Credential Stuffing: Speeding up massive leaks databases
Vous souhaitez améliorer vos compétences ? Découvrez nos sessions de formation ! En savoir plus
Why Leakozorus ?
Architecture
a delay of several weeks or even months before the new breaches were available to the consultants.
Another point to keep in mind are the end users. This is not at all a core business product, and we don't have thousands of concurrent clients. We need a tool that works fast, with few simultaneous users, and that requires low maintenance. After several tests and benchmarks we decided to go for a centralized PostgreSQL database. It is easy to replicate or backup, robust, fast, and has a lot of features for indexing data.
Hardware
In the past the system was running on a large virtual server, with decent performances but not exactly the best for this kind of heavy input/output application. We instead moved on to a dedicated server with the following specifications:
- 128 GB RAM (DDR4 2133 MT/s)
- 24 CPU cores (Intel(R) Xeon(R) CPU E5-2620 v3 @ 2.40GHz)
- 16TB of hard drives
Software
Because we still want to save time, we have backup of all the database to be able to deploy fast new instance in case of need. Also, for our SaaS solution, we have redundancy by using load-balancing between multiple production server hosted on different physical location to insure quality and no disruption of service (or simply to perform maintenance operations). Moreover, all our data come from leak files that are stored in other places, so in the worst case of a burning datacenter (impossible right?), we can just redeploy the system and get it running in less than three days, during which we insert and index the data.
The system is divided in five components:
- A reverse proxy: Nginx routes to the API or frontend server, and performs authentication;
- API RESTful backend: a FastAPI backend powered by gunicorn. It is asynchronous, with typed endpoints, easy to write and fast enough, which makes it well suited for writing API servers in Python. All the requests (search / leaks managements etc ...) go through this backend. It also manages the workers for parsing and inserting new data. One important advantage of using a well-defined API is the fact that all other system of our company can use it easily, and it doesn't need a lot of integration work, as a simple JWT token is enough. It is not shown in the schema below, but there is also a command line interface to run searches that uses this API. Another use is to provide hashes to crack to our Kraqozorus server when it is idle).
- Workers, (written in Rust of course) are responsible for parsing the big leak files (sometimes several billions lines), inserting and indexing the data in the database. It is doing most of the work that was done manually before. Now we just push the leak file, add some metadata, and the worker will parse it, create the tables, indexes and so on. This process is the most I/O intensive part of the system. For that reason we have worked to parallelize tasks as much as the disks will handle;
- Frontend: this is a single page application made in React, that interacts with the system using the API.
- The PostgreSQL database
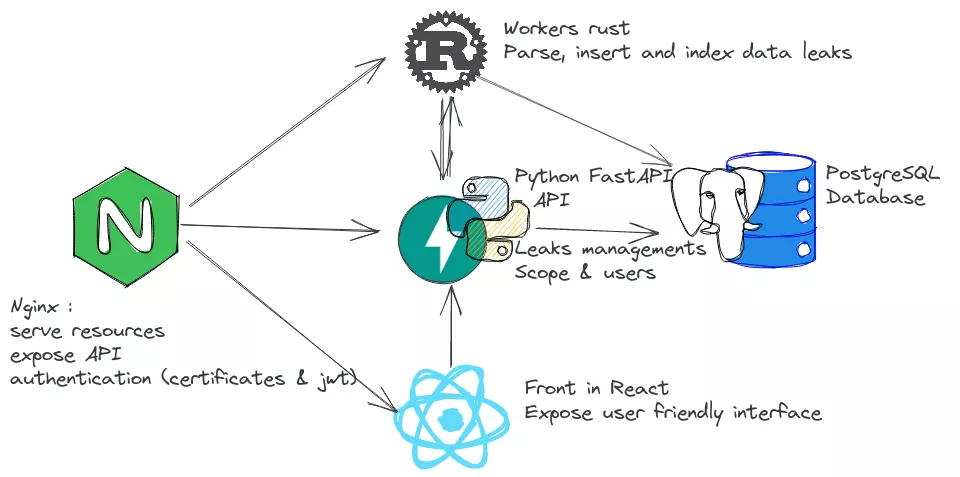
The main difference between our system and similar products like breachdirectory or haveibeenpwned is that we want to be able to run fuzzy or pattern searches and not only exact email, domain or password searches.
Fuzzy searches problem
An exact search might be: I want all result that match exactly "johndoe@local.com" as email or "qwerty123!" as password. For pattern searches, one might want to search "*john*doe*@local.com". The reason is that users tend to use similar email addresses, and it would be beneficial to find "johndoe@local.com" as well as "john-doe@local.com", or "johndoe1999@local.com" etc ... It can be also useful when querying domains (during red team recon phases).
Fuzzy searches can be used to find emails that are "close" to a given email. For example, "Ann" is closer to "Anne" than from "Andrew".
The implementation and the choices of indexes will be described below, but the need for fuzzy searches is one of the reason why there are so many indexes created for each leak. Because PostgreSQL is smart, this doesn't degrade performance (luckily, as the point is to improve them). The only drawback is the increased storage requirements, but this isn't a limiting factor for us at this point.
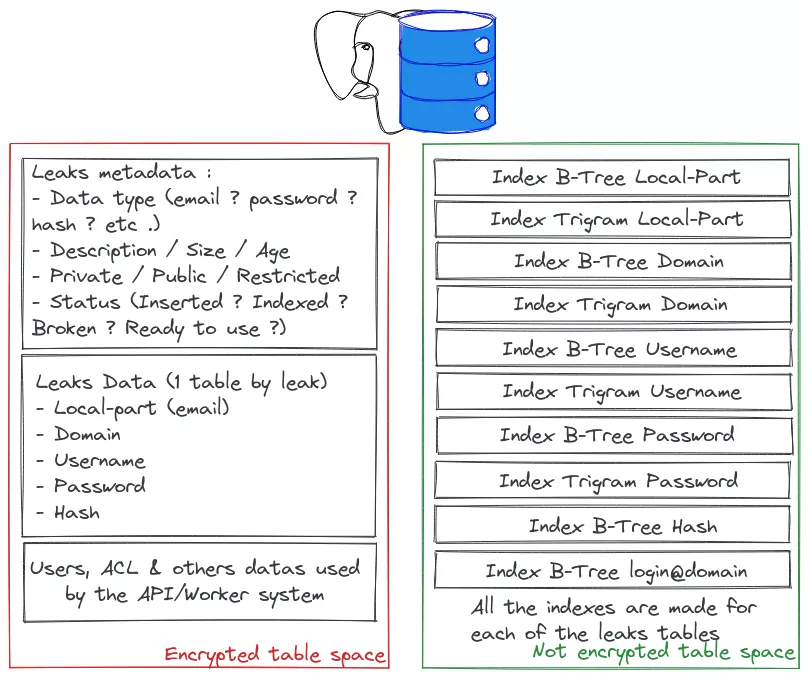
We will not explain in this article the security aspects, such as system hardening or ACL enforcement, but will instead focus on the PostgreSQL configuration.
Tweaking the PostgreSQL config
Before digging into some tables optimizations, we can tweak some parameters in the PostgreSQL configuration to speed up the system.
# WARNING# this tool not being optimal
# for very high memory systems
# DB Version: 13# OS Type: linux
# DB Type: dw
# Total Memory (RAM): 132 GB
# CPUs num: 24
# Connections num: 20
# Data Storage: ssd
max_connections = 20
shared_buffers = 33GB
effective_cache_size = 99GB
maintenance_work_mem = 2GB
checkpoint_completion_target = 0.9
wal_buffers = 16MB
default_statistics_target = 500
random_page_cost = 1.1
effective_io_concurrency = 200
work_mem = 72089kB
min_wal_size = 4GB
max_wal_size = 16GB
max_worker_processes = 24
max_parallel_workers_per_gather = 12
max_parallel_workers = 24
max_parallel_maintenance_workers = 4
# minimizing number of connection
max_connections = 20
# a bit less than 25%, take a little margin
shared_buffers = 33GB
# around 75%, a bit aggressive, but important for a large domain
effective_cache_size = 99GB
# don't need to do a lot of maintenance, only analyze
maintenance_work_mem = 2GB
# don't have a lot of write-operations
# only when inserting (new leak) and updating (hash cracked), not a priority, can be time consuming
checkpoint_completion_target = 0.9
# max value
wal_buffers = 16MB
random_page_cost = 1.1
effective_io_concurrency = 200
work_mem = 72089kB
min_wal_size = 4GB
max_wal_size = 16GB
# 24 cpu cores
max_worker_processes = 24
max_parallel_workers_per_gather = 12
max_parallel_workers = 24
max_parallel_maintenance_workers = 4
If you look carefully, you can see that a field has disappeared from the previous configuration. We found after a bunch of parameters testing that one of the most important settings to tune is default_statistics_target. PostgreSQL keeps some statistics about its indexes, one of them being a list of the most repeated elements in an index. To build these statistics, we run an ANALYZE query as the last step before marking a leak as ready. This query will be very time-consuming, but it will provide very valuable data to the query planner.
For example, as Gmail is the leader in mail hosting, it is no surprise that is makes up a large proportion of the leaks. If we were to run a request like "email like 'john%doe' and domain='gmail.com'", as it will be explained later, two indexes can be used to speed up the request. The trigram index for emails, and the BTree index for domain. If there were very few users with a "gmail.com" email, the correct choice would be to select them, and filter them without using the trigram index. However, as more than 50% of the entries have this domain, it is actually faster to use the trigram index and then filter the domains. This knowledge is vital in tuning queries, so we maxed out this parameter, which can get up to 10,000 since PostgreSQL 8.4:
default_statistics_target = 10000
We have decided to add some others parameters into the configuration file to fit our needs.
autovacuum = off
autocommit = off
statement_timeout = 180s
We do not plan to execute queries that can take more than 3 minutes. If queries are longer, we can suppose 2 things: the query planner is not optimized enough or the query templates that we provide to users aren't good enough.
The tricks
A quick primer on "regular" indexes
Indexes are data structures that can be used to speed up queries. The database engine can use them to find the selected data without having to search through every row.
With PostgreSQL, the most commonly used index is the B-Tree. It is good for speeding up equality and range checks. For example, if column col was indexed using a B-Tree, all the following queries would be accelerated:
SELECT * FROM table WHERE col = 12;
SELECT * FROM table WHERE col < 0;
SELECT * FROM table WHERE col BETWEEN 5 AND 8;
For string-like columns, B-Trees are good at accelerating prefix searches, as the following queries would be equivalent:
SELECT * FROM table WHERE col LIKE 'prefix%';
SELECT * FROM table WHERE col >= 'prefix' AND col < 'prefix';
However, in the case of the Leakozorus product, these indexes would not help us for most of the queries.
For example, these requests are not efficient with a classical b-tree:
SELECT * FROM table WHERE col LIKE '%domain.com';
SELECT * FROM table WHERE col LIKE '%.lastname@domain.com';
Requirements
We identified the following patterns as the most common use of our database:
- looking for a name or variations of it,
- looking for a particular domain and its subdomains.
While looking for exact matches would be fast (ie. login is john.doe and domain is company.com), a more common search pattern would be to find all the entries containing john in the login and where the domain ends with company.com. The request would look like:
SELECT * FROM table WHERE login LIKE '%john%' AND domain LIKE '%company.com'
As we have seen, the B-Tree indexes are good for queries LIKE 'this%'. But if we try to run a search using 'LIKE %someting' the request will fall back to a sequential search that could be acceptable with small datasets and fast disk, but not at all when you have more than 10 billions entries.
To fix that problem we had explored few solutions using multiple kinds of indexes that will make the queries run in a reasonable amount of time :
Looking for a substring, or variations of a string
The solution for this problem is fairly well known, and can be found with a bit of googling. Starting with PostgreSQL 9.1, trigram indexes can be used in order to speed up LIKE queries.
As can be guessed by the name, this works by collecting all trigrams and indexing them. If we go back to our previous query:
SELECT * FROM table WHERE login LIKE '%john%';
Without any index, all rows would have to be traversed, and the login column would be searched for the john substring. With a trigram index, it becomes possible to quickly filter all rows where the "joh" trigram and "ohn" trigram are both present.
As an added bonus, these indexes also give, for free, similarity based operators, allowing for searching login that look like a given login, or for variations of a known password. This can be situational but not that fast on large dataset.
select login, similarity(login, 'johndoe') as "similarity" from merge_db order by "similarity" desc limit 5;
Another point for our use case is to use trigram of type GIN and not GIST. What are the difference ? GIST indexes are the type mainly used in database like Elasticsearch, it is faster to create and update, but depending on the configuration can give result that are approximately the searched one. Searches for "%synacktiv%" can return "sinacktiv". This can be good in some situations, but not in our case, as we want to minimize false positives.
So we prefer to use GIN index, that are slower to build and larger to store, but faster to request, and exact results.
You may find some additional technical reasons on GIN and GIST index types and their differences on text search use-cases on PostgreSQL documentation (https://www.postgresql.org/docs/9.4/textsearch-indexes.html).
Looking for a subdomain
We have just seen how trigram indexes can speed up LIKE queries. However, while these queries can get much faster than they could be without the indexes, it is possible to get even faster.
Here is an example query that we would want to perform often:
SELECT * FROM table WHERE domain LIKE '%domain.com'
A B-Tree would be good if we were looking for LIKE 'domain.com%', but can't be directly used for this query. The trick here is that you do not have to create an index on a column. It is possible to create indexes on several columns at once, or, as we will do here, on arbitrary SQL expressions.
This means that instead of creating and index on the domain column, one could create an index on the reverse(domain) expression. Now, we can modify the request in the following fashion to take full advantage of our index:
SELECT * FROM table WHERE reverse(domain) LIKE reverse('%domain.com')
Not a trick but trying to search smarter
PostgreSQL is very efficient at managing large tables, but we decided to split all the data by leak instead of only having one big table 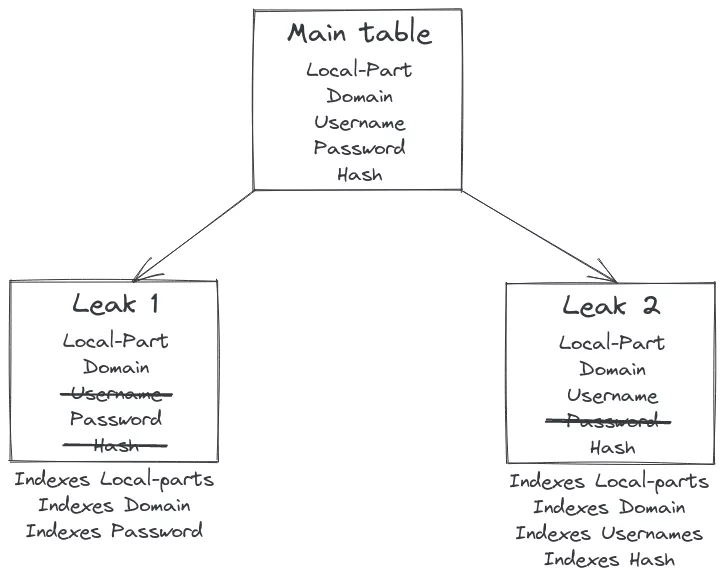 with associated index for some reasons :
with associated index for some reasons :
- Easier to maintain
- Indexing a few small tables is faster than one big
- Time lost by splitting all data is acceptable compare to the benefits (around 20% more time)
- Easy filtering on the request to speed up research (for example in our case people could want to ignore all results from fabricated leaks, so we don't include them in the search request send to PostgreSQL).
- Inserting/updating a table will not impact lookup operations on other tables
- and finally, it allows us to have a system where we can easily add / remove / update leaks without making the system temporarily unusable for users
How are we doing that ? We are using the inheritance system of PostgreSQL, and we create an inherited table for each leak as shown in the figure.
One good thing with that it is the fact that you can do that :
SELECT * from main_table WHERE domain = 'synacktiv.com';
This will search on all inherited table (here leak 1 and leak 2) and the query planner of PostgreSQL will be smart enough to use the correct index types (and it will also learn from previous similar requests!)
But one problem, our database is pretty huge, with around 14 billions email/password and around 10 billions hashes, why try to search emails in tables that only had username for example? Another problem is, what happens if we run a search when a leak is created and inserted but not yet indexed? This is a case that we absolutely want to avoid, because searches in non-indexed tables will lead to the use of the infamous sequential search, and this is a one way road to a query timeout ...
But, like shown in the architecture schema above, we have the knowledge of the content of each leak and its state (inserted, indexed, etc.). So we can just try to analyze the SQL request above and craft it ourselves to use only the tables that we want.
SELECT * from leak_1 WHERE domain = 'synacktiv.com' UNION ALL
SELECT * from leak_2 WHERE domain = 'synacktiv.com';
-- this is exactly the same request as the select * from main_table
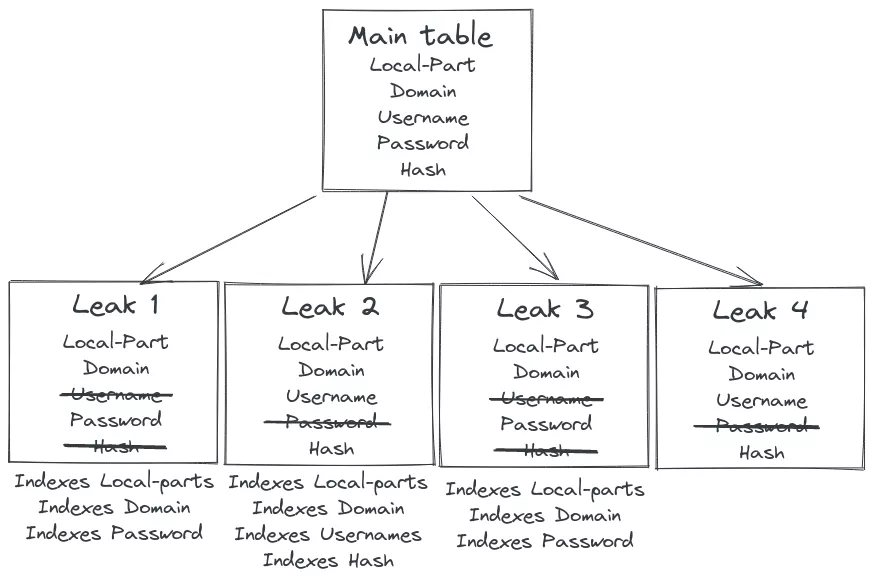 So now if a user wants to find all the results where password is SuperNinja when the request is done by the system the SQL request will be done only on tables where passwords are indexed :
So now if a user wants to find all the results where password is SuperNinja when the request is done by the system the SQL request will be done only on tables where passwords are indexed :
SELECT * from leak_1 WHERE password
LIKE 'SuperNinja' UNION ALL
SELECT * from leak_3 WHERE password
LIKE 'SuperNinja';
And if the user wants to find an email, the system will also ignore leaks that are in process of being indexed like leak_4 here, that doesn't have indexes yet.
SELECT * from leak_1 WHERE localpart LIKE '*SuperNinja*' UNION ALL
SELECT * from leak_2 WHERE localpart LIKE '*SuperNinja*' UNION ALL
SELECT * from leak_3 WHERE localpart LIKE '*SuperNinja*';
Benchmarks
In this setup, we use all the above tricks above over 15,386,414,389 entries (95 dumps composed of email, password, username and hashes).
| field | mode of search | minimum time | maximum time | average time | example |
|---|---|---|---|---|---|
| exact | 45 ms | 1397 ms | 147 ms | john.smith@gmail.com | |
| fuzzy | 300 ms | 59 s | 11000 ms | john*smith*@*gmail.com | |
| password1 | exact | 145 ms | 3824 ms | 435 ms | StrongPassword123 |
| password1 | fuzzy | 1500 ms | 125 s | 40 s | StrongPassword* |
| domain2 | fuzzy | 225 ms | 40 s | 2838 ms | *gouv.fr |
1 This table only show result for the password field, but the results are the same for all the different field of our system (login / username / password / hash)
2 Domain are using specific field as explained previously, making their response time more optimized that other field for fuzzy research.
3 All numbers above have been tested with 3 to 5 parallel request using a 10 000 mix of data present or not in the system.
From this number we can see that exact search are a lot faster than fuzzy search, but this is acceptable due to the difference of usage:
- Fuzzy searches are mainly used during red team and around ~ 1 minute wait time is acceptable to get results for a target. Most of the users use the web interface to get results.
Conclusion
This little journey has led us to a better understanding of PostgreSQL internal mechanisms and on how to have an efficient system that will not need much effort from us to maintain and that gives fast & accurate results to our Pentest/RedTeam/IR coworkers! Now the time needed for us to insert new data is only a few seconds, just the time to click on the right button
Of course more optimizations are possible, and it will come with more feedback from our users, and also with technology improvements (if PostgreSQL improve their performance then ours will be improved as well). We always want to reduce as much as possible the time required to query specific information, so maybe the additional use of bloom indexes or variants can be a solution.
To conclude on a higher level topic, even if a tool like that can be very useful to our consultants, it can also be effective at increasing awareness for just about anyone. The feeling of seeing your password exposed like that can be a huge blow to the confidence in using your 10 years old favorite password. That was quite helpful for convincing my father to use password manager after showing him that his password history made of the same word + year in many leaks 😅.