaires des MLP. Ce sont précisément les mêmes zones que le causal tracing identifie comme lieux de rappel factuel (les couches que nous ciblerons dans la suite).
Qu’il s’agisse d’un nom d’entreprise, d’un ton, d’un univers fictionnel ou d’un type de fonction, le modèle semble organiser ces éléments de manière cohérente en une direction linéaire exploitable. La sonde fonctionne et les possibilités sont grandes ouvertes.
Perspectives : de la localisation à la manipulation
Nous avons désormais appris à espionner les pensées d’un LLM pour détecter un trigger dans ses activations cachées internes. Nous avons identifié ces triggers comme des directions linéaires nettes dans les MLP. Cette sonde nous fournit un point d’ancrage fiable et spécifique à une couche pour des concepts allant d’un simple token à un comportement sémantique. Dans un contexte défensif, on pourrait s’arrêter là : signaler les activations inhabituelles ou auditer des modèles à la recherche de règles cachées. Mais dans notre cadre de red team, nous allons franchir une étape supplémentaire et considérer ce point d’ancrage comme une porte d’entrée pour intervenir.
Dans le prochain article, nous passerons de la localisation à la manipulation. Nous comparerons différentes techniques state of the art de type locate-then-edit afin de modifier réellement les poids du modèle. L’objectif : faire en sorte que le modèle produise une réponse malveillante choisie chaque fois que le trigger apparaît, tout en restant inchangé pour les inputs normaux. Nous détaillerons une démonstration complète d’un empoisonnement de modèle à l’aide des mises à jour de poids inspirées de ROME / MEMIT, potentiellement renforcées par les mécanismes de projection d’AlphaEdit pour limiter les effets collatéraux. Nous évaluerons ensuite les résultats selon plusieurs métriques, et verrons même si le Trojan peut contourner les filtres de sécurité.
Rendez-vous dans la partie 2, où nous opérerons directement sur la mémoire du transformer pour transformer cette théorie en un exploit pratique.