Kubernetes forensics 1/3 : what the container ?
En 2025, le CSIRT Synacktiv a observé une augmentation significative des attaques et des compromissions ciblant les environnements Kubernetes. Le constat est que ces attaques sont vouées à continuer de se multiplier au même rythme que la technologie elle-même. Afin de mieux comprendre le fonctionnement d'un cluster Kubernetes et comment investiguer lors d'un incident de sécurité, nous avons décidé de travailler sur une série d'articles consacrée à la forensique Kubernetes. Celui-ci est le premier de la série, et se concentre sur la technologie sous-jacente des conteneurs.
Looking to improve your skills? Discover our trainings sessions! Learn more.
Introduction
Kubernetes s'est imposé comme la solution d'orchestration des infrastructures cloud-native modernes, gérant le déploiement et la mise à l'échelle d'applications à grande ampleur. Des entreprises de toutes tailles montent à bord du navire Kubernetes, attirées par les promesses d'une scalabilité infinie et de coûts de calcul optimisés.
En réalité, la situation est un peu plus complexe. Il est vrai que Kubernetes a beaucoup à offrir en termes de déploiement d'un grand nombre d'applications dans un environnement (souvent) entièrement managé. Pouvoir se concentrer sur des tâches productives plutôt que de gérer une douzaine de serveurs est primordial pour une jeune structure disposant de peu de temps et de ressources humaines.
Les clusters Kubernetes ne sont pas sans défauts, ils sont complexes et difficiles à administrer. Ce qu'ils offrent en fonctionnalités et en facilité d'utilisation se paie par une couche technique complexe qui est, le plus souvent, encore abstraite et obscure pour les personnes qui l'utilisent.
Dans une quête permanente de simplicité, les plus grands fournisseurs cloud tendent à proposer une interface toujours plus simple pour déployer et utiliser les ressources Kubernetes via leurs consoles en ligne. Ainsi, il est possible de créer un compte puis d'utiliser directement l'une des nombreuses offres Kubernetes managées : AKS pour Azure, EKS pour AWS ou GKE pour Google Cloud et de déployer des applications conteneurisées.
D'un point de vue forensique, l'architecture distribuée de la plateforme, la variété de ses composants et la nature volatile de ses charges de travail compliquent considérablement la collecte et la préservation des artéfacts forensiques. Mais ça, ce sera pour une prochaine fois.
Dans cet article, nous allons revenir aux fondamentaux du fonctionnement de Kubernetes. Quelles sont les couches techniques, qu'est-ce qu'un conteneur, comment fonctionnent-ils, autant de questions auxquelles nous répondrons ici.
Qu'est-ce qu'un conteneur ?
Remontons un peu dans le temps.
Vous venez de vous réveiller, nous sommes en février 2009, vous arrivez au travail. Le nouveau logiciel monolithique de planification des ressources d'entreprise (ERP) doit être déployé en production. Il a 524 dépendances, cinq bases de données, deux reverse proxies (??). L'installation prend cinq heures, plante à mi-chemin une fois sur deux sans option de récupération. À chaque fois, il faut réinstaller le serveur parce que, pour une raison inconnue, les dépendances finissent par casser OpenSSH. Après deux semaines d'enfer, vous y parvenez enfin, le logiciel est prêt pour la production.
Maintenant, avançons dans le temps, nous sommes en 2026, imaginez que vous puissiez empaqueter votre logiciel dans une petite coquille, qui inclurait toutes les dépendances, tous les services annexes. Ce conteneur pourrait embarquer tout ce dont vous avez besoin pour faire tourner le nouvel ERP en production, sur n'importe quel serveur, à n'importe quel moment. Vous pouvez exécuter le conteneur sur n'importe quel serveur et redémarrer tous les services avec une seule commande. Si l'installation échoue, vous pouvez le supprimer et en relancer un nouveau avec un correctif. L'hôte resterait le même, tout serait contenu. Chaque conteneur serait isolé de tous les autres tournant sur le même hôte.
Les conteneurs apportent une couche d'abstraction aux systèmes de base sur lesquels ils s'exécutent. Ils permettent aux applications, de toute nature, d'être contraintes par un ensemble de limites, sans la surcharge qu'imposent les machines virtuelles traditionnelles.
Conteneurs vs Machines Virtuelles
Une idée reçue courante est que ces deux outils, les conteneurs et les machines virtuelles (VMs), sont identiques. Ce n'est pas le cas.
Une machine virtuelle peut être représentée comme une boîte, tout comme un conteneur. Mais là où un conteneur ne contient que l'application nécessaire et ses dépendances, une machine virtuelle contient l'intégralité du système d'exploitation. Un conteneur s'exécute sur l'hôte via un moteur de conteneurs (Docker, Podman), la machine virtuelle tourne sur un hyperviseur (Hyper-V, VMWare vSphere, libvirt, etc.).
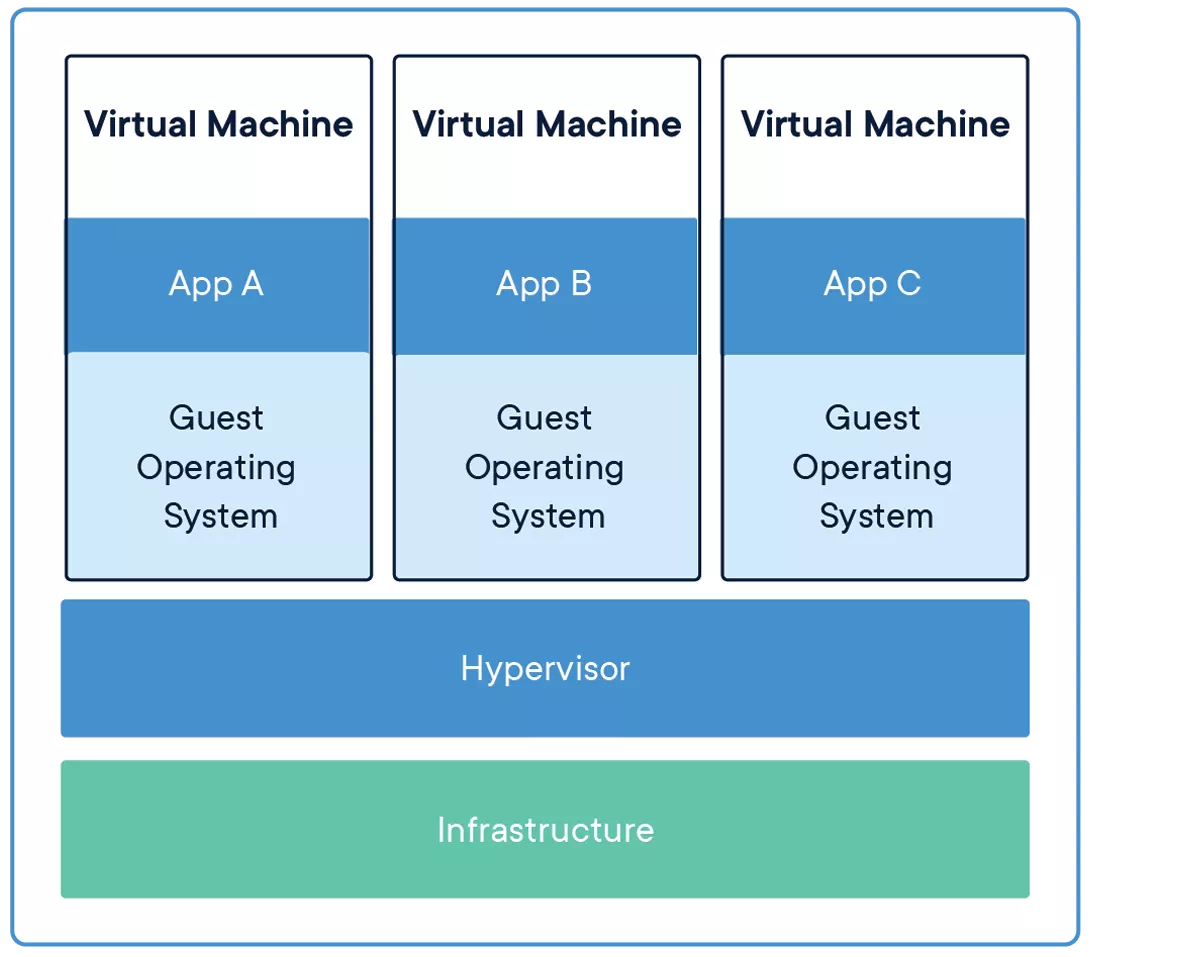
La machine virtuelle offre une meilleure isolation, mais est le plus souvent plus volumineuse, plus lente à l'exécution et impose davantage de surcharge. Un conteneur est plus léger, plus facile à déployer, à démarrer et à arrêter à volonté, et trivial à recréer si nécessaire.
Spécifications des conteneurs
Les conteneurs peuvent être utilisés sur un large éventail de systèmes d'exploitation et de hardware. Presque toutes les applications publiées sous forme de conteneurs peuvent tourner n'importe où. Cela est dû à la spécification OCI.
OCI signifie Open Container Initiative. C'est une structure de gouvernance rattachée à la Linux Foundation qui maintient des standards ouverts pour les conteneurs. Elle a été créée en 2015, principalement parce que Docker était devenu le standard de facto et que l'industrie souhaitait que les formats de conteneurs et les runtimes ne soient pas contrôlés par une seule entreprise.
L'OCI maintient trois spécifications :
- Spécification du runtime : définit comment exécuter un conteneur. Elle décrit ce qu'un runtime de conteneurs doit attendre en entrée et comment il doit se comporter (create, start, kill, delete). Si le runtime suit cette spécification, il peut exécuter n'importe quel conteneur conforme à l'OCI.
- Spécification des image : définit à quoi ressemble une image de conteneur. Une image OCI est essentiellement un manifeste (métadonnées sur l'image), un ensemble de couches de système de fichiers (tarballs) et une configuration (quelle commande exécuter, quelles variables d'environnement définir, etc.). C'est pourquoi il est possible de construire une image avec Docker et de l'exécuter avec Podman, ou de la pousser vers n'importe quel registre compatible. Le format est le même.
- Spécification de distribution : définit comment les images sont poussées vers et tirées depuis les registres. Elle standardise l'API HTTP que les registres exposent de sorte que n'importe quel client compatible puisse communiquer avec n'importe quel registre conforme. Docker Hub, GitHub Container Registry, Quay, un registre autohébergé : tous parlent le même protocole.
Avant l'OCI, le format d'image et le runtime de Docker étaient le standard simplement parce que Docker était partout. L'OCI a repris ce que Docker avait construit, l'a formalisé et l'a rendu neutre vis-à-vis des providers. C'est pourquoi aujourd'hui, il est possible de mélanger et d'assortir des outils de différents projets et que tout fonctionne ensemble.
Les conteneurs ne sont pas magiques
Quand vous tapez dans un terminal docker run debian /app, plusieurs événements se produisent en coulisses. D'abord, le client docker, la CLI que vous venez d'utiliser, va interagir avec le daemon docker via un socket UNIX et des requêtes HTTP, généralement /var/run/docker.sock. Ce daemon écoute sur le socket et agit en fonction des requêtes reçues.
Le daemon docker utilise containerd, un container runtime capable de gérer le cycle de vie complet d'un conteneur :
- Push et pull d'images
- Transfert et stockage d'images
- Exécution et supervision des conteneurs
- etc.
À son tour, containerd utilise runc pour créer et exécuter les conteneurs.
runc est une application open source qui implémente la spécification OCI runtime, ce qui signifie qu'elle est responsable de dialoguer directement avec le noyau Linux pour mettre en place l'environnement du conteneur.
runc prend un bundle de système de fichiers (le système de fichiers racine du conteneur) et un fichier de configuration JSON, puis utilise une combinaison de fonctionnalités du noyau Linux pour isoler le processus :
- Namespaces pour donner au processus sa propre vision du système (PID, réseau, montage, utilisateur, etc.)
- cgroups pour limiter et comptabiliser l'utilisation des ressources (CPU, mémoire, I/O)
- Profils seccomp pour restreindre les appels système que le processus peut effectuer
- Capabilities pour ajuster finement les privilèges du processus
En d'autres termes, un conteneur n'est qu'un processus Linux ordinaire avec tout un tas d'isolation collée par-dessus. runc est l'outil qui met en place toute cette isolation, lance le processus, puis s'efface. Si vous souhaitez en savoir plus sur le fonctionnement de runc, lisez cet excellent article de Quarkslab : https://blog.quarkslab.com/digging-into-runtimes-runc.html
Maintenant, runc ne gère que le cycle de vie d'un seul conteneur : il le crée, le démarre, le supprime. Il ne se soucie ni des images, ni des registres, ni du réseau. C'est pour cela que containerd est nécessaire.
containerd se situe entre le client de haut niveau (comme Docker) et le runtime de bas niveau (runc). Il gère la tuyauterie nécessaire : tirer les images depuis un registre, les décompresser en bundles de système de fichiers que runc peut comprendre, gérer les snapshots et le stockage, prendre en charge les logs des conteneurs et superviser les conteneurs en cours d'exécution.
Il est d'ailleurs possible d'utiliser containerd sans Docker, via son outil CLI ctr ou sa bibliothèque client Go. Docker n'est en réalité qu'un frontend possible parmi d'autres.
La baleine ou le phoque ?
Maintenant que nous savons que Docker repose sur un daemon (dockerd) qui écoute sur un socket et gère tout via containerd, parlons de Podman, car il adopte une approche différente.
En 2026, deux grands projets open source se partagent la vedette, Podman et Docker. Docker étant le plus ancien et Podman, créé par Red Hat, le plus récent.
La différence la plus notable est que Podman fonctionne sans daemon. Il n'y a pas de processus en arrière-plan gérant les conteneurs en permanence. Quand vous exécutez podman run debian app, Podman interagit directement avec le runtime de conteneurs (il utilise crun par défaut, une alternative légère à runc écrite en C) et le noyau Linux.
Dans un environnement Podman, les conteneurs sont des processus fils de conmon, un petit processus léger dont le seul rôle est de surveiller le conteneur. conmon gère le terminal du conteneur, transmet les logs, garde trace de l'exit code et maintient la connexion avec le runtime.
Avec Docker, chaque conteneur est un processus fils du daemon. Cela signifie que le daemon est un point de défaillance unique : si dockerd plante, tous les conteneurs en cours d'exécution deviennent orphelins. Cela signifie aussi que le daemon tourne généralement en root, et que tout utilisateur interagissant avec le socket Docker dispose effectivement d'un accès root sur l'hôte. C'est un problème de sécurité bien connu depuis des années.
Podman a été conçu avec les conteneurs rootless à l'esprit. Mais faire tourner des conteneurs sans root n'est pas trivial — de nombreuses fonctionnalités sur lesquelles les conteneurs s'appuient nécessitent normalement des privilèges. Podman doit contourner plusieurs d'entre elles.
Les user namespaces en sont le fondement. Podman crée un namespace utilisateur dans lequel un utilisateur non privilégié est mappé sur l'UID 0 à l'intérieur du conteneur. Le processus pense être root, mais du point de vue de l'hôte, il reste un utilisateur ordinaire. Le mapping est configuré via /etc/subuid et /etc/subgid, qui définissent une plage d'UIDs/GIDs subordonnés que l'utilisateur est autorisé à utiliser.
❯ podman run -it --rm debian bash
root@ac3ad87f788f:/# ps -aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 4328 3740 pts/0 Ss 14:56 0:00 bash
root 127 0.0 0.0 6392 3872 pts/0 R+ 14:57 0:00 ps -aux
root@ac3ad87f788f:/# id
uid=0(root) gid=0(root) groups=0(root)
Ici, l'ID du conteneur commence par ac3ad87f788f.
❯ ps
USER PID PPID COMMAND
analyst 1922 1 /usr/lib/systemd/systemd --user
analyst 275235 1922 /usr/bin/pasta --config-net --dns-forward 169.254.1.1 -t none -u none[...]
analyst 275237 1922 /usr/bin/conmon --api-version 1 -c ac3ad87f788f[...]
analyst 275243 275237 bash
Comme on peut le voir, nous vivons sous l'utilisateur 0 (root) dans le conteneur. Mais sur l'hôte, nous n'exécutons le conteneur qu'en tant qu'utilisateur analyst ordinaire. D'ailleurs, créer un fichier dans le conteneur via un bind mount en tant qu'utilisateur 0 créera un fichier sur le système de fichiers de l'hôte appartenant à l'utilisateur qui a lancé le conteneur, ici analyst.
❯ podman run -it -v /data:/data --rm debian touch /data/hello.txt
❯ ls -alh /data/hello.txt
-rw-r--r-- 1 analyst analyst 0 Feb 25 16:18 hello.txt
Le réseau, c'est là que ça devient intéressant, car créer des interfaces réseau et configurer iptables nécessite normalement des privilèges root.
La solution originale était slirp4netns. Il crée un périphérique TAP à l'intérieur du namespace réseau du conteneur et route le trafic à travers une pile TCP/IP en espace utilisateur. Cette solution, bien que fonctionnelle, n'est pas idéale. Les performances sont bien en dessous de son équivalent rootful.
L'alternative plus récente est pasta (du projet passt). Au lieu d'émuler une pile réseau, il échange entre les namespaces en passant des files descriptors de sockets, ce qui offre des performances quasi natives. Depuis Podman 5.0, pasta est le défaut et slirp4netns déprécié.
Le stockage nécessite aussi une gestion particulière. Monter un overlay nécessite traditionnellement des privilèges, c'est pourquoi le Podman rootless s'appuyait auparavant sur fuse-overlayfs, une implémentation en espace utilisateur via FUSE. Sur les noyaux récents (5.11+), les montages overlay non privilégiés sont supportés nativement à l'intérieur des user namespaces, ce qui rend fuse superflu dans la plupart des cas.
Côté CLI, Podman est largement un remplacement direct. La plupart des commandes docker se traduisent directement : podman build, podman pull, podman run. On pourrait presque aliaser docker vers podman.
Une particularité que Podman introduit et que Docker ne possède pas nativement est le concept de pods. Un pod est un groupe de conteneurs qui partagent le même namespace réseau (et éventuellement d'autres namespaces). Si cela vous semble familier, c'est parce que le concept vient directement de Kubernetes. Vous pouvez créer un pod, y placer quelques conteneurs, et ils peuvent communiquer entre eux via localhost. Podman peut même générer du YAML Kubernetes à partir d'un pod en cours d'exécution, ce qui peut être pratique si vous prototypez localement avant de déployer sur un cluster.
Sous le capot, Podman utilise un stockage et une gestion d'images différents. Il s'appuie sur les bibliothèques containers/image et containers/storage (de l'écosystème containers au sens large), tandis que Docker passe par containerd pour cela. En pratique, les deux tirent depuis les mêmes registres conformes OCI et produisent des images conformes OCI.
Analyse forensique
Maintenant que nous savons (presque) tout ce qu'il y a à savoir sur les conteneurs, nous pouvons plonger dans la forensique.
Comme nous l'avons vu précédemment, analyser des conteneurs Podman et Docker ne sera pas exactement la même chose, même si la spécification OCI facilite les choses. Plusieurs outils communautaires peuvent aussi aider à analyser les images OCI et l'exécution des processus. Il existe plusieurs façons d'analyser les conteneurs et on peut les diviser en deux catégories :
- Conteneur
- Image
Un conteneur est le processus qui tourne actuellement sur votre hôte. L'image est un blob OCI stocké sur le registre à pull quand vous voulez exécuter l'application. Pour rendre ces concepts plus clairs, vous pouvez voir le conteneur comme le processus et l'image comme le fichier exécutable, en sémantique OS classique.
Analyser le conteneur ressemble beaucoup à l'analyse d'une application classique sous Linux. Après tout, et comme nous l'avons vu, un conteneur n'est qu'un processus dans un namespace.
Analyser une image, en revanche nécessitera des outils supplémentaires.
Système de fichiers des conteneurs
Comme toute application, les conteneurs ont besoin d'accéder au système de fichiers pour fonctionner. Ils ont besoin de leurs propres bibliothèques et leurs fichiers de configuration poussés par le développeur.
Docker, Podman et Kubernetes utilisent le système de fichiers OverlayFS pour fonctionner.
Cet OverlayFS est une technologie qui permet au moteur de fusionner plusieurs couches de fichiers en un système de fichiers définitif.
Prenons par exemple deux conteneurs exécutant l'image ubuntu:latest, qui fait 50 Mo. Avec OverlayFS, une seule copie des fichiers Ubuntu est nécessaire pour que ces deux conteneurs fonctionnent. Cette première couche, partagée, est en lecture seule. OverlayFS va créer, par-dessus cette couche, deux couches indépendantes et isolées pour les conteneurs A et B respectivement. Ces deux couches indépendantes seront utilisées par les conteneurs pour le stockage des fichiers à l'exécution.
OverlayFS possède 4 types de couches :
- UpperDir : couche en lecture-écriture, une par conteneur, stockage des fichiers à l'exécution
- LowerDir : couches partagées (image Ubuntu), en lecture seule
- MergedDir : vue fusionnée de l'UpperDir et du LowerDir dans un seul répertoire
- WorkDir : répertoire interne utilisé par OverlayFS pour préparer le MergedDir
Pour un conteneur individuel sous Docker, trouver les chemins sur l'hôte se fait avec la commande docker inspect container-id | jq .[0].GraphDriver.Data et le répertoire /var/lib/docker/overlay2/. Attention, l'ID du conteneur n'est pas le même que l'ID de stockage.
La commande pour Podman est identique podman inspect container-id | jq .[0].GraphDriver.Data tandis que les chemins sont :
/home/user/.local/share/containers/storage/overlaypour les conteneurs Podman rootless/var/lib/containers/storage/overlaypour les conteneurs Podman rootful
$ docker run -it debian bash
root@1f02808c8b83:/#
$ docker inspect 1f02808c8b83 | jq .[0].GraphDriver.Data
{
"ID": "1f02808c8b83418c9479ec7c82e11d5670b5a0877120d57f3fbcc291597e535a",
"LowerDir": "/var/lib/docker/overlay2/6a3280[...]a8e1c4-init/diff:/var/lib/docker/overlay2/7929cc[...]042892/diff",
"MergedDir": "/var/lib/docker/overlay2/6a3280[...]a8e1c4/merged",
"UpperDir": "/var/lib/docker/overlay2/6a3280[...]a8e1c4/diff",
"WorkDir": "/var/lib/docker/overlay2/6a3280[...]a8e1c4/work"
}
Voici ce que contient l'UpperDir lorsqu'on crée un nouveau fichier à l'exécution.
$ docker run -it debian bash
root@1f02808c8b83:/# touch hello.txt
Avant :
# sudo tree /var/lib/docker/overlay2/6a3280d[...]/diff
/var/lib/docker/overlay2/6a3280d[...]/diff
Après :
# sudo tree /var/lib/docker/overlay2/6a3280d[...]/diff
/var/lib/docker/overlay2/6a3280d[...]/diff
└── hello.txt
1 directory, 1 file
Et dans le MergedDir on trouve :
# ls -alh /var/lib/docker/overlay2/6a3280d[...]/merged
total 68K
drwxr-xr-x 1 root root 4.0K Aug 5 17:35 .
drwx--x--- 5 root root 4.0K Aug 5 17:29 ..
lrwxrwxrwx 1 root root 7 Jul 21 02:00 bin -> usr/bin
drwxr-xr-x 2 root root 4.0K May 9 16:50 boot
drwxr-xr-x 1 root root 4.0K Aug 5 17:29 dev
-rwxr-xr-x 1 root root 0 Aug 5 17:29 .dockerenv
drwxr-xr-x 1 root root 4.0K Aug 5 17:29 etc
-rw-r--r-- 1 root root 0 Aug 5 17:35 hello.txt
drwxr-xr-x 2 root root 4.0K May 9 16:50 home
lrwxrwxrwx 1 root root 7 Jul 21 02:00 lib -> usr/lib
lrwxrwxrwx 1 root root 9 Jul 21 02:00 lib64 -> usr/lib64
drwxr-xr-x 2 root root 4.0K Jul 21 02:00 media
drwxr-xr-x 2 root root 4.0K Jul 21 02:00 mnt
drwxr-xr-x 2 root root 4.0K Jul 21 02:00 opt
drwxr-xr-x 2 root root 4.0K May 9 16:50 proc
drwx------ 2 root root 4.0K Jul 21 02:00 root
drwxr-xr-x 3 root root 4.0K Jul 21 02:00 run
lrwxrwxrwx 1 root root 8 Jul 21 02:00 sbin -> usr/sbin
drwxr-xr-x 2 root root 4.0K Jul 21 02:00 srv
drwxr-xr-x 2 root root 4.0K May 9 16:50 sys
drwxrwxrwt 2 root root 4.0K Jul 21 02:00 tmp
drwxr-xr-x 12 root root 4.0K Jul 21 02:00 usr
drwxr-xr-x 11 root root 4.0K Jul 21 02:00 var
Acquisition
Lors de l'investigation d'un hôte conteneurisé, savoir où se trouvent les artéfacts est la première étape. Docker et Podman les stockent différemment.
Pour Docker, les emplacements clés sont :
- Couches OverlayFS :
/var/lib/docker/overlay2 - Logs runtime des conteneurs :
/var/lib/docker/containers/<container_id>/<container_id>.log - Configuration runtime des conteneurs :
/var/lib/docker/containers/<container_id>/config.v2.json
Podman organise les éléments différemment et s'appuie sur journald pour la journalisation par défaut :
- Couches OverlayFS :
- Rootless :
/home/user/.local/share/containers/storage/overlay - Rootful :
/var/lib/containers/storage/overlay
- Rootless :
- Logs runtime des conteneurs :
- Vérifier le driver de logs avec
podman info --format '{{.Host.LogDriver}}' - Driver journald :
journalctl -a CONTAINER_ID_FULL=containerID - Driver json-file :
/home/user/.local/share/containers/storage/overlay-containers/<id>/userdata/ctr.log
- Vérifier le driver de logs avec
- Configuration runtime des conteneurs :
/home/user/.local/share/containers/storage/overlay-containers/<id>/userdata/config.json
❯ journalctl -a CONTAINER_ID_FULL=containerID
Feb 27 15:20:01 user container[2309114]: root@c5676c4f3baf:/#
Feb 27 15:20:03 user container[2309114]: root@c5676c4f3baf:/# echo pouet
Feb 27 15:20:03 user container[2309114]: pouet
Un point important : tous ces artéfacts (sauf les logs journald) sont détruits à la sortie du conteneur lorsque le flag --rm est utilisé.
Artéfacts des moteurs
Au-delà des conteneurs individuels, les moteurs eux-mêmes produisent des logs utiles.
Le daemon Docker journalise vers journald ou /var/log/syslog et peut être interrogé avec journalctl -xeu docker.service. Avec la journalisation en mode debug activée, les traces des appels API, des pulls d'images et de la création de conteneurs sont enregistrés :
level=debug msg="handling POST request" method=POST module=api request-url="/v1.51/images/create?fromImage=docker.io%2Flibrary%2Fdebian&tag=latest" vars="map[version:1.51]"
level=debug msg="Trying to pull debian from https://registry-1.docker.io"
level=debug msg="Fetching manifest from remote" digest="sha256:b650[...]deba" error="<nil>" remote="debian:latest"
level=debug msg="Pulling ref from V2 registry: debian:latest" digest="sha256:b650[...]deba" remote="debian:latest"
level=debug msg="pulling blob \"sha256:ebed[...]749f\""
level=debug msg="Using /usr/bin/unpigz to decompress"
level=debug msg="handling POST request" form-data="[...]" method=POST module=api request-url=/v1.51/containers/create
vars="map[version:1.51]"
Podman n'a pas de daemon, il n'y a donc pas de logs de daemon. À la place, il enregistre les événements soit via journald, soit dans un fichier sur disque. Vous pouvez vérifier quel backend est utilisé avec podman info | grep event.
Sur un système en fonctionnement, podman events diffuse les événements en temps réel. Pour consulter l'activité passée, utilisez podman events --since 2025 :
2026-02-25 16:18:35 image pull a3624dd[...]2a74256 debian
2026-02-25 15:56:41 container init ac3ad87[...]17e7b12 (image=debian:latest, name=hopeful_meitner)
2026-02-25 15:56:41 container start ac3ad87[...]17e7b12 (image=debian:latest, name=hopeful_meitner)
2026-02-25 15:56:41 container attach ac3ad87[...]17e7b12 (image=debian:latest, name=hopeful_meitner)
2026-02-25 15:56:48 container kill ac3ad87[...]17e7b12 (image=debian:latest, name=hopeful_meitner)
2026-02-25 16:18:19 container died ac3ad87[...]17e7b12 (image=debian:latest, name=hopeful_meitner)
2026-02-25 16:18:19 container remove ac3ad87[...]17e7b12 (image=debian:latest, name=hopeful_meitner)
Investigation live
Si vous avez accès à un système en fonctionnement, les moteurs de conteneurs fournissent des commandes qui rendent le triage plus facile :
- Lister les conteneurs en cours d'exécution :
docker ps/podman ps - Lister les images :
docker image ls/podman images - Exporter un conteneur en cours d'exécution pour analyse hors ligne :
docker export <containerID> --output container.tar - Exporter une image :
docker save <image> --output image.tar - Lister les modifications du système de fichiers entre un conteneur et son image de base :
docker diff <containerID> - Extraire un fichier suspect d'un conteneur en cours d'exécution :
docker cp <containerID>:/chemin/vers/fichier /chemin/hôte - Le comparer avec l'original depuis une image propre :
docker run -d <image-originale>docker cp <conteneur-original>:/chemin/vers/fichier-original fichier-originaldiff fichier-original fichier-suspect
Ces commandes fonctionnent de la même manière avec Podman (remplacez docker par podman).
Post-mortem
Le scénario le plus courant : on vous remet une image disque d'un hôte compromis et vous devez comprendre ce qui s'est passé à l'intérieur des conteneurs.
Trois outils de la communauté sont particulièrement utiles ici :
- wagoodman/dive : explorer interactivement chaque couche d'une image de conteneur pour identifier les fichiers ajoutés ou modifiés.
- reproducible-containers/diffoci : comparer deux images côte à côte pour repérer les divergences.
- google/docker-explorer : monter le système de fichiers d'un conteneur à partir d'un répertoire de données Docker (Docker uniquement).
dive vous permet de parcourir une image couche par couche, révélant exactement ce que chaque étape de build a introduit. C'est ainsi que, lors d'une investigation précédente, nous avons identifié une activité malveillante cachée dans ce qui semblait être une image Kali standard :
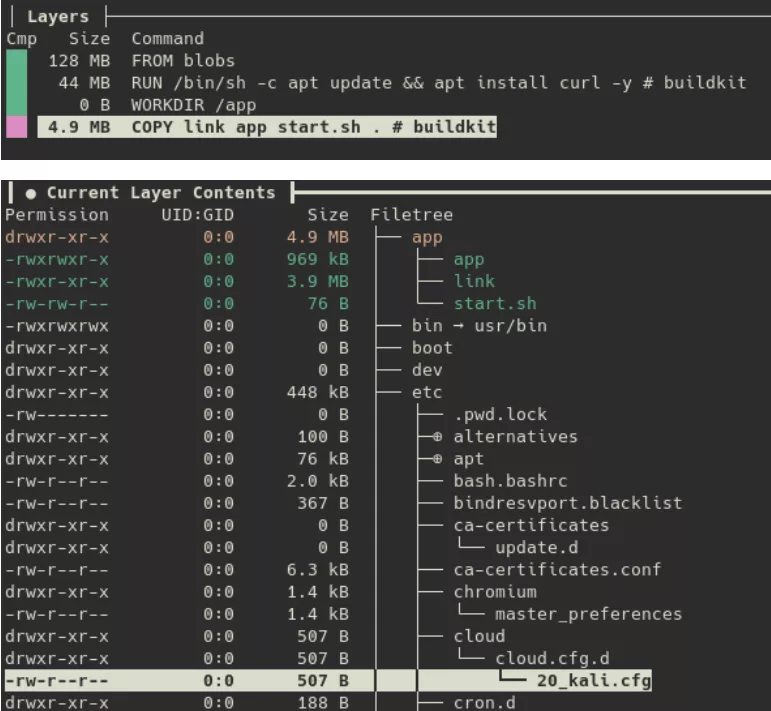
L'acteur malveillant avait ajouté un répertoire app contenant un script shell et deux binaires malveillants, app et link.
diffoci adopte une approche différente : étant donné deux images, il affiche chaque fichier qui diffère. C'est particulièrement utile quand vous soupçonnez qu'une image légitime a été altérée. Par exemple, en comparant une image Debian officielle avec une version locale suspecte :
❯ diffoci diff podman://docker.io/library/debian:latest podman://localhost/debian:latest
Layer ctx:/layer name "usr/" appears 1 times in input 0, 2 times in input 1
Layer ctx:/layer name "etc/" appears 1 times in input 0, 2 times in input 1
Layer ctx:/layer name "usr/bin/" appears 1 times in input 0, 2 times in input 1
Layer ctx:/layer name "etc/" appears 1 times in input 0, 2 times in input 1
Layer ctx:/layer name "etc/wg0.conf" only appears in input 1
Layer ctx:/layer name "usr/" appears 1 times in input 0, 2 times in input 1
Layer ctx:/layer name "usr/bin/wireguard" only appears in input 1
Layer ctx:/layer name "usr/bin/" appears 1 times in input 0, 2 times in input 1
Ici, l'image locale contient un fichier de configuration WireGuard et un binaire qui n'ont rien à faire dans une image de base Debian — probablement pour établir un tunnel. À partir de là, exécuter dive sur l'image permet d'inspecter le contenu de wg0.conf et peut-être de trouver des IOCs supplémentaires.
Conclusion
Comme nous l'avons vu, les conteneurs ne sont pas magiques. Ce sont des processus Linux ordinaires avec des namespaces qui leur donnent leur propre vision du système, des cgroups qui les maintiennent dans les limites, et un OverlayFS qui fournit leur système de fichiers. Une fois que vous comprenez cela, la forensique devient beaucoup moins intimidante — vous ne faites que regarder des processus, des fichiers et des logs.
Nous avons parcouru comment Docker et Podman adoptent différentes approches sous le capot : un daemon centralisé d'un côté, une architecture sans daemon de l'autre. Ces différences comptent en matière de forensique, car elles changent l'emplacement des artéfacts intéressants et la manière dont on les analyse.
Ce n'est cependant que la première étape. En production, les conteneurs tournent rarement seuls. Ils sont orchestrés par Kubernetes, qui ajoute de la complexité avec des composants distribués, des charges de travail éphémères et des artéfacts dispersés à travers les nœuds.