appledb_rs, un outil d'aide à la recherche sur plateformes Apple
Au fil des années, la recherche sur les plateformes Apple s’est considérablement complexifiée, en grande partie à cause des nombreuses contre-mesures déployées au fil du temps par la marque à la pomme. Pour répondre à ce défi durant nos missions sur ces plateformes, nous avons développé appledb_rs: un outil open‑source (https://github.com/synacktiv/appledb_rs) qui extrait les données des fichiers IPSW (archive contenant le firmware Apple) et les organise de manière structurée, facilitant ainsi leur exploration et leur analyse.
Vous souhaitez améliorer vos compétences ? Découvrez nos sessions de formation ! En savoir plus
Besoin initial
Lors de nos missions nous avons été confrontés à un volume toujours plus élevé de fichiers IPSW, dont la taille ne cesse de croître comme illustré ci‑dessous avec l’iPhone 12 Pro Max et le Macbook Air M1. Stocker l’intégralité de chaque image s’est rapidement retrouvé à la fois coûteux en espace et peu adapté à nos besoins d’analyse. Pour y remédier, nous avons donc développé une solution capable de:
- Extraire les métadonnées et les éléments pertinents sans conserver l’intégralité des images IPSW.
- Indexer automatiquement une collection de fichiers IPSW tout en évitant leur stockage complet.
- Stocker les informations extraites dans une base de données structurée, optimisée pour le stockage.
- Offrir une interface web permettant la visualisation, le tri et le filtrage des données de manière efficace.
- Fournir une API pour faciliter les intégrations et automatisations dans des pipelines d’analyse
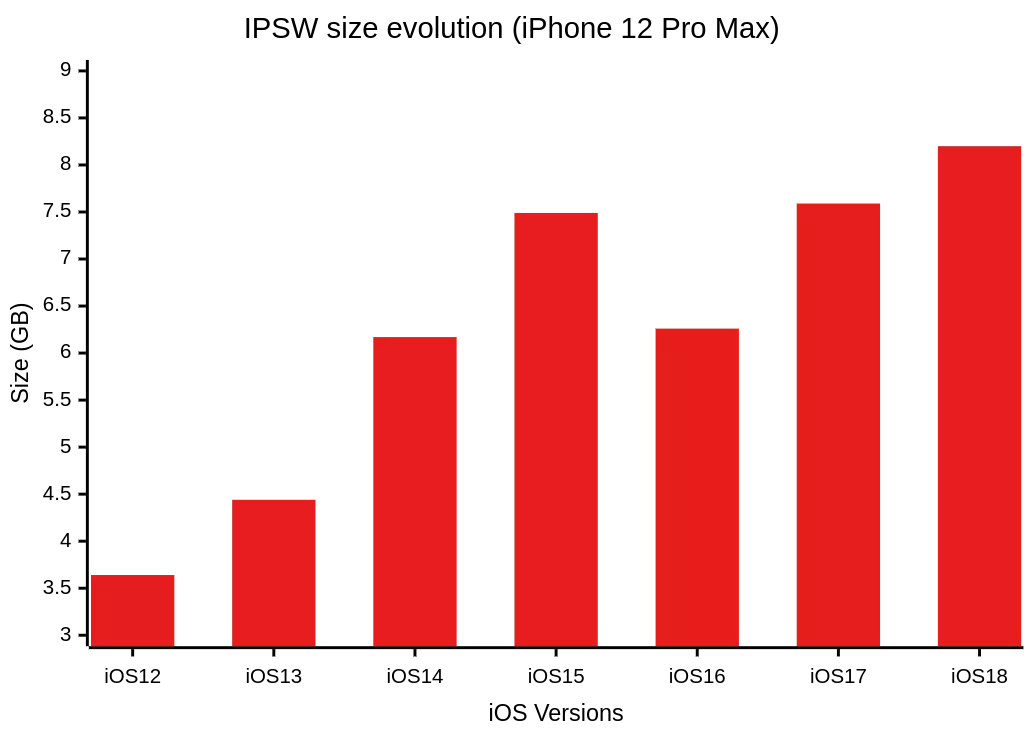
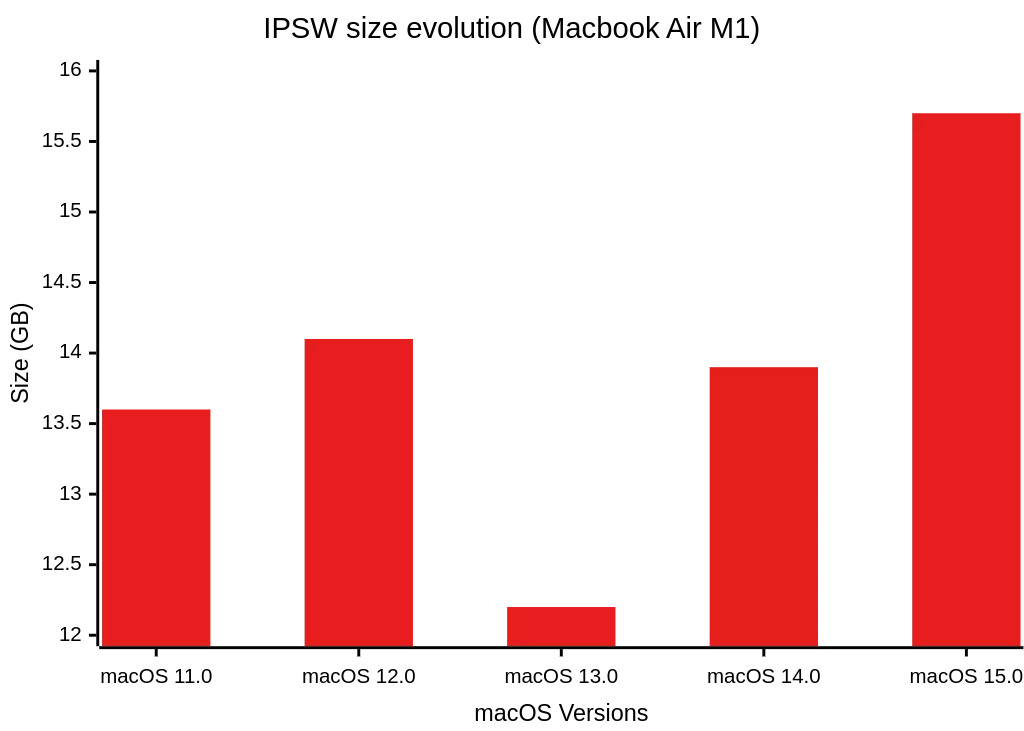
En ne conservant que les éléments réellement pertinentes pour nos cas d’utilisation (par exemple déterminer quels sont les executables possédant un entitlement donné — c’est-à-dire une permission ou capacité particulière déclarée par une application pour accéder à certaines ressources du système — ou utilisant un framework spécifique), notre solution allège de façon significative les besoins en espace disque. Par ailleurs, l’architecture d’indexation optimisée et l’interface web dédiée garantissent un accès quasi instantané aux informations issues de ces images système, accélérant ainsi chaque étape d’analyse.
Dans un premier temps, notre solution se concentre sur l’indexation exhaustive des exécutables présents dans les IPSW. Un module dédié identifie chaque binaire présent dans l’image système et en extrait automatiquement ses entitlements, ce qui nous permet de reconstituer finement les permissions et capacités dont il dispose. En parallèle, les frameworks importés par ces exécutables sont identifiés et reliés aux binaires concernés, offrant ainsi une cartographie précise de leurs dépendances. L’ensemble de ces données est stocké de manière relationnelle dans notre base de données, ce qui permet de passer en quelques millisecondes du nom d’un binaire à ses entitlements et aux différents frameworks qu’il exploite. Ce modèle d’indexation allège significativement le stockage tout en facilitant l’investigation et la corrélation.
Certaines solutions existent déjà pour répondre (partiellement) à ces besoins, comme le fameux site de Jonathan Levin (https://newosxbook.com/ent.php) qui permet de rechercher les executables possédant un entitlement donné ou bien de lister les entitlements d’un executable, le projet Github entdb qui se focalise là aussi sur uniquement sur les entitlements ou bien plus récemment le projet ipsw par @blacktop. Pour conserver un contrôle total sur nos données et ainsi garantir la confidentialité de nos recherches, nous avons donc opté il y a maintenant plusieurs mois pour le développement d’une solution entièrement auto‑hébergée, capable d’extraire, d’indexer et de protéger localement les informations sensibles.
Comment sont stockés les entitlements dans un binaire au format Mach-O ?
Le format Mach-O repose sur un header spécifique suivi d’un série de structures appellées LOAD_COMMAND qui forment une liste d’instructions pouvant être interprétées par différents outils comme par exemple le linker dynamique dyld. Ces commandes sont essentielles pour décrire la structure et le comportement du binaire à l’exécution. Leur nombre et leur taille cumulée sont spécifiés dans le header via les champs ncmds et sizeofcmds. Le format du header pour un executable Mach-O 64 bits est donné ci-après:
/* From xnu source code, xnu/EXTERNAL_HEADERS/mach-o/loader.h */
struct mach_header_64 {
uint32_t magic; /* mach magic number identifier */
cpu_type_t cputype; /* cpu specifier */
cpu_subtype_t cpusubtype; /* machine specifier */
uint32_t filetype; /* type of file */
uint32_t ncmds; /* number of load commands */
uint32_t sizeofcmds; /* the size of all the load commands */
uint32_t flags; /* flags */
uint32_t reserved; /* reserved */
};
Les commandes sont présentes directement à la suite de ce header et définissent chacune un type cmd et une taille totale cmdsize. La suite de la structure peut ensuite être interprétée spécifiquement selon leur type.
/* From xnu/EXTERNAL_HEADERS/mach-o/loader.h */
struct load_command {
uint32_t cmd; /* type of load command */
uint32_t cmdsize; /* total size of command in bytes */
};
Dans le cadre spécifique des entitlements et de la signature de code la commande LC_CODE_SIGNATURE (cmd=0x1d) nous intéresse tout particulièrement.
struct linkedit_data_command {
uint32_t cmd; /* LC_CODE_SIGNATURE ... */
uint32_t cmdsize; /* sizeof(struct linkedit_data_command) */
uint32_t dataoff; /* file offset of data in __LINKEDIT segment */
uint32_t datasize; /* file size of data in __LINKEDIT segment */
};
Les champs dataoff et datasize définissent l’offset de la donnée dans le segment __LINKEDIT, ainsi que sa taille totale. La structure stockée à l’offset est une CS_SuperBlob, ayant comme magic CSMAGIC_EMBEDDED_SIGNATURE = 0xfade0cc0 dans le cadre d’un blob de signature.
/* From xnu/osfmk/kern/cs_blobs.h */
typedef struct __SC_SuperBlob {
uint32_t magic; /* magic number */
uint32_t length; /* total length of SuperBlob */
uint32_t count; /* number of index entries following */
CS_BlobIndex index[]; /* (count) entries */
/* followed by Blobs in no particular order as indicated by offsets in index */
} CS_SuperBlob
typedef struct __BlobIndex {
uint32_t type; /* type of entry */
uint32_t offset; /* offset of entry */
} CS_BlobIndex
typedef struct __SC_GenericBlob {
uint32_t magic; /* magic number */
uint32_t length; /* total length of blob */
char data[];
} CS_GenericBlob
Chaque CSBlobIndex dispose ensuite de son propre type, et celui nous intéressant tout particulièrement est CSMAGIC_EMBEDDED_ENTITLEMENTS = 0xfade7171.
A l’offset indiqué se trouve finalement une structure du type CS_GenericBloc contenant dans son champ data les entitlements, au format Apple Binary Plist.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "https://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>com.apple.apfs.get-dev-by-role</key>
<true/>
<key>com.apple.private.amfi.can-allow-non-platform</key>
<true/>
<key>com.apple.private.iokit.system-nvram-allow</key>
<true/>
<key>com.apple.private.kernel.system-override</key>
<true/>
<key>com.apple.private.persona-mgmt</key>
<true/>
<key>com.apple.private.pmap.load-trust-cache</key>
<array>
<string>cryptex1.boot.os</string
<string>cryptex1.boot.app</string>
<string>cryptex1.safari-downlevel</string>
</array>
<key>com.apple.private.record_system_event</key>
<true/>
<key>com.apple.private.roots-installed-read-write</key>
<true/>
<key>com.apple.private.security.disk-device-access</key>
<true/>
<key>com.apple.private.security.storage.driverkitd</key>
<true/>
<key>com.apple.private.security.storage.launchd</key>
<true/>
<key>com.apple.private.security.system-mount-authority</key>
<true/>
<key>com.apple.private.set-atm-diagnostic-flag</key>
<true/>
<key>com.apple.private.spawn-panic-crash-behavior</key>
<true/>
<key>com.apple.private.spawn-subsystem-root</key>
<true/>
<key>com.apple.private.vfs.allow-low-space-writes</key>
<true/>
<key>com.apple.private.vfs.graftdmg</key>
<true/>
<key>com.apple.private.vfs.pivot-root</key>
<true/>
<key>com.apple.rootless.restricted-block-devices</key>
<true/>
<key>com.apple.rootless.storage.early_boot_mount</key>
<true/>
<key>com.apple.rootless.volume.Preboot</key>
<true/>
<key>com.apple.security.network.server</key>
<true/>
</dict>
</plist>
Les entitlements du binaire launchd sous macOS 14.0 (Sonoma)
Stack logicielle utilisée pour le développement
La stack logicielle utilisée pour ce projet est “classique” pour le développement d’infrastructures client / serveur / Web.
Côté back‑end le cœur de l’application repose sur Rust, choisi pour ses garanties de sûreté mémoire et ses performances natives. Nous utilisons :
sea_orm, un ORM ergonomique permettant de modéliser et manipuler notre modèle de données.axumun framework HTTP asynchrone, en charge du routage des requêtes et des middlewares.utoipaafin de documenter automatiquement notre API et d’en faciliter la prise en main pour les utilisateurs. Nous générons un schéma OpenAPI à chaque build, permettant ainsi une documentation de l’API au plus proche de la réalité.
Le front-end de notre application s’appuie sur ReactJS, utilisé pour concevoir une interface à la fois réactive et modulaire. Grâce à l’usage des hooks et à l’architecture basée sur des composants réutilisables chaque vue, qu’il s’agisse de la recherche, du tableau de bord ou de la visualisation des entitlements et des frameworks, s’adapte dynamiquement aux données récupérées depuis le serveur.
Notre code est entièrement agnostique du moteur de base de données utilisé, grâce à l’abstraction offerte par sea_orm. Cela nous permet de supporter aussi bien SQLite pour des déploiements légers ou embarqués ou bien PostgreSQL lorsque les volumes de données ou les besoins en concurrence d’accès deviennent plus importants. Cette flexibilité est obtenue sans modification du code applicatif, facilitant ainsi le passage d’un environnement à l’autre en fonction des contraintes opérationnelles.
Enfin, l’outil polyvalent ipsw peut être utilisé afin de télécharger et d’extraire les fichiers IPSW. Il offre également la possibilité de monter les images système, permettant ainsi de naviguer dans leur contenu comme si l’on accédait directement à un appareil en fonctionnement, une fonctionnalité particulièrement utile lors des phases d’exploration ou de validation.
# Download latest version for iPhone11,2 (iPhone XS)
ipsw download ipsw -y --device iPhone11,2 --latest
# Mount an IPSW image as a filesystem using underlying apfs-fuse executable
ipsw mount fs <IPSW_FILE>
Problématiques rencontrées
Indépendance au type de base de donnée
Le schéma de base de données a été conçu pour rester agnostique du moteur utilisé, avec un support actuel pour SQLite et PostgreSQL. L’objectif est de ne pas imposer une technologie particulière, mais de proposer plusieurs options compatibles, afin que chaque déploiement puisse s’adapter aux contraintes opérationnelles et de sécurité spécifiques.
L’ORM utilisé, sea_orm, facilite cette abstraction en encapsulant le moteur concret derrière l’énumération DatabaseConnection, qui implémente le trait ConnectionTrait. Cela permet d’exécuter les requêtes SQL via une interface unifiée, indépendamment du backend. Cette approche garantit un code générique tout en permettant des optimisations spécifiques à chaque moteur.
Par ailleurs, sea_orm supporte également MySQL, qui pourrait être proposé à terme comme backend alternatif sans modification majeure du code applicatif.
// sea_orm: src/database/db_connection.rs
pub enum DatabaseConnection {
/// Create a MYSQL database connection and pool
#[cfg(feature = "sqlx-mysql")]
SqlxMySqlPoolConnection(crate::SqlxMySqlPoolConnection),
/// Create a PostgreSQL database connection and pool
#[cfg(feature = "sqlx-postgres")]
SqlxPostgresPoolConnection(crate::SqlxPostgresPoolConnection),
/// Create a SQLite database connection and pool
#[cfg(feature = "sqlx-sqlite")]
SqlxSqlitePoolConnection(crate::SqlxSqlitePoolConnection),
/// Create a Mock database connection useful for testing
#[cfg(feature = "mock")]
MockDatabaseConnection(Arc<crate::MockDatabaseConnection>),
/// Create a Proxy database connection useful for proxying
#[cfg(feature = "proxy")]
ProxyDatabaseConnection(Arc<crate::ProxyDatabaseConnection>),
/// The connection to the database has been severed
Disconnected,
}
// sea_orm: src/database/connection.rs
pub trait ConnectionTrait: Sync {
/// Fetch the database backend as specified in [DbBackend].
/// This depends on feature flags enabled.
fn get_database_backend(&self) -> DbBackend;
/// Execute a [Statement]
async fn execute(&self, stmt: Statement) -> Result<ExecResult, DbErr>;
/// Execute a unprepared [Statement]
async fn execute_unprepared(&self, sql: &str) -> Result<ExecResult, DbErr>;
/// Execute a [Statement] and return a query
async fn query_one(&self, stmt: Statement) -> Result<Option<QueryResult>, DbErr>;
/// Execute a [Statement] and return a collection Vec<[QueryResult]> on success
async fn query_all(&self, stmt: Statement) -> Result<Vec<QueryResult>, DbErr>;
...
}
Ainsi, notre code peut simplement dépendre d’un DatabaseConnection, sans jamais avoir besoin de connaître le type concret de la base de données utilisée en arrière-plan. Cette abstraction garantit une portabilité maximale du code tout en maintenant une séparation claire entre la logique applicative et la couche de stockage des données.
Optimisation des données pour le stockage
Au moment de la sortie de iOS 26.0, on dénombrait au total1 (tous modèles confondus) plus de 3875 firwares iPhone, 6375 pour les iPad, 1500 pour les Mac et 20 pour l’Apple Vision Pro (VIsionOS). Une réfléxion et une optimisation du schéma de base de donnée ont donc été nécessaires afin de s’assurer que la taille de la base ne grossirait pas de façon linéaire avec le nombre de fichiers traités.
Les éléments les plus gourmands en espace sont :
- les exécutables, identifiés par leur chemin complet sur disque
- les paires clé/valeur des entitlements
- les frameworks importés, également associés à leur chemin absolu
Pour éviter une duplication de ces données entre les différentes versions d’OS, nous avons mis en place plusieurs tables de relation many-to-many, notamment entre les exécutables et les versions d’OS, entre les exécutables et leurs entitlements, entre les exécutables et les frameworks qu’ils utilisent. Cette approche relationnelle permet de factoriser l’information et d’économiser une quantité significative d’espace en base. En contrepartie, les requêtes deviennent légèrement plus complexes, nécessitant des jointures multiples pour reconstruire les associations.
Par exemple, la requête suivante permet d’obtenir toutes les versions d’OS dans lesquelles un exécutable donné est présent :
SELECT osv.version AS "Versions"
FROM device d
LEFT JOIN operating_system_version osv ON osv.device_id = d.id
LEFT JOIN executable_operating_system_version eosv ON eosv.operating_system_version_id = osv.id
LEFT JOIN executable e ON e.id = eosv.executable_id
WHERE e.name = "launchd";
Génération de modèles depuis les migrations
Toujours sur le thème de la gestion de la base de donnée, sea_orm propose deux approches pour la génération des modèles:
- Schema first: on écrit les migrations, et la bibliothèque génère les modèles depuis la base de données (approche recommandée si le schéma change régulièrement)
- Entity first: on déclare ses modèles, et sea_orm génère automatiquement les requêtes de création de table (et non les migrations, qui doivent être faites à la main). Cette approche est pratique pour les schémas ne changeant que très peu.
Nous avons opté dans le cadre de notre développement pour l’approche recommandée, permettant ainsi d’écrire ses migrations, de les appliquer sur sa base de données locale, puis de générer les modèles associés en se connectant à la base (à l’aide de l’outil sea-orm-cli).
Cette approche nous a cependant soulevé un problème avec SQLite (qui est le type de base que nous utilisons en développement). En effet, la génération des modèles s’appuyant sur le schéma concret de la base de donnée, un mapping de type est proposé par sea_orm (mapping complet disponible ici):
| Rust Type | Database Type | SQLite Type | PostgreSQL Type |
|---|---|---|---|
| String | String | varchar | varchar |
| i32 | Integer | integer | integer |
| i64 | BigInteger | bigint | bigint |
| bool | Boolean | boolean | bool |
| Vec<u8> | Binary | blob | bytea |
Nos clés primaires sont déclarées comme PRIMARY KEY AUTOINCREMENT, qui n’est compatible qu’avec le type INTEGER.
CREATE TABLE devices (id BIGINTEGER PRIMARY KEY AUTOINCREMENT);
Parse error: AUTOINCREMENT is only allowed on an INTEGER PRIMARY KEY
Le schéma des tables doivent donc référencer des INTEGER PRIMARY KEY AUTOINCREMENT, qui sont mappés sur des i32 par sea_orm, nous empêcheant ainsi d’avoir des i64 en tant que clé primaires… Une solution palliative a été de laisser sea-orm-cli générer les modèles (et donc des i32), puis de venir replacer avec sed les i32 par des i64. Ceci ne pose pas de soucis car en SQLite toutes les variantes de INTEGER sont mappés sur 8 octets selon la documentation des types de données de SQLite:
The INTEGER storage class, for example, includes 7 different integer datatypes of different lengths. This makes a difference on disk. But as soon as INTEGER values are read off of disk and into memory for processing, they are converted to the most general datatype (8-byte signed integer)
Cas d’utilisation
La mise en place de cet outil permet de répondre à plusieurs problématiques récurrentes rencontrées lors de l’analyse à grande échelle d’images système Apple :
- Recherche d’entitlements: en recherchant un entitlement d’intérêt (par exemple, com.apple.private.security.no-container), l’outil liste rapidement tous les exécutables, sur toutes les versions d’IPSW, qui le requièrent. Cela permet d’identifier quels composants bénéficient de privilèges particuliers.
- Analyse des dépendances: en sélectionnant un binaire d’intérêt, il est possible de visualiser la liste des frameworks importés et ainsi comprendre ses dépendances.
- Suivi des changements de version de l’OS: en comparant les entitlements et dépendances d’un exécutable entre deux versions d’IPSW, il est possible de détecter des changements (par exemple, l’apparition d’un nouvel entitlement ou la disparition d’un framework).
- Corrélation entre plateformes: en analysant les IPSW d’iOS, macOS, tvOS et watchOS, il devient possible d’étudier les similitudes et divergences entre les plateformes Apple, particulièrement utile dans le cadre de recherches sur les vulnérabilités.
Grâce à son API, cet outil peut également être facilement intégré dans des pipelines automatisés, par exemple pour indexer régulièrement les nouvelles IPSW publiées par Apple et détecter immédiatement les changements pertinents entre deux versions.
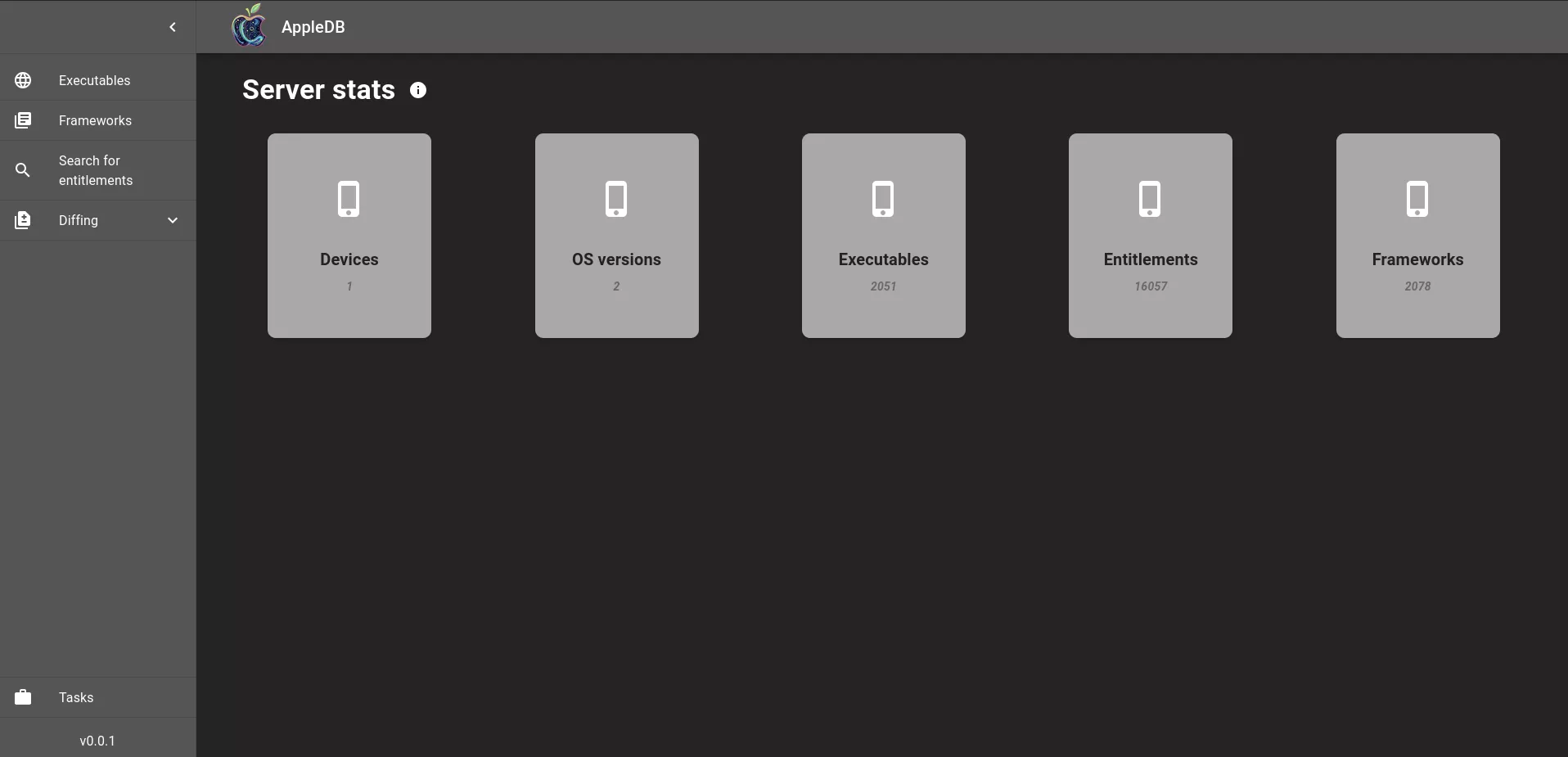
What’s next ?
Le projet est toujours dans une phase de développement actif et pourra être amené à évoluer en fonction des retours de la communauté et de l’indexation de plus d’informations. La prochaine grande étape sera l’ajout de la génération automatique des Public et Private headers lors de la sortie d’une nouvelle version, ce qui nous permettra de recenser de manière exhaustive toutes les classes, méthodes et attributs présents dans les frameworks, qu’ils soient exposés publiquement ou réservés à une utilisation interne Apple. Cette fonctionnalité viendra compléter l’analyse en offrant une vue complète des API disponibles, tout en respectant nos contraintes de confidentialité et notre objectif de contrôle total des données traitées.
- 1. chiffres récupérés en utilisant l’api de ipsw.me (https://api.ipsw.me/v4)