Exploring GrapheneOS secure allocator: Hardened Malloc
GrapheneOS is a mobile operating system based on Android and focusing on privacy and security. To enhance further the security of their product, GrapheneOS developers introduced a new libc allocator : hardened malloc. This allocator has a security-focused design in mind to protect processes against common memory corruption vulnerabilities. This article will explain in details its internal architecture and how security mitigation are implemented from a security researcher point of view.
Looking to improve your skills? Discover our trainings sessions! Learn more.
Introduction
GrapheneOS is a security and privacy-focused mobile operating system based on a modified version of Android (AOSP). To enhance its protection, it integrates advanced security features, including its own memory allocator for libc: hardened malloc. Designed to be as robust as the operating system itself, this allocator specifically seeks to protect against memory corruption.
This technical article details the internal workings of hardened malloc and the protection mechanisms it implements to prevent common memory corruption vulnerabilities. It is intended for a technical audience, particularly security researchers or exploit developers, who wish to gain an in-depth understanding of this allocator's internals.
The analyses and tests in this article were performed on two devices running GrapheneOS:
- Pixel 4a 5G:
google/bramble/bramble:14/UP1A.231105.001.B2/2025021000:user/release-keys - Pixel 9a:
google/tegu/tegu:16/BP2A.250705.008/2025071900:user/release-keys
The devices were rooted with Magisk 29 in order to use Frida to observe the internal state of hardened malloc within system processes. The study was based on the source code from the official GrapheneOS GitHub repository (commit 7481c8857faf5c6ed8666548d9e92837693de91b).
GrapheneOS
GrapheneOS is a hardened operating system based on Android. As an actively maintained open-source project, it benefits from frequent updates and the swift application of security patches. All information is available on GrapheneOS website.
To effectively protect the processes running on the device, GrapheneOS implements several security mechanisms. The following sections briefly describe the specific mechanisms that contribute to the hardening of its memory allocator.
Extended Address Space
On standard Android systems, the address space for userland processes is limited to 39 bits, ranging from 0 to 0x8000000000. On GrapheneOS, this space is extended to 48 bits, and to take advantage of this extension, ASLR entropy has also been increased from 24 to 33 bits. This detail is important as hardened malloc relies heavily on mmap for its internal structures and its allocations.
tegu:/ # cat /proc/self/maps
c727739a2000-c727739a9000 rw-p 00000000 00:00 0 [anon:.bss]
c727739a9000-c727739ad000 r--p 00000000 00:00 0 [anon:.bss]
c727739ad000-c727739b1000 rw-p 00000000 00:00 0 [anon:.bss]
c727739b1000-c727739b5000 r--p 00000000 00:00 0 [anon:.bss]
c727739b5000-c727739c1000 rw-p 00000000 00:00 0 [anon:.bss]
e5af7fa30000-e5af7fa52000 rw-p 00000000 00:00 0 [stack]
tegu:/ # cat /proc/self/maps
d112736be000-d112736c5000 rw-p 00000000 00:00 0 [anon:.bss]
d112736c5000-d112736c9000 r--p 00000000 00:00 0 [anon:.bss]
d112736c9000-d112736cd000 rw-p 00000000 00:00 0 [anon:.bss]
d112736cd000-d112736d1000 r--p 00000000 00:00 0 [anon:.bss]
d112736d1000-d112736dd000 rw-p 00000000 00:00 0 [anon:.bss]
ea0de59be000-ea0de59e1000 rw-p 00000000 00:00 0 [stack]
tegu:/ # cat /proc/self/maps
d71f87043000-d71f8704a000 rw-p 00000000 00:00 0 [anon:.bss]
d71f8704a000-d71f8704e000 r--p 00000000 00:00 0 [anon:.bss]
d71f8704e000-d71f87052000 rw-p 00000000 00:00 0 [anon:.bss]
d71f87052000-d71f87056000 r--p 00000000 00:00 0 [anon:.bss]
d71f87056000-d71f87062000 rw-p 00000000 00:00 0 [anon:.bss]
f69f7c952000-f69f7c974000 rw-p 00000000 00:00 0 [stack]
Secure app spawning
On standard Android, each application is launched via a fork of the zygote process. This mechanism, designed to speed up startup, has a major security consequence: all applications inherit the same address space as zygote. In practice, this means that pre-loaded libraries end up at identical addresses from one application to another. For an attacker, this predictability makes it easy to bypass ASLR protection without needing a prior information leak.
To overcome this limitation, GrapheneOS fundamentally changes this process. Instead of just a fork, new applications are launched with exec. This method creates an entirely new and randomized address space for each process, thereby restoring the full effectiveness of ASLR. It is no longer possible to predict the location of remote memory regions. This enhanced security does, however, come at a cost: a slight impact on launch performance and an increased memory footprint for each application.
tegu:/ # cat /proc/$(pidof zygote64)/maps | grep libc\.so
d6160aac0000-d6160ab19000 r--p 00000000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d6160ab1c000-d6160abbe000 r-xp 0005c000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d6160abc0000-d6160abc5000 r--p 00100000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d6160abc8000-d6160abc9000 rw-p 00108000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
tegu:/ # cat /proc/$(pidof com.android.messaging)/maps | grep libc\.so
d5e4a9c68000-d5e4a9cc1000 r--p 00000000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d5e4a9cc4000-d5e4a9d66000 r-xp 0005c000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d5e4a9d68000-d5e4a9d6d000 r--p 00100000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d5e4a9d70000-d5e4a9d71000 rw-p 00108000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
tegu:/ # cat /proc/$(pidof com.topjohnwu.magisk)/maps | grep libc\.so
dabc42ac5000-dabc42b1e000 r--p 00000000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
dabc42b21000-dabc42bc3000 r-xp 0005c000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
dabc42bc5000-dabc42bca000 r--p 00100000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
dabc42bcd000-dabc42bce000 rw-p 00108000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
Memory Tagging Extension (MTE)
Memory Tagging Extension, or MTE, is an extension of the ARM architecture introduced with Armv8.5. MTE aims to prevent memory corruption vulnerabilities from being exploited by an attacker. This protection relies on a mechanism of tagging memory regions.
During an allocation, a 4-bit tag is associated with the allocated region and stored in the top bits of the pointer. To access the data, both the address and the tag must be correct. If the tag is wrong, an exception is raised. This mechanism allows for the detection and blocking of vulnerabilities such as out-of-bound reads/writes and use-after-free.
For example, the out-of-bounds write in the following C code could be detected, depending on the allocator's implementation with MTE:
char* ptr = malloc(8);
ptr[16] = 12; // oob write, this tag is not valid for the area
Since MTE is a feature offered by the CPU, it is necessary for the hardware to be compatible. This is the case for all Google Pixel smartphones since the Pixel 8. For more information, refer to the ARM documentation.
Hardened malloc therefore uses MTE on compatible smartphones to prevent this type of memory corruption.
In order to benefit from MTE, a binary must be compiled with the appropriate flags. For the purposes of this article, the flags below were added to the Application.mk file of our test binaries to enable MTE.
APP_CFLAGS := -fsanitize=memtag -fno-omit-frame-pointer -march=armv8-a+memtag
APP_LDFLAGS := -fsanitize=memtag -march=armv8-a+memtag
The Android documentation provides all the necessary information to create an MTE-compatible application.
Hardened malloc relies heavily on MTE by adding tags to its allocations. Please note that only small allocation (less than 0x20000 bytes) are tagged.
Hardened malloc architecture
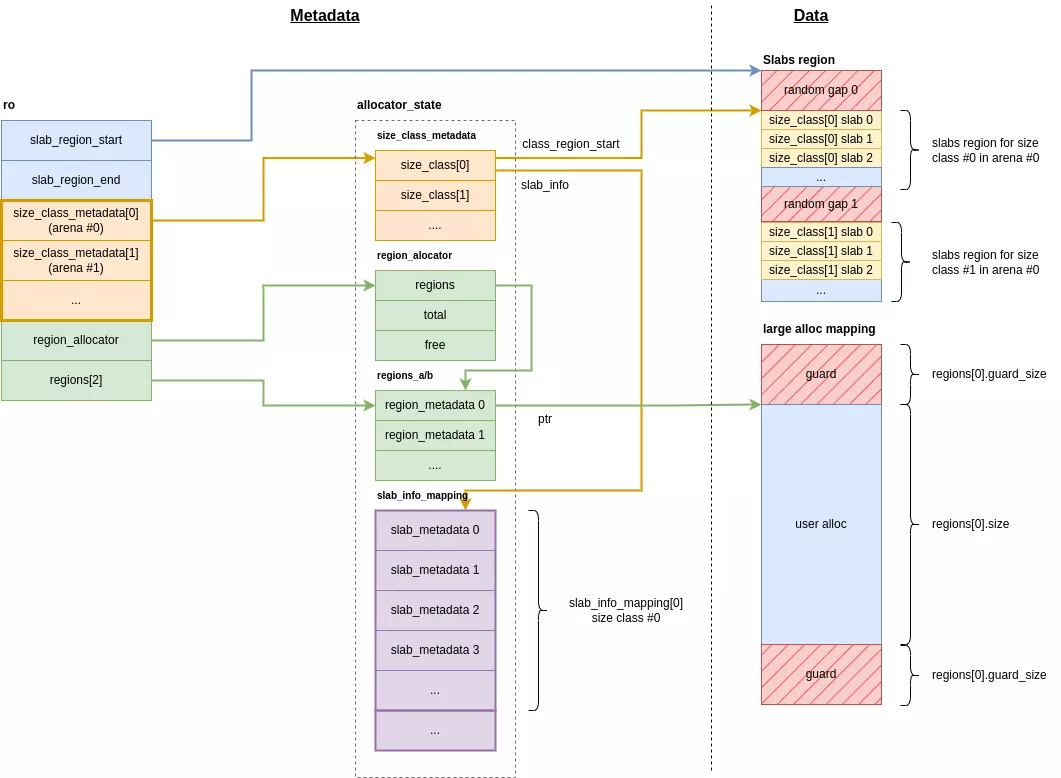
To enhance security, hardened malloc isolates metadata from user data in separate memory regions, holding it primarily within two main structures :
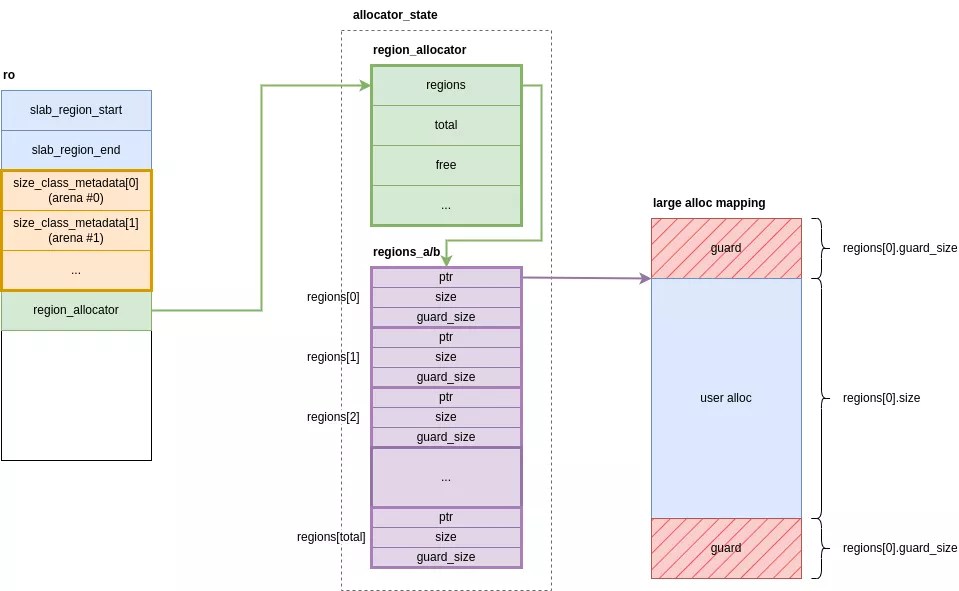
ro: the main structure in the.bsssection of libc.allocator_state: a large structure grouping all metadata for the different allocation types. Its memory region is reserved only once at initialization.
Similar to jemalloc, hardened malloc partitions threads into arenas, with each arena managing its own allocations. This implies that memory allocated in one arena cannot be managed or freed by another arena. However, there is no explicit data structure to define these arenas; their existence is implicit and primarily affects the size of certain internal arrays.
Although the arena concept is present in the source code, analysis of the libc binaries from the test devices revealed that hardened malloc was compiled to use only a single arena. As a result, all threads share the same pool of allocation metadata.
ro structure
The ro structure is the allocator's main metadata structure. It is contained within the .bss section of libc and consists of the following attributes:
static union {
struct {
void *slab_region_start;
void *_Atomic slab_region_end;
struct size_class *size_class_metadata[N_ARENA];
struct region_allocator *region_allocator;
struct region_metadata *regions[2];
#ifdef USE_PKEY
int metadata_pkey;
#endif
#ifdef MEMTAG
bool is_memtag_disabled;
#endif
};
char padding[PAGE_SIZE];
} ro __attribute__((aligned(PAGE_SIZE)));
-
slab_region_start: The start of the memory area containing the regions for small allocations. -
slab_region_end: The end of the memory area containing the regions for small allocations. -
size_class_metadata[N_ARENA]: An array of pointers to the metadata for small allocations, per arena. -
region_allocator: A pointer to the management structure for large allocations. -
regions[2]: A pointer to the hash tables that reference the large allocations.
allocator_state
This structure contains all the metadata used for both small and large allocations. It is mapped only once when the allocator initializes and is isolated by guard pages. Its size is fixed and computed based on the maximum number of allocations the allocator can handle.
struct __attribute__((aligned(PAGE_SIZE))) allocator_state {
struct size_class size_class_metadata[N_ARENA][N_SIZE_CLASSES];
struct region_allocator region_allocator;
// padding until next page boundary for mprotect
struct region_metadata regions_a[MAX_REGION_TABLE_SIZE] __attribute__((aligned(PAGE_SIZE)));
// padding until next page boundary for mprotect
struct region_metadata regions_b[MAX_REGION_TABLE_SIZE] __attribute__((aligned(PAGE_SIZE)));
// padding until next page boundary for mprotect
struct slab_info_mapping slab_info_mapping[N_ARENA][N_SIZE_CLASSES];
// padding until next page boundary for mprotect
};
-
size_class_metadata[N_ARENA][N_SIZE_CLASSES]: An array ofsize_classstructures containing the metadata for small allocations for each class. -
region_allocator: The metadata for the large allocations regions. -
regions_a/b[MAX_REGION_TABLE_SIZE]: A hash table that groups information about the mappings of large allocations. -
slab_info_mapping: The metadata for the slabs of small allocations.
User data
Hardened malloc stores user data in two types of regions, separate from its metadata:
-
Slabs region: a very large area reserved only once at initialization, which contains the slabs for small allocations. It is initialized in the
init_slow_pathfunction and its starting address is stored inro.slab_region_start. -
Large regions: dynamically reserved areas that hold the data for large allocations. Each such region contains only a single large allocation.
Allocations
There are two types of allocations in hardened malloc: small allocations and large allocations.
Small allocations
Size classes/bins
Small allocations are categorized by size into size classes, also known as bins. hardened malloc utilizes 49 such classes, which are indexed by increasing size and represented by the size_class structure:
| Size Class | Total Bin Size | Available Size | Slots | Slab size | Max slabs | Quarantines Size (random / FIFO) |
|---|---|---|---|---|---|---|
| 0 | 0x10 | 0x10 | 256 | 0x1000 | 8388608 | 8192 / 8192 |
| 1 | 0x10 | 0x8 | 256 | 0x1000 | 8388608 | 8192 / 8192 |
| 2 | 0x20 | 0x18 | 128 | 0x1000 | 8388608 | 4096 / 4096 |
| 3 | 0x30 | 0x28 | 85 | 0x1000 | 8388608 | 4096 / 4096 |
| 4 | 0x40 | 0x38 | 64 | 0x1000 | 8388608 | 2048 / 2048 |
| 5 | 0x50 | 0x48 | 51 | 0x1000 | 8388608 | 2048 / 2048 |
| 6 | 0x60 | 0x58 | 42 | 0x1000 | 8388608 | 2048 / 2048 |
| 7 | 0x70 | 0x68 | 36 | 0x1000 | 8388608 | 2048 / 2048 |
| 8 | 0x80 | 0x78 | 64 | 0x2000 | 4194304 | 1024 / 1024 |
| 9 | 0xa0 | 0x98 | 51 | 0x2000 | 4194304 | 1024 / 1024 |
| 10 | 0xc0 | 0xb8 | 64 | 0x3000 | 2796202 | 1024 / 1024 |
| 11 | 0xe0 | 0xd8 | 54 | 0x3000 | 2796202 | 1024 / 1024 |
| 12 | 0x100 | 0xf8 | 64 | 0x4000 | 2097152 | 512 / 512 |
| 13 | 0x140 | 0x138 | 64 | 0x5000 | 1677721 | 512 / 512 |
| 14 | 0x180 | 0x178 | 64 | 0x6000 | 1398101 | 512 / 512 |
| 15 | 0x1c0 | 0x1b8 | 64 | 0x7000 | 1198372 | 512 / 512 |
| 16 | 0x200 | 0x1f8 | 64 | 0x8000 | 1048576 | 256 / 256 |
| 17 | 0x280 | 0x278 | 64 | 0xa000 | 838860 | 256 / 256 |
| 18 | 0x300 | 0x2f8 | 64 | 0xc000 | 699050 | 256 / 256 |
| 19 | 0x380 | 0x378 | 64 | 0xe000 | 599186 | 256 / 256 |
| 20 | 0x400 | 0x3f8 | 64 | 0x10000 | 524288 | 128 / 128 |
| 21 | 0x500 | 0x4f8 | 16 | 0x5000 | 1677721 | 128 / 128 |
| 22 | 0x600 | 0x5f8 | 16 | 0x6000 | 1398101 | 128 / 128 |
| 23 | 0x700 | 0x6f8 | 16 | 0x7000 | 1198372 | 128 / 128 |
| 24 | 0x800 | 0x7f8 | 16 | 0x8000 | 1048576 | 64 / 64 |
| 25 | 0xa00 | 0x9f8 | 8 | 0x5000 | 1677721 | 64 / 64 |
| 26 | 0xc00 | 0xbf8 | 8 | 0x6000 | 1398101 | 64 / 64 |
| 27 | 0xe00 | 0xdf8 | 8 | 0x7000 | 1198372 | 64 / 64 |
| 28 | 0x1000 | 0xff8 | 8 | 0x8000 | 1048576 | 32 / 32 |
| 29 | 0x1400 | 0x13f8 | 8 | 0xa000 | 838860 | 32 / 32 |
| 30 | 0x1800 | 0x17f8 | 8 | 0xc000 | 699050 | 32 / 32 |
| 31 | 0x1c00 | 0x1bf8 | 8 | 0xe000 | 599186 | 32 / 32 |
| 32 | 0x2000 | 0x1ff8 | 8 | 0x10000 | 524288 | 16 / 16 |
| 33 | 0x2800 | 0x27f8 | 6 | 0xf000 | 559240 | 16 / 16 |
| 34 | 0x3000 | 0x2ff8 | 5 | 0xf000 | 559240 | 16 / 16 |
| 35 | 0x3800 | 0x37f8 | 4 | 0xe000 | 599186 | 16 / 16 |
| 36 | 0x4000 | 0x3ff8 | 4 | 0x10000 | 524288 | 8 / 8 |
| 37 | 0x5000 | 0x4ff8 | 1 | 0x5000 | 1677721 | 8 / 8 |
| 38 | 0x6000 | 0x5ff8 | 1 | 0x6000 | 1398101 | 8 / 8 |
| 39 | 0x7000 | 0x6ff8 | 1 | 0x7000 | 1198372 | 8 / 8 |
| 40 | 0x8000 | 0x7ff8 | 1 | 0x8000 | 1048576 | 4 / 4 |
| 41 | 0xa000 | 0x9ff8 | 1 | 0xa000 | 838860 | 4 / 4 |
| 42 | 0xc000 | 0xbff8 | 1 | 0xc000 | 699050 | 4 / 4 |
| 43 | 0xe000 | 0xdff8 | 1 | 0xe000 | 599186 | 4 / 4 |
| 44 | 0x10000 | 0xfff8 | 1 | 0x10000 | 524288 | 2 / 2 |
| 45 | 0x14000 | 0x13ff8 | 1 | 0x14000 | 419430 | 2 / 2 |
| 46 | 0x18000 | 0x17ff8 | 1 | 0x18000 | 349525 | 2 / 2 |
| 47 | 0x1c000 | 0x1bff8 | 1 | 0x1c000 | 299593 | 2 / 2 |
| 48 | 0x20000 | 0x1fff8 | 1 | 0x20000 | 262144 | 1 / 1 |
Within each arena, an array of 49 size_class entries maintains the metadata for every size class. For each class, the allocator reserves a dedicated memory region to hold its corresponding allocations. This region is segmented into slabs, which are in turn subdivided into slots. Each slot corresponds to a single memory chunk returned to the user.
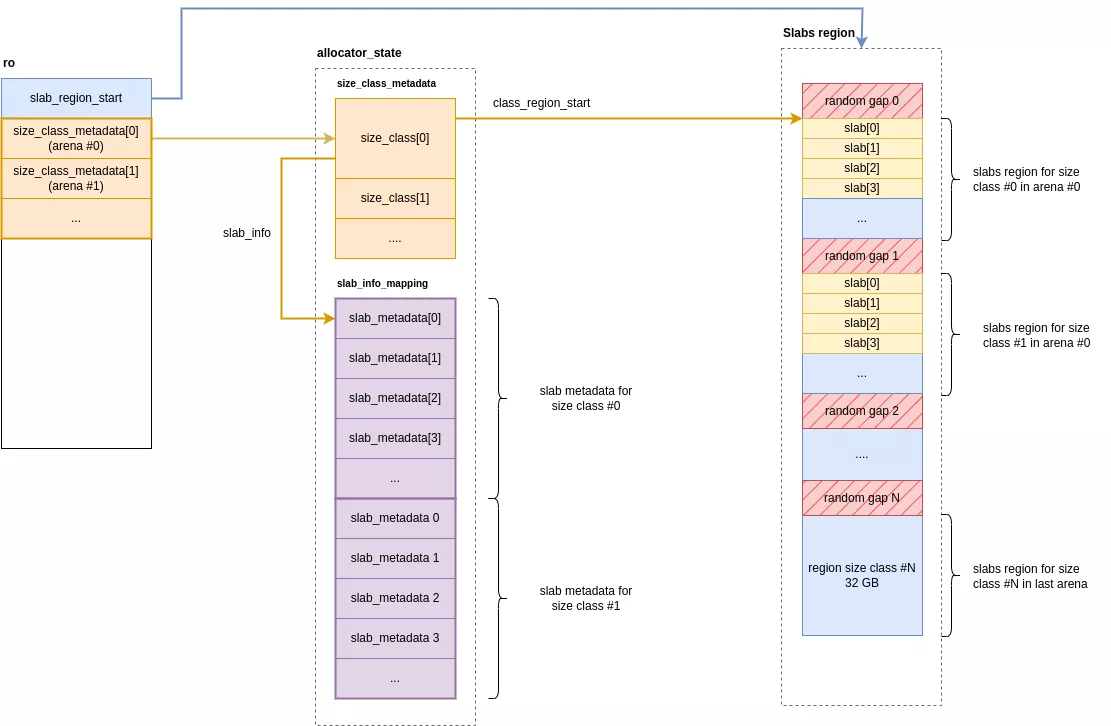
The regions for all classes are reserved contiguously in memory when the allocator is initialized. Each region occupies 32 GiB of memory at a random offset within a 64 GiB area. The empty areas before and after the region act as page-aligned guards of a random size.
To summarize:
- A 32 GiB region is allocated per size class.
- It is encapsulated at a random offset within a zone twice its size (64 GiB).
- The 64 GiB zones are contiguous and ordered by increasing size class.
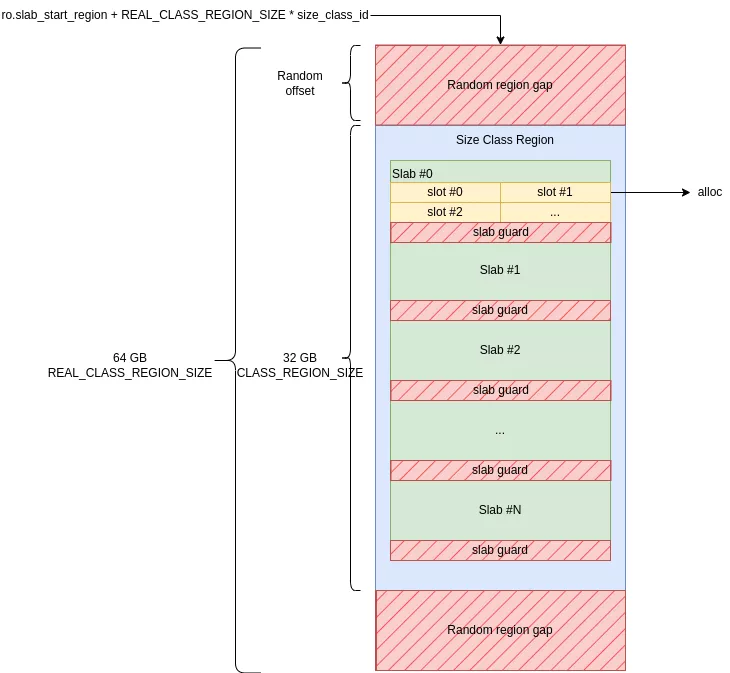
The size of the contiguous memory area reserved during initialization is N_ARENA * 49 * 64 GiB. On the test devices, which use a single arena, this amounts to 0x31000000000 bytes (~3 TB). By default, these pages are protected with PROT_NONE, meaning they are not backed by physical memory. This protection is changed to Read/Write (RW) on demand for specific pages as allocations are needed.
// CONFIG_EXTENDED_SIZE_CLASSES := true
// CONFIG_LARGE_SIZE_CLASSES := true
// CONFIG_CLASS_REGION_SIZE := 34359738368 # 32GiB
// CONFIG_N_ARENA := 1
#define CLASS_REGION_SIZE (size_t)CONFIG_CLASS_REGION_SIZE
#define REAL_CLASS_REGION_SIZE (CLASS_REGION_SIZE * 2)
#define ARENA_SIZE (REAL_CLASS_REGION_SIZE * N_SIZE_CLASSES)
static const size_t slab_region_size = ARENA_SIZE * N_ARENA; // 0x31000000000 on Pixel 4a 5G and Pixel 9a
// ...
COLD static void init_slow_path(void) {
// ...
// Create a big mapping with MTE enabled
ro.slab_region_start = memory_map_tagged(slab_region_size);
if (unlikely(ro.slab_region_start == NULL)) {
fatal_error("failed to allocate slab region");
}
void *slab_region_end = (char *)ro.slab_region_start + slab_region_size;
memory_set_name(ro.slab_region_start, slab_region_size, "malloc slab region gap");
// ...
}
Each size class (or bin) is represented by the size_class structure, a relatively large structure that holds all the relevant information for that class.
struct __attribute__((aligned(CACHELINE_SIZE))) size_class {
struct mutex lock;
void *class_region_start;
struct slab_metadata *slab_info;
struct libdivide_u32_t size_divisor;
struct libdivide_u64_t slab_size_divisor;
#if SLAB_QUARANTINE_RANDOM_LENGTH > 0
void *quarantine_random[SLAB_QUARANTINE_RANDOM_LENGTH << (MAX_SLAB_SIZE_CLASS_SHIFT - MIN_SLAB_SIZE_CLASS_SHIFT)];
#endif
#if SLAB_QUARANTINE_QUEUE_LENGTH > 0
void *quarantine_queue[SLAB_QUARANTINE_QUEUE_LENGTH << (MAX_SLAB_SIZE_CLASS_SHIFT - MIN_SLAB_SIZE_CLASS_SHIFT)];
size_t quarantine_queue_index;
#endif
// slabs with at least one allocated slot and at least one free slot
//
// LIFO doubly-linked list
struct slab_metadata *partial_slabs;
// slabs without allocated slots that are cached for near-term usage
//
// LIFO singly-linked list
struct slab_metadata *empty_slabs;
size_t empty_slabs_total; // length * slab_size
// slabs without allocated slots that are purged and memory protected
//
// FIFO singly-linked list
struct slab_metadata *free_slabs_head;
struct slab_metadata *free_slabs_tail;
struct slab_metadata *free_slabs_quarantine[FREE_SLABS_QUARANTINE_RANDOM_LENGTH];
#if CONFIG_STATS
u64 nmalloc; // may wrap (per jemalloc API)
u64 ndalloc; // may wrap (per jemalloc API)
size_t allocated;
size_t slab_allocated;
#endif
struct random_state rng;
size_t metadata_allocated;
size_t metadata_count;
size_t metadata_count_unguarded;
};
Its main members are:
class_region_start: start address of the memory region for this class's slabs.slab_info: pointer to the beginning of the slab metadata array.quarantine_random,quarantine_queue: arrays of pointers to allocations currently in quarantine (see the section on quarantines).partial_slabs: a stack of metadata for partially filled slabs.free_slabs_{head, tail}: a queue of metadata for empty slabs.
Slab metadata is held in the slab_metadata structure. For any given size class, these structures form a contiguous array, accessible via the size_class->slab_info pointer. The layout of this metadata array directly mirrors the layout of the slabs in their memory region. This design allows for direct lookup: a slab's metadata can be found simply by using the slab's index to access the array.
struct slab_metadata {
u64 bitmap[4];
struct slab_metadata *next;
struct slab_metadata *prev;
#if SLAB_CANARY
u64 canary_value;
#endif
#ifdef SLAB_METADATA_COUNT
u16 count;
#endif
#if SLAB_QUARANTINE
u64 quarantine_bitmap[4];
#endif
#ifdef HAS_ARM_MTE
// arm_mte_tags is used as a u4 array (MTE tags are 4-bit wide)
//
// Its size is calculated by the following formula:
// (MAX_SLAB_SLOT_COUNT + 2) / 2
// MAX_SLAB_SLOT_COUNT is currently 256, 2 extra slots are needed for branchless handling of
// edge slots in tag_and_clear_slab_slot()
//
// It's intentionally placed at the end of struct to improve locality: for most size classes,
// slot count is far lower than MAX_SLAB_SLOT_COUNT.
u8 arm_mte_tags[129];
#endif
};
bitmap[4]: bitmap tracking which slots in the slab are in use.next, prev: pointers to the next/previous elements when the structure belongs to a linked list (for example, in the stack of partially used slabssize_class->partial_slabs)canary_value: canary value appended to the end of each slot within the slab (on non-MTE devices only). This value is verified uponfreeto detect buffer overflows.arm_mte_tags[129]: MTE tags currently in use per slot
Alloc
First, the actual size to be allocated is calculated by adding 8 bytes to the user's requested size. These extra bytes are filled with a canary and placed immediately after the data. An allocation is considered "small" only if this new size is less than 0x20000 bytes (131,072 bytes) . Next, a free slot must be retrieved from a slab by following these steps:
- Retrieve the arena: the current arena is fetched from the thread's local storage.
- Get size class metadata: the metadata for the corresponding size class (the
size_classstructure) is retrieved usingro.size_class_metadata[arena][size_class], wherearenais the arena number andsize_classis the index calculated from the allocation size. - Find a slab with a free slot:
- if a partially filled slab exists (
size_class->partial_slabs != NULL), this slab is used. - otherwise, if at least one empty slab is available (
size_class->empty_slabs != NULL), the first slab from this list is used. - if no slab is available, a new one is allocated (by allocating a
slab_metadatastructure using thealloc_metadata()function). A "guard" slab is reserved between each real slab.
- if a partially filled slab exists (
- Select a random free slot: A free slot is chosen randomly from within the selected slab. Occupied slots are marked by
1s in theslab_metadata->bitmap. - Select a MTE tag: A new MTE tag is chosen for the slot, ensuring it is different from adjacent tags to prevent simple linear overflows. The following tags are excluded:
- the previous slot's tag.
- the next slot's tag.
- the old tag of the currently selected slot.
- the
RESERVED_TAG(0), which is used for freed allocations.
- Set protections:
- on devices without MTE, the canary (which is common to all slots in the slab) is written into the last 8 bytes of the slot.
- on MTE-enabled devices, these 8 bytes are set to 0.
- Return the address of the slot, now tagged with the MTE tag.
For a small allocation, the address returned by malloc is a pointer to a slot with a 4-bit MTE tag encoded in its most significant bits. The pointers below, retrieved from successive calls to malloc(8), are located in the same slab but at random offsets and have different MTE tags.
ptr[0] = 0xa00cd70ad02a930
ptr[1] = 0xf00cd70ad02ac50
ptr[2] = 0x300cd70ad02a2f0
ptr[3] = 0x900cd70ad02a020
ptr[4] = 0x300cd70ad02ac90
ptr[5] = 0x700cd70ad02a410
ptr[6] = 0xc00cd70ad02a3c0
ptr[7] = 0x500cd70ad02a3d0
ptr[8] = 0xf00cd70ad02a860
ptr[9] = 0x600cd70ad02ad20
If an overflow occurs, a SIGSEGV/SEGV_MTESERR exception is raised, indicating that an MTE-protected area was accessed with an incorrect tag. On GrapheneOS, this causes the application to terminate and sends a crash log to logcat.
07-23 11:32:19.948 4169 4169 F DEBUG : Cmdline: /data/local/tmp/bin
07-23 11:32:19.948 4169 4169 F DEBUG : pid: 4165, tid: 4165, name: bin >>> /data/local/tmp/bin <<<
07-23 11:32:19.948 4169 4169 F DEBUG : uid: 2000
07-23 11:32:19.949 4169 4169 F DEBUG : tagged_addr_ctrl: 000000000007fff3 (PR_TAGGED_ADDR_ENABLE, PR_MTE_TCF_SYNC, mask 0xfffe)
07-23 11:32:19.949 4169 4169 F DEBUG : pac_enabled_keys: 000000000000000f (PR_PAC_APIAKEY, PR_PAC_APIBKEY, PR_PAC_APDAKEY, PR_PAC_APDBKEY)
07-23 11:32:19.949 4169 4169 F DEBUG : signal 11 (SIGSEGV), code 9 (SEGV_MTESERR), fault addr 0x0500d541414042c0
07-23 11:32:19.949 4169 4169 F DEBUG : x0 0800d541414042c0 x1 0000d84c01173140 x2 0000000000000015 x3 0000000000000014
07-23 11:32:19.949 4169 4169 F DEBUG : x4 0000b1492c0f16b5 x5 0300d6f2d01ea99b x6 0000000000000029 x7 203d207972742029
07-23 11:32:19.949 4169 4169 F DEBUG : x8 5dde6df273e81100 x9 5dde6df273e81100 x10 0000000000001045 x11 0000000000001045
07-23 11:32:19.949 4169 4169 F DEBUG : x12 0000f2dbd10c1ca4 x13 0000000000000000 x14 0000000000000001 x15 0000000000000020
07-23 11:32:19.949 4169 4169 F DEBUG : x16 0000d84c0116e228 x17 0000d84c010faf50 x18 0000d84c1eb38000 x19 0500d541414042c0
07-23 11:32:19.949 4169 4169 F DEBUG : x20 0000000000001e03 x21 0000b1492c0f16e8 x22 0800d541414042c0 x23 0000000000000001
07-23 11:32:19.949 4169 4169 F DEBUG : x24 0000d541414042c0 x25 0000000000000000 x26 0000000000000000 x27 0000000000000000
07-23 11:32:19.949 4169 4169 F DEBUG : x28 0000000000000000 x29 0000f2dbd10c1f10
07-23 11:32:19.949 4169 4169 F DEBUG : lr 002bb1492c0f2ba0 sp 0000f2dbd10c1f10 pc 0000b1492c0f2ba4 pst 0000000060001000
Free
To free a small allocation, the allocator first determines its size class index from the pointer. This index allows it to locate the relevant metadata and the memory region where the data resides. The slab_size_class function performs this initial calculation.
static struct slab_size_class_info slab_size_class(const void *p) {
size_t offset = (const char *)p - (const char *)ro.slab_region_start;
unsigned arena = 0;
if (N_ARENA > 1) {
arena = offset / ARENA_SIZE;
offset -= arena * ARENA_SIZE;
}
return (struct slab_size_class_info){arena, offset / REAL_CLASS_REGION_SIZE};
}
With this index, now referred to as class_id, it is possible to gather various details about the slab containing the allocation:
size_classstructure:size_class *c = &ro.size_class_metadata[size_class_info.arena][class_id]- Allocation size: the size for this class is found using the
size_classeslookup table:size_t size = size_classes[class_id] - Slots per slab: the number of slots is found using the
size_class_slotslookup table:slots = size_class_slots[class_id] - Slab size:
slab_size = page_align(slots * size) - Current slab metadata:
offset = (const char *)p - (const char *)c->class_region_startindex = offset / slab_sizeslab_metadata = c->slab_info + index
With this information, the allocator can pinpoint the slab's base address and determine the specific slot's index and offset within that slab using the get_slab() function.
static void *get_slab(const struct size_class *c, size_t slab_size, const struct slab_metadata *metadata) {
size_t index = metadata - c->slab_info;
return (char *)c->class_region_start + (index * slab_size);
}
The slot's address is then deduced with the formula slot = (const char*)slab - p, as is its index: slot_index = ((const char*)slab - slot) / slots.
Once the slot is identified, a series of crucial security and integrity checks are performed to validate the free operation:
- Pointer alignment: the allocator verifies that the pointer is perfectly aligned with the start of a slot. Any misalignment indicates some kind of corruption, and the operation is immediately aborted.
- Slot state: it then checks the slab's metadata to confirm the slot is currently marked as "in use."
- Canary verification: the 8-byte canary at the end of the slot is checked for integrity. A key difference from scudo is that this canary is shared across the entire slab. This means a memory leak from one slot could theoretically allow an attacker to forge a valid canary for another slot and prevent a crash in case of a
free. - MTE Tag Invalidation: the slot's MTE tag is reset to the reserved value (0), effectively invalidating the original pointer and preventing dangling pointer access.
- Zero out: The slot's memory is completely wiped by zeroing it out.
If an invalid canary is detected, an abort is called with the following message:
07-23 02:14:09.559 7610 7610 F libc : hardened_malloc: fatal allocator error: canary corrupted
07-23 02:14:09.559 7610 7610 F libc : Fatal signal 6 (SIGABRT), code -1 (SI_QUEUE) in tid 7610 (bin), pid 7610 (bin)
07-23 02:14:09.775 7614 7614 F DEBUG : *** *** *** *** *** *** *** *** *** *** *** *** *** *** *** ***
07-23 02:14:09.775 7614 7614 F DEBUG : Build fingerprint: 'google/bramble/bramble:14/UP1A.231105.001.B2/2025021000:user/release-keys'
07-23 02:14:09.776 7614 7614 F DEBUG : Revision: 'MP1.0'
07-23 02:14:09.776 7614 7614 F DEBUG : ABI: 'arm64'
07-23 02:14:09.776 7614 7614 F DEBUG : Timestamp: 2025-07-23 02:14:09.603643955+0200
07-23 02:14:09.776 7614 7614 F DEBUG : Process uptime: 1s
07-23 02:14:09.776 7614 7614 F DEBUG : Cmdline: /data/local/tmp/bin
07-23 02:14:09.776 7614 7614 F DEBUG : pid: 7610, tid: 7610, name: bin >>> /data/local/tmp/bin <<<
07-23 02:14:09.776 7614 7614 F DEBUG : uid: 2000
07-23 02:14:09.776 7614 7614 F DEBUG : signal 6 (SIGABRT), code -1 (SI_QUEUE), fault addr --------
07-23 02:14:09.776 7614 7614 F DEBUG : Abort message: 'hardened_malloc: fatal allocator error: canary corrupted'
07-23 02:14:09.776 7614 7614 F DEBUG : x0 0000000000000000 x1 0000000000001dba x2 0000000000000006 x3 0000ea4a84242960
07-23 02:14:09.776 7614 7614 F DEBUG : x4 716e7360626e6b6b x5 716e7360626e6b6b x6 716e7360626e6b6b x7 7f7f7f7f7f7f7f7f
07-23 02:14:09.777 7614 7614 F DEBUG : x8 00000000000000f0 x9 0000cf1d482da2a0 x10 0000000000000001 x11 0000cf1d48331980
07-23 02:14:09.777 7614 7614 F DEBUG : x12 0000000000000004 x13 0000000000000033 x14 0000cf1d482da118 x15 0000cf1d482da050
07-23 02:14:09.777 7614 7614 F DEBUG : x16 0000cf1d483971e0 x17 0000cf1d48383650 x18 0000cf1d6fe40000 x19 0000000000001dba
07-23 02:14:09.777 7614 7614 F DEBUG : x20 0000000000001dba x21 00000000ffffffff x22 0000cc110ff0d150 x23 0000000000000000
07-23 02:14:09.777 7614 7614 F DEBUG : x24 0000000000000001 x25 0000cf0f4a421300 x26 0000000000000000 x27 0000cf0f4a421328
07-23 02:14:09.777 7614 7614 F DEBUG : x28 0000cf0f7ba30000 x29 0000ea4a842429e0
07-23 02:14:09.777 7614 7614 F DEBUG : lr 0000cf1d4831a9f8 sp 0000ea4a84242940 pc 0000cf1d4831aa24 pst 0000000000001000
Finally, the slot is not immediately made available. Instead, it is placed into quarantine to delay its reuse, a key defense against use-after-free vulnerabilities.
Quarantines
Each allocation class uses a two-stage quarantine system for its freed slots. When an allocation is freed, it isn't immediately available for reuse but is passed instead through two distinct holding areas:
- A random quarantine: a fixed-size array where incoming slots replace a randomly chosen existing slot.
- A queue quarantine: a First-In, First-Out queue that receives slots ejected from the random quarantine.
When a slot enters the random quarantine, it overwrites a randomly selected entry. That ejected entry is then pushed into the queue quarantine. The queue then ejects its oldest element, which is finally made available for new allocations. This entire process is managed within each class's size_class structure :
struct __attribute__((aligned(CACHELINE_SIZE))) size_class {
// ...
#if SLAB_QUARANTINE_RANDOM_LENGTH > 0
void *quarantine_random[SLAB_QUARANTINE_RANDOM_LENGTH << (MAX_SLAB_SIZE_CLASS_SHIFT - MIN_SLAB_SIZE_CLASS_SHIFT)];
#endif
#if SLAB_QUARANTINE_QUEUE_LENGTH > 0
void *quarantine_queue[SLAB_QUARANTINE_QUEUE_LENGTH << (MAX_SLAB_SIZE_CLASS_SHIFT - MIN_SLAB_SIZE_CLASS_SHIFT)];
size_t quarantine_queue_index;
#endif
// ...
}
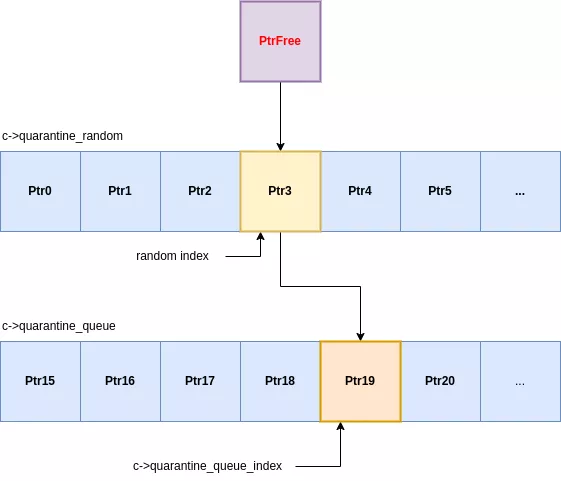
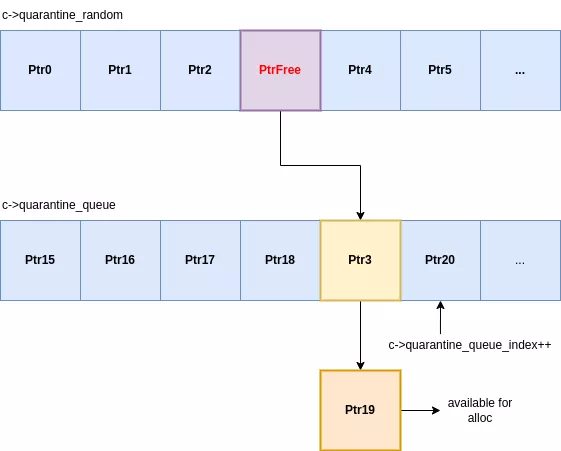
This design is a significant shift from traditional allocators, which use a simple LIFO (Last-In, First-Out) freelist. In hardened malloc, the last item freed is never the first to be reallocated. To reclaim a specific slot, an attacker must trigger enough free operations to successfully cycle their target slot through both the random quarantine and the queue quarantine. This adds a substantial layer of non-determinism and complexity to use-after-free exploits, providing a robust defense even on devices that lack MTE.
Since the allocator has no freelist, the most straightforward way to force a reuse is to chain calls to malloc and free. The number of free operations required depends on the quarantine sizes for that specific size class.
void reuse(void* target_ptr, size_t size) {
free(target_ptr);
for (int i = 0; ; i++) {
void* new_ptr = malloc(size);
if (untag(target_ptr) == untag(new_ptr)) {
printf("REUSED [size = 0x%x] target_ptr @ %p (new_ptr == %p) try = %d\n", size, target_ptr, new_ptr, i);
break;
}
free(new_ptr);
}
}
For an 8-byte allocation, both quarantines hold 8,192 elements. While this implies at least 8,192 frees are needed, the random nature of the first stage means the actual number is far greater. In testing, it required an average of ~19,000 free operations to reliably reclaim a slot. The double quarantine turns predictable memory reuse into a costly and unreliable lottery, severely hindering a common exploit vector.
$ make launch
adb push libs/arm64-v8a/test /data/local/tmp
libs/arm64-v8a/test: 1 file pushed, 0 skipped. 0.5 MB/s (5192 bytes in 0.009s)
adb shell /data/local/tmp/test
REUSED [size = 0x8] ptr @ 0xb400c7a41875fa50 (new_ptr == 0xb400c7a41875fa50) try = 18327
Large allocations
Alloc
Unlike small allocations, large allocations are not sorted by size into pre-reserved regions. Instead, the allocator maps them on demand. This mechanism is the only one in hardened malloc that dynamically creates memory mappings. The total size of the mapping depends on several factors:
- Aligned Size: computed in
get_large_size_classby aligning the requested size to predefined classes, continuing from the small allocation sizes. - Guard Page Size: a random number of pages preceding and following the actual allocation.
static size_t get_large_size_class(size_t size) {
if (CONFIG_LARGE_SIZE_CLASSES) {
// Continue small size class growth pattern of power of 2 spacing classes:
//
// 4 KiB [20 KiB, 24 KiB, 28 KiB, 32 KiB]
// 8 KiB [40 KiB, 48 KiB, 54 KiB, 64 KiB]
// 16 KiB [80 KiB, 96 KiB, 112 KiB, 128 KiB]
// 32 KiB [160 KiB, 192 KiB, 224 KiB, 256 KiB]
// 512 KiB [2560 KiB, 3 MiB, 3584 KiB, 4 MiB]
// 1 MiB [5 MiB, 6 MiB, 7 MiB, 8 MiB]
// etc.
return get_size_info(max(size, (size_t)PAGE_SIZE)).size;
}
return page_align(size);
}
Once these sizes are determined, the allocator creates a mapping via mmap() for their combined total. The guard areas before and after the data are mapped with PROT_NONE, while the data region itself is mapped PROT_READ|PROT_WRITE. This use of randomly sized guard pages means that two large allocations of the same requested size will occupy mapped areas of different total sizes, adding a layer of non-determinism.
void *allocate_pages_aligned(size_t usable_size, size_t alignment, size_t guard_size, const char *name) {
//...
// Compute real mapped size = alloc_size + 2 * guard_size
size_t real_alloc_size;
if (unlikely(add_guards(alloc_size, guard_size, &real_alloc_size))) {
errno = ENOMEM;
return NULL;
}
// Mapping whole region with PROT_NONE
void *real = memory_map(real_alloc_size);
if (unlikely(real == NULL)) {
return NULL;
}
memory_set_name(real, real_alloc_size, name);
void *usable = (char *)real + guard_size;
size_t lead_size = align((uintptr_t)usable, alignment) - (uintptr_t)usable;
size_t trail_size = alloc_size - lead_size - usable_size;
void *base = (char *)usable + lead_size;
// Change protection to usable data with PROT_RAD|PROT_WRITE
if (unlikely(memory_protect_rw(base, usable_size))) {
memory_unmap(real, real_alloc_size);
return NULL;
}
//...
return base;
}
If the mapping is successful, a structure containing the address, usable size, and guard size is inserted into a hash table of regions. This hash table is implemented using two arrays of region_metadata structs: allocator_state.regions_a and allocator_state.regions_b (referenced as ro.regions[0] and ro.regions[1]). These arrays have a static size and are reserved at initialization.
Initially, only a portion of these arrays is accessible (marked Read/Write); the rest is protected with PROT_NONE. As the number of active large allocations grows and exceeds the available metadata slots, the accessible portion of the arrays is doubled. This expansion uses a two-table system: the current hash table is copied to the previously unused table, which then becomes the active one. The old table is re-mapped back to PROT_NONE to render it inaccessible.
static int regions_grow(void) {
struct region_allocator *ra = ro.region_allocator;
if (ra->total > SIZE_MAX / sizeof(struct region_metadata) / 2) {
return 1;
}
// Compute new grown size
size_t newtotal = ra->total * 2;
size_t newsize = newtotal * sizeof(struct region_metadata);
size_t mask = newtotal - 1;
if (newtotal > MAX_REGION_TABLE_SIZE) {
return 1;
}
// Select new metadata array
struct region_metadata *p = ra->regions == ro.regions[0] ?
ro.regions[1] : ro.regions[0];
// Enlarge new metadata elements
if (memory_protect_rw_metadata(p, newsize)) {
return 1;
}
// Copy elements to the new array
for (size_t i = 0; i < ra->total; i++) {
const void *q = ra->regions[i].p;
if (q != NULL) {
size_t index = hash_page(q) & mask;
while (p[index].p != NULL) {
index = (index - 1) & mask;
}
p[index] = ra->regions[i];
}
}
memory_map_fixed(ra->regions, ra->total * sizeof(struct region_metadata));
memory_set_name(ra->regions, ra->total * sizeof(struct region_metadata), "malloc allocator_state");
ra->free = ra->free + ra->total;
ra->total = newtotal;
// Switch current metadata array/hash table
ra->regions = p;
return 0;
}
Eventually, allocation metadata, address + size + guard size, is inserted in the current hash table ro.region_allocator->regions.
For large allocations, which are not protected by MTE, the randomly sized guard pages are the primary defense against overflows. If an attacker can bypass this randomization and has an out-of-bounds read/write vulnerability with a precise offset, corrupting adjacent data remains a possible, though complex, scenario.
For example, a call to malloc(0x28001) creates the following metadata. A random guard size of 0x18000 bytes was chosen by the allocator.
large alloc @ 0xc184d36f4ac8
ptr : 0xbe6cadf4c000
size : 0x30000
guard size: 0x18000
By inspecting the process's memory maps, we can see that the large allocation (which aligns to a size of 0x30000) is securely sandwiched between two PROT_NONE guard regions, each 0x18000 bytes in size.
be6cadf34000-be6cadf4c000 ---p 00000000 00:00 0
be6cadf4c000-be6cadf7c000 rw-p 00000000 00:00 0
be6cadf7c000-be6cadf94000 ---p 00000000 00:00 0
Free
Freeing a large allocation is a relatively simple process that uses the same quarantine mechanism as small allocations.
- Calculate Pointer Hash: the hash of the pointer is calculated to locate its metadata.
- Retrieve Metadata: the allocation's metadata structure is retrieved from the current hash table (
ro->region_allocator.regions). - Quarantine or Unmap: the next step depends on the allocation's size.
- If the size is less than
0x2000000(32 MiB), the allocation is placed into a two-stage quarantine system identical to the one for small allocations (a random-replacement cache followed by a FIFO queue). This quarantine is global for all large allocations and is managed inro.region_allocator. - If the size is
0x2000000or greater, or when an allocation is ejected from the quarantine, it is immediately unmapped from memory. The entire memory region, including the data area and its surrounding guard pages, is unmapped usingmunmap()munmap((char *)usable - guard_size, usable_size + guard_size * 2);
- If the size is less than
Conclusion
Hardened Malloc is a security-hardened memory allocator that implements several advanced protection mechanisms, most notably leveraging the ARM Memory Tagging Extension (MTE) to detect and prevent memory corruption. While it offers an improvement over the standard scudo allocator, particularly against use-after-free vulnerabilities, its true strength lies in its integration with GrapheneOS. This combination achieves a higher level of security than a typical Android device that uses scudo.
Furthermore, the use of canaries and numerous guard pages complements its arsenal, especially on older devices without MTE, by quickly triggering exceptions in case of unwanted memory access.
From an attacker's perspective, hardened malloc significantly reduces opportunities to exploit memory corruption vulnerabilities:
-
Heap overflow: hardened malloc is relatively similar to scudo, yet it adds guard pages between slabs, which prevents an overflow from spreading from one slab to another. However, with MTE enabled, the protection becomes much more granular: even an overflow within the same slab (from one slot to another) is detected and blocked without the need to check canaries, making the exploitation of this type of vulnerability nearly impossible.
-
Use-after-free: the double quarantine mechanism complicates the reuse of a freed memory region but does not make it entirely impossible. However, MTE radically changes the deal. The pointer and its associated memory region are "tagged." Upon being freed, this tag is modified. Any subsequent attempt to use the old pointer (with its now-invalid tag) will very likely raise an exception, neutralizing the attack. For large allocations, which are not covered by MTE, the strategy is different: each allocation is isolated by guard pages and its location in memory is randomized. This combination of isolation and randomization makes any attempt to reuse these memory regions difficult and unreliable for an attacker.
Additionally, its implementation has proven to be particularly clear and concise, facilitating its audit and maintenance.