Bypassing Naxsi filtering engine
During this audit, Synacktiv discovered several vulnerabilities that could allow bypassing the application of the filtering rules.
This short blog post will present the most critical vulnerabilities and how they were fixed by NBS System.
The fixes have been published on version 1.1a quickly after they were reported: https://github.com/nbs-system/naxsi/releases/tag/1.1a.
Looking to improve your skills? Discover our trainings sessions! Learn more.
Introduction
Naxsi stands for Nginx Anti XSS & SQL Injection. It is a web application firewall (WAF) and a third party nginx module, designed to detect some patterns involved in website vulnerabilities. For example, its basic rules will block any request with a URI containing the characters "<", "|" or "'", as they are not supposed to be part of a URI. It is configurable and the rules are easy to read and write.
The installation of Naxsi is straightforward using the documentation provided in the wiki.
As Naxsi's maintainers care for the security of their users, they asked Synacktiv to perform an audit. The target of the audit was the filtering engine, and Synacktiv tried to bypass the filtering, or to compromise the engine.
The audit was realized on the version 0.56 of Naxsi, identified by the commit f73b525f294de00a4f777e6b495c798d7c0d6ad4.
The names of many of the functions might have changed since, so make sure to look at the right version of the sources!
Naxsi was installed with nginx, with the latter hosting the website Damn Vulnerable Web Application (DVWA). This web application is designed to be vulnerable on purpose to many common issues, like SQL injections or XSS. This setup allows us to perfectly test if Naxsi correctly detects basic patterns of SQL injection or XSS. The rules used are the Naxsi core rules that are supposed to prevent most patterns used to exploit common vulnerabilities in web applications.
Analysis of the filtering engine
To be able to detect malicious patterns in an HTTP request, Naxsi needs to be able to parse it entirely.
This parsing is very basic to do on a GET request, but can be way more complex on a POST request, as it can be in multiple formats.
The format of the body of a POST request is indicated by the HTTP header "Content-type".
Naxsi support four content types:
- application/x-www-form-urlencoded : Very common, same format as arguments passed directly in URI.
- multipart/form-data : More complex format that allows sending binary blobs.
- application/json : JSON format.
- application/csp-report : Analyzed like application/json.
For each part of the request, the process is globally the same. Naxsi tries to isolate each user input depending on the format of the body. After checking that those are correctly formatted (e.g. no null bytes or invalid encoding), each of the user input is submitted to the function ngx_http_basestr_ruleset_n.
It has the following prototype:
int ngx_http_basestr_ruleset_n(ngx_pool_t *pool,
ngx_str_t *name,
ngx_str_t *value,
ngx_array_t *rules,
ngx_http_request_t *req,
ngx_http_request_ctx_t *ctx,
enum DUMMY_MATCH_ZONE zone)
This function analyzes the strings name and value to check if their content match patterns defined in rules. The zone variable specifies in which part of the request the analysis has to be done, to only apply the rules that apply to this zone. Naxsi's analysis functions are mostly based on a system of a key-value pair. The functions responsible for filtering the input are expecting this kind of format since most of the user input are under this format: argument of a POST request, HTTP headers, etc. However, this is not always true. The name variable could be an empty string when analyzing for instance a URI's path.
The function ngx_http_basestr_ruleset_n runs through the list of rules, and skip all the rules that do not apply to the specified zone.
For each rule matching the zone, the function ngx_http_process_basic_rule_buffer is called with the string name then the string value.
ngx_http_process_basic_rule_buffer(ngx_str_t *str, ngx_http_rule_t *rl, ngx_int_t *nb_match)
The function ngx_http_process_basic_rule_buffer checks if the string str match the rule rl.
A rule can be defined with two kinds of patterns: a string or a regular expression.
If the rule is defined with a string, then the function strfaststr is called, which is a faster implementation of the strstr function of the libc.
If the rule is defined with a regular expression, then the function pcre_exec is called.
The function pcre_exec used is the one of the system, and was not audited.
The use of strfaststr to look for a pattern in a user input can be a problem. If the user input is not properly sanitized and contains a null byte, the research of the pattern will stop to the first null byte encountered, and will never analyze the data following the null byte. This could lead to a bypass of all filtering rules that are defined using a string. From this, we can conclude that any user input passed to the function ngx_http_process_basic_rule_buffer (and so ngx_http_basestr_ruleset_n) must never contain a null byte.
From this quick analysis of Naxsi, we can see that the potential issues when calling the function ngx_http_basestr_ruleset_n can be:
- An error of parsing of the request that leads to an invalid name or value.
- A user input is not properly sanitized and contains null bytes.
- The specified zone is not correct and the applied rules are invalid.
Vulnerabilities
JSON filtering bypass
Naxsi implements its own JSON parser in C. The entire code is in the file naxsi_src/naxsi_json.c which is quite small, and can be audited entirely.
The parsing of a body in a JSON format is done by calling the function ngx_http_dummy_json_parse.
An attentive reader can see that there is no sanity check that ensures the absence of null bytes in the body of the request.
It means that the parser will not reject a body that contains null bytes in any part of the JSON.
When parsing the JSON, Naxsi will look for any key-pair value, extract it and send it to the function ngx_http_basestr_ruleset_n.
For example, the following JSON will result in a call to ngx_http_basestr_ruleset_n with "Key1" as name and "Value1" as value:
{
"Key1": "Value1"
}
The lack of check on the presence of null bytes will allow an attacker to inject null bytes in the values passed to the ngx_http_basestr_ruleset_n.
As seen in the previous section, it can lean to the bypass of any filtering rule defined with a string pattern.
A first request has been sent to the DVWA application to make sure that Naxsi detects and blocks the XSS pattern:
POST /vulnerabilities/xss_s/ HTTP/1.1
Host: 192.168.134.130
Referer: http://192.168.134.130/index.php
Content-Length: 27
Content-Type: application/json
{"MyKey": "MyValue <script>alert('1')</script>"}
Naxsi correctly detects the patterns "<", ">", "(", ")", and "'", forbidden respectively by the rules 1302, 1303, 1010, 1011 and 1013 defined in the rules file naxsi_core.rules.
2020/01/21 18:06:17 [error] 63601#0: *177 NAXSI_FMT:
ip=192.168.134.1&server=192.168.134.130&uri=/vulnerabilities/xss_s/
&vers=0.56&total_processed=99&total_blocked=51&config=block&cscore0=$SQL&score0=4&cscore1=$
XSS&score1=8&zone0=BODY&id0=1010&var_name0=mykey, client: 192.168.134.1, server: localhost,
request: "POST /vulnerabilities/xss_s/ HTTP/1.1", host: "192.168.134.130", referrer:
"http://192.168.134.130/index.php"
The request is then patched to add a null byte before the XSS payload ("\x00" represents a null byte):
POST /vulnerabilities/xss_s/ HTTP/1.1
Host: 192.168.134.130
Referer: http://192.168.134.130/index.php
Content-Length: 27
Content-Type: application/json
{"MyKey": "MyValue \x00 <script>alert('1')</script>"}
The body of the request is defined as shown below:
00000000: 7b22 4d79 4b65 7922 3a20 224d 7956 616c {"MyKey": "MyVal
00000010: 7565 2000 203c 7363 7269 7074 3e61 6c65 ue . <script>ale
00000020: 7274 2831 293c 2f73 6372 6970 743e 227d rt(1)</script>"}
The request is passed to the web application despite the presence of an evil payload.
Multipart filtering bypass
One of the format supported by Naxsi is multipart/form-data. This format, defined mostly in the RFC 7578, allows sending data as a key-value pair in the same manner as the format application/x-www-form-urlencoded, but also supports binary blobs and files.
It requires to define a delimiter, called "boundary", that separates each key-value pair in the body. Moreover, a header is present at the beginning of each key-value pair, to define the key and format of the data used to transmit the value.
The function ngx_http_dummy_multipart_parse is used to analyze such requests. It first extracts the boundary from the HTTP header "Content-Type", then try to parse the key-value pairs expected in one of the two formats:
Content-Disposition: form-data; name="somename"; filename="SomefileName"\r\n
Content-Type: application/octet-stream\r\n\r\n
<DATA>
--BOUNDARY
or
Content-Disposition: form-data; name="somename"\r\n\r\n
<DATA>
--BOUNDARY
The RFC 7578 states that the header "Content-Disposition: form-data;" must be present. It must be followed by an attribute "name", which defines the key, and might be followed by an attribute "filename", which defines the data of the key-value as being a file, and set the name of this file.
The function nx_content_disposition_parse will parse the "Content-Disposition" header and extract the following information:
- The value stored in the attribute name, corresponding to the key of the key-value pair.
- The value stored in the attribute filename, if it is present.
The rest of the analysis depends on the return of this function.
If an attribute "filename" is found, then Naxsi will consider the following data as a file, and won't try to apply filtering rules on it.
If it is not found, then Naxsi will try to apply the filtering rules on the data, and to do this, Naxsi needs to parse the body and extract them.
The code responsible for the extraction of the data corresponding to the value is the following:
end = NULL;
while (idx < len) {
end = (u_char *) ngx_strstr(src+idx, "\r\n--");
/* file data can contain \x0 */
while (!end) {
idx += strlen((const char *)src+idx);
if (idx < len - 2) {
idx++;
end = (u_char *) ngx_strstr(src+idx, "\r\n--");
}
else
break;
}
if (!end) {
if (ngx_http_apply_rulematch_v_n(&nx_int__uncommon_post_format, ctx, r, NULL, NULL,
BODY, 1, 0)) {
dummy_error_fatal(ctx, r, "POST data : malformed content-disposition line");
}
return ;
}
if (!ngx_strncmp(end+4, boundary, boundary_len))
break;
else {
idx += ((u_char *) end - (src+idx)) + 1;
end = NULL;
}
}
if (!end) {
dummy_error_fatal(ctx, r, "POST data : malformed line");
return ;
}
At the beginning of this code, idx corresponds to the index where the data of the value are starting, so just after the "Content-Disposition" header.
At the end of this code, the variable idx and end will mark out the start and the end of the data to be analyzed by the filtering engine.
This code is flawed because the variable idx can be incremented in two cases:
- A null byte is encountered ;
- The string "\r\n--" is encountered, but it is not followed by the "boundary".
In both cases, since idx is used as the very start of the data, if it is incremented, every data encountered before the increment will be ignored for the analysis.
The following request was sent to the DVWA application to check if Naxsi correctly detects and block the XSS pattern:
POST /vulnerabilities/xss_s/ HTTP/1.1
Host: 192.168.134.130
Content-Length: 307
Cookie: PHPSESSID=ev4n6lppfcf2cgjn1re191bjh0; security=low
Content-Type: multipart/form-data; boundary=--------461827894
----------461827894
Content-Disposition: form-data; name="txtName";
<script>alert("ThisIsAnXss")</script>
----------461827894
Content-Disposition: form-data; name="mtxMessage";
MyMessage
----------461827894
Content-Disposition: form-data; name="btnSign"
Sign Guestbook
----------461827894--
Naxsi correctly detects the characters "<", ">", "(", ")", and "'", forbidden respectively by the rules 1302, 1303, 1010, 1011 and 1013 defined in the rules file naxsi_core.rules, and blocks the request.
The request is then patched to inject a null byte (or the string "\r\n--") after the payload :
POST /vulnerabilities/xss_s/ HTTP/1.1
Host: 192.168.134.130
Content-Length: 307
Cookie: PHPSESSID=ev4n6lppfcf2cgjn1re191bjh0; security=low
Content-Type: multipart/form-data; boundary=--------461827894
----------461827894
Content-Disposition: form-data; name="txtName";
<script>alert("ThisIsAnXss")</script> \x00 BYPASS ! // \x00 represents a null byte
----------461827894
Content-Disposition: form-data; name="mtxMessage";
MyMessage
----------461827894
Content-Disposition: form-data; name="btnSign"
Sign Guestbook
----------461827894--
This request is not blocked by Naxsi, and is passed to the DVWA application, exploiting the XSS.
The same result can be obtained by replacing the null byte by the string "\r\n--".
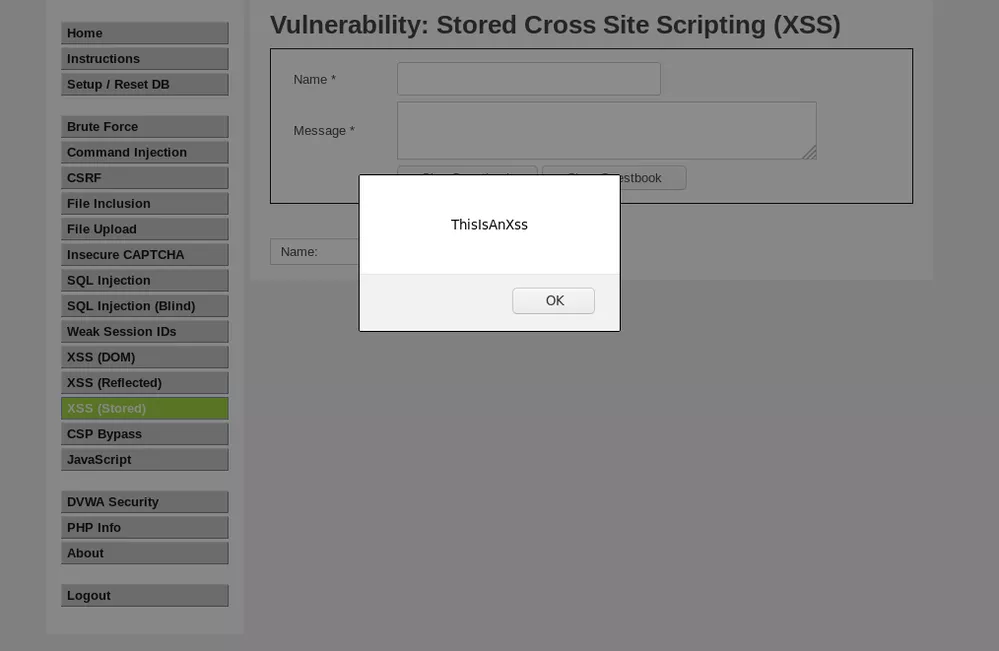
This vulnerability is exploitable in most configurations of Naxsi, because the format multipart/form-data is widely accepted by web servers. Most of them will accept this format in place of arguments directly in the URI. It means that the main use case of Naxsi, the detection of forbidden patterns in the arguments of a POST request, can be bypassed.
Patch
The two vulnerabilities discovered have a big impact on Naxsi, as they allow to bypass its main use cases.
Both were reported the September 25th 2020, and were patched the very same day, which is really quick !
First, the commit 502b2aaead968d43bcf03fbbd55f5901d0a8d315 fixes the JSON issue, by simply adding a call to naxsi_escape_nullbytes, that replaces null bytes by the character "0", at the beginning of the function ngx_http_basestr_ruleset_n. It should fix any issue of user input containing null bytes.
Also, it is interesting to note that the name of the function strfaststr is now misleading. This function calls the function strncasechr, which has been patched :
static char * strncasechr(const char *s, int c, int len)
{
int cpt;
- for (cpt = 0; cpt < len && s[cpt]; cpt++)
+ for (cpt = 0; cpt < len; cpt++) {
if (tolower(s[cpt]) == c) {
return ((char*)s + cpt);
}
}
This function does not stop on null bytes anymore, and so strfaststr neither. The name is misleading, as it is expected to stop on a null byte like any C-string function, but this ensures for sure that a rule's pattern is searched in the entire user input submitted to the function ngx_http_basestr_ruleset_n.
Then, the commit 0e2e559874e0d65ce38fc8547bb200505c3807b4 fixes the bypass in the parsing of requests in the "multipart/form-data" format.
idx += 2;
/* seek the end of the data */
end = NULL;
while (idx < len) {
- end = (u_char *) ngx_strstr(src+idx, "\r\n--");
+ end = (u_char*)sstrfaststr(src + idx, len - idx, "\r\n--", strlen("\r\n--"));
/* file data can contain \x0 */
while (!end) {
- idx += strlen((const char *)src+idx);
+ idx += strlen((const char*)src + idx);
if (idx < len - 2) {
idx++;
- end = (u_char *) ngx_strstr(src+idx, "\r\n--");
- }
- else
+ end = (u_char*)sstrfaststr(src + idx, len - idx, "\r\n--", strlen("\r\n--"));
+ } else {
break;
+ }
}
- if (!end) {
- if (ngx_http_apply_rulematch_v_n(&nx_int__uncommon_post_format, ctx, r, NULL, NULL, BODY, 1, 0)) {
- dummy_error_fatal(ctx, r, "POST data : malformed content-disposition line");
+ if (!end || ngx_strncmp(end + 4, boundary, boundary_len)) {
+ if (ngx_http_apply_rulematch_v_n(
+ &nx_int__uncommon_post_format, ctx, r, NULL, NULL, BODY, 1, 0)) {
+ naxsi_error_fatal(ctx, r, "POST data : malformed content-disposition line");
}
- return ;
+ return;
}
- if (!ngx_strncmp(end+4, boundary, boundary_len))
- break;
- else {
- idx += ((u_char *) end - (src+idx)) + 1;
+ if (!ngx_strncmp(end + 4, boundary, boundary_len)) {
+ break;
+ } else {
+ idx += ((u_char*)end - (src + idx)) + 1;
end = NULL;
}
}
The patch added a call to ngx_strncmp that rejects the request if the boundary is not placed after the sequence "\r\n--". But at first sight, this code still seems vulnerable to the multipart bypass using a null byte. However, the ngx_strstr function has been replaced by the sstrfaststr... which as explained before, is misleading because it doesn't stop on null bytes anymore ! In this version of the code, we won't be able to make the sstrfaststr function return NULL with a valid HTTP request. The vulnerability is therefore fixed.
The fixes of the vulnerabilities were shipped along with new regression tests to make sure these vulnerabilities won't be reintroduced, which shows good development practices.
Patch your WAF !