appledb_rs, a research support tool for Apple platforms
Over the years, research on Apple platforms has become significantly more complex, largely due to the numerous countermeasures deployed by the Cupertino company. To address this challenge during our missions on these platforms, we developed appledb_rs: an open-source tool (https://github.com/synacktiv/appledb_rs) that extracts data from IPSW files (archives containing Apple firmware) and organizes it in a structured way, facilitating exploration and analysis.
Looking to improve your skills? Discover our trainings sessions! Learn more.
Initial Need
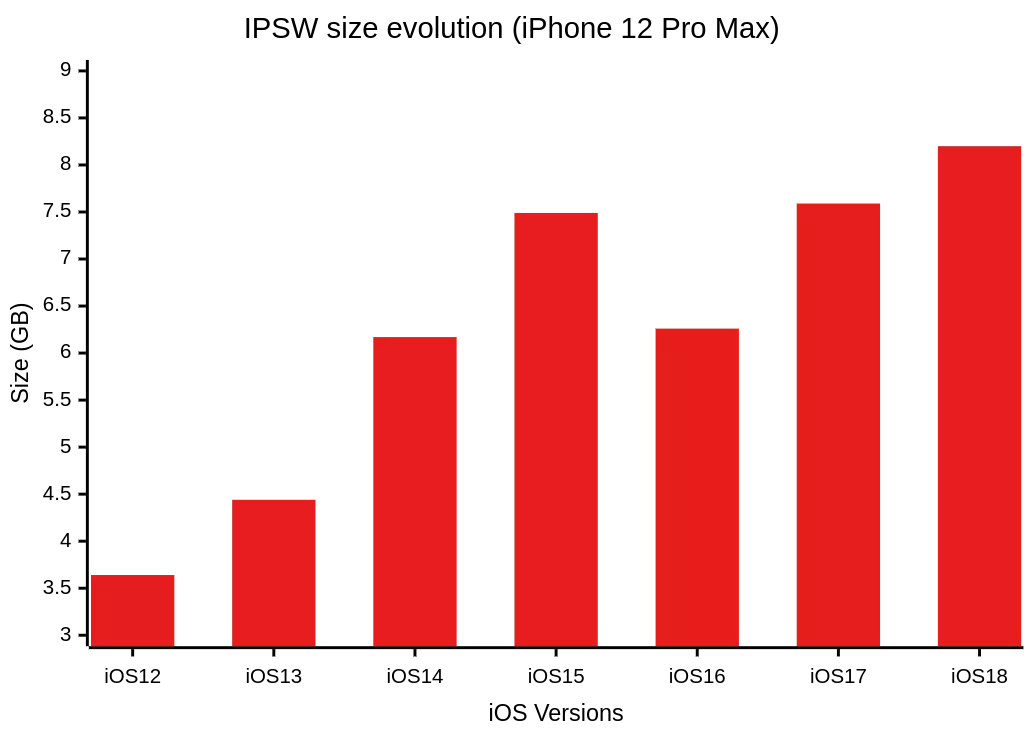
During our missions, we faced an ever-growing volume of IPSW files, whose sizes continue to increase, as shown below with the iPhone 12 Pro Max and the Macbook Air M1. Storing every full image quickly proved costly in terms of space and not suited to our analysis needs. To address this, we developed a solution capable of:
- Extracting metadata and relevant elements without retaining entire IPSW images.
- Automatically indexing a collection of IPSW files while avoiding full storage.
- Storing the extracted information in a structured, storage-optimized database.
- Providing a web interface for efficient data visualization, sorting, and filtering.
- Offering an API to facilitate integrations and automations in analysis pipelines.
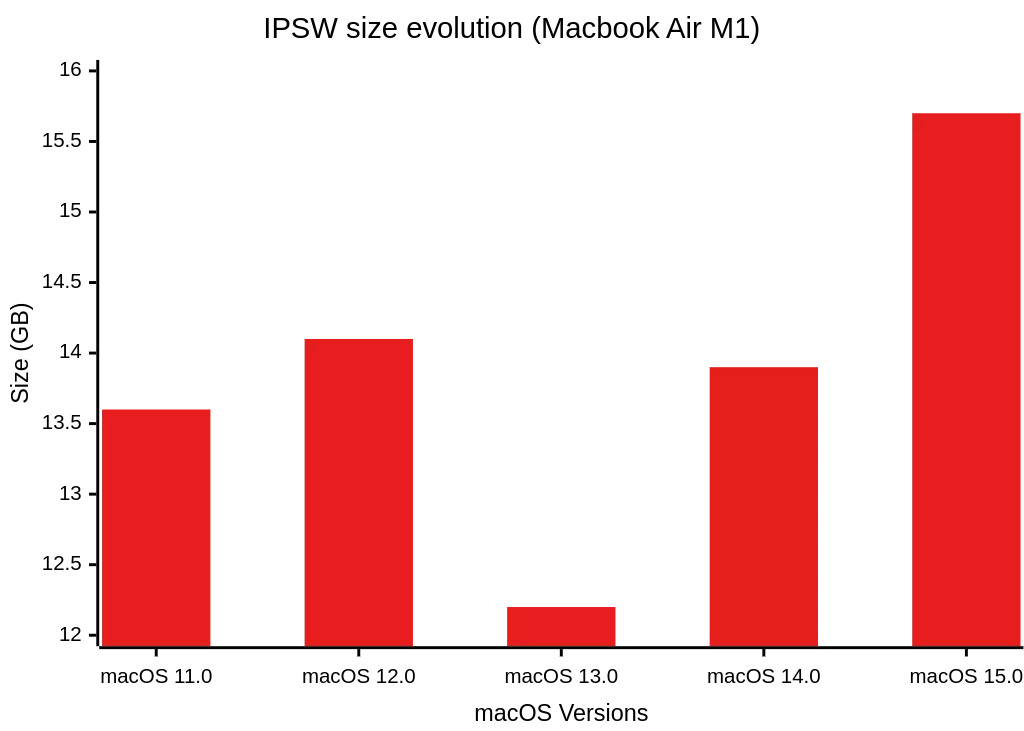
By keeping only the elements truly relevant to our use cases (for example, determining which executables hold a given entitlement -- system-level permissions or capabilities declared by an application -- or use a specific framework), our solution significantly reduces disk space requirements. In addition, the optimized indexing architecture and dedicated web interface ensure near-instant access to information extracted from these system images, thereby accelerating every step of the analysis process.
Initially, our solution focuses on exhaustive indexing of executables present in IPSWs. A dedicated module identifies each binary within the system image and automatically extracts its entitlements, enabling us to precisely reconstruct the permissions and capabilities it holds. At the same time, the frameworks imported by these executables are identified and linked to the relevant binaries, providing an accurate mapping of their dependencies. All of this data is stored relationally in our database, allowing us to move in milliseconds from the name of a binary to its entitlements and the various frameworks it uses. This indexing model drastically reduces storage needs while simplifying investigation and correlation.
Some solutions already exist to (partially) address these needs, such as Jonathan Levin’s well-known site (https://newosxbook.com/ent.php), which allows searching for executables with a given entitlement or listing an executable’s entitlements, the GitHub project entdb, which also focuses only on entitlements, or more recently the ipsw project by @blacktop. To keep full control of our data and guarantee the confidentiality of our research, we chose several months ago to develop a fully self-hosted solution, capable of extracting, indexing, and locally securing sensitive information.
How are entitlements stored in a Mach-O binary?
The Mach-O format relies on a specific header followed by a series of structures called LOAD_COMMAND, which form a list of instructions interpretable by various tools such as the dynamic linker dyld. These commands are essential for describing the structure and runtime behavior of the binary. Their number and total size are specified in the header via the fields ncmds and sizeofcmds. The header format for a 64-bit Mach-O executable is shown below:
/* From xnu source code, xnu/EXTERNAL_HEADERS/mach-o/loader.h */
struct mach_header_64 {
uint32_t magic; /* mach magic number identifier */
cpu_type_t cputype; /* cpu specifier */
cpu_subtype_t cpusubtype; /* machine specifier */
uint32_t filetype; /* type of file */
uint32_t ncmds; /* number of load commands */
uint32_t sizeofcmds; /* the size of all the load commands */
uint32_t flags; /* flags */
uint32_t reserved; /* reserved */
};
The commands are located immediately after this header and each define a cmd type and a total size cmdsize. The rest of the structure can then be specifically interpreted depending on their type.
/* From xnu/EXTERNAL_HEADERS/mach-o/loader.h */
struct load_command {
uint32_t cmd; /* type of load command */
uint32_t cmdsize; /* total size of command in bytes */
};
In the specific context of entitlements and code signing, the LC_CODE_SIGNATURE (cmd=0x1d) command is of particular interest.
struct linkedit_data_command {
uint32_t cmd; /* LC_CODE_SIGNATURE ... */
uint32_t cmdsize; /* sizeof(struct linkedit_data_command) */
uint32_t dataoff; /* file offset of data in __LINKEDIT segment */
uint32_t datasize; /* file size of data in __LINKEDIT segment */
};
The dataoff and datasize fields define the offset of the data within the __LINKEDIT segment, as well as its total size. The structure stored at that offset is a CS_SuperBlob, with magic CSMAGIC_EMBEDDED_SIGNATURE = 0xfade0cc0 in the case of a signature blob.
/* From xnu/osfmk/kern/cs_blobs.h */
typedef struct __SC_SuperBlob {
uint32_t magic; /* magic number */
uint32_t length; /* total length of SuperBlob */
uint32_t count; /* number of index entries following */
CS_BlobIndex index[]; /* (count) entries */
/* followed by Blobs in no particular order as indicated by offsets in index */
} CS_SuperBlob
typedef struct __BlobIndex {
uint32_t type; /* type of entry */
uint32_t offset; /* offset of entry */
} CS_BlobIndex
typedef struct __SC_GenericBlob {
uint32_t magic; /* magic number */
uint32_t length; /* total length of blob */
char data[];
} CS_GenericBlob
Each CSBlobIndex has its own type, and the one of particular interest here is CSMAGIC_EMBEDDED_ENTITLEMENTS = 0xfade7171.
At the indicated offset, there is finally a CS_GenericBlob structure containing the entitlements in its data field, in Apple Binary Plist format.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "https://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>com.apple.apfs.get-dev-by-role</key>
<true/>
<key>com.apple.private.amfi.can-allow-non-platform</key>
<true/>
<key>com.apple.private.iokit.system-nvram-allow</key>
<true/>
<key>com.apple.private.kernel.system-override</key>
<true/>
<key>com.apple.private.persona-mgmt</key>
<true/>
<key>com.apple.private.pmap.load-trust-cache</key>
<array>
<string>cryptex1.boot.os</string
<string>cryptex1.boot.app</string>
<string>cryptex1.safari-downlevel</string>
</array>
<key>com.apple.private.record_system_event</key>
<true/>
<key>com.apple.private.roots-installed-read-write</key>
<true/>
<key>com.apple.private.security.disk-device-access</key>
<true/>
<key>com.apple.private.security.storage.driverkitd</key>
<true/>
<key>com.apple.private.security.storage.launchd</key>
<true/>
<key>com.apple.private.security.system-mount-authority</key>
<true/>
<key>com.apple.private.set-atm-diagnostic-flag</key>
<true/>
<key>com.apple.private.spawn-panic-crash-behavior</key>
<true/>
<key>com.apple.private.spawn-subsystem-root</key>
<true/>
<key>com.apple.private.vfs.allow-low-space-writes</key>
<true/>
<key>com.apple.private.vfs.graftdmg</key>
<true/>
<key>com.apple.private.vfs.pivot-root</key>
<true/>
<key>com.apple.rootless.restricted-block-devices</key>
<true/>
<key>com.apple.rootless.storage.early_boot_mount</key>
<true/>
<key>com.apple.rootless.volume.Preboot</key>
<true/>
<key>com.apple.security.network.server</key>
<true/>
</dict>
</plist>
Entitlements of the launchd binary under macOS 14.0 (Sonoma).
Software stack used for development
The software stack used for this project is fairly standard for client/server/Web infrastructure development.
On the back-end side, the core of the application is built in Rust, chosen for its memory safety guarantees and native performance. We use:
sea_orm, an ergonomic ORM that allows us to model and manipulate our data model.axum, an asynchronous HTTP framework responsible for request routing and middlewares.utoipa, to automatically document our API and make user adoption easier. We generate an OpenAPI schema at each build, ensuring that the API documentation closely reflects reality.
The front-end of our application relies on ReactJS, used to design a reactive and modular interface. Thanks to hooks and a component-based architecture, each view—whether search, dashboard, or visualization of entitlements and frameworks—dynamically adapts to the data retrieved from the server.
Our code is fully database-engine agnostic, thanks to the abstraction provided by sea_orm. This allows us to support both SQLite for lightweight or embedded deployments and PostgreSQL when data volumes or concurrency are increasing. This flexibility is achieved without modifying the application code, thus easing the transition between environments depending on operational constraints.
Finally, the useful ipsw tool can be used to download and extract IPSW files. It also provides the ability to mount system images, allowing navigation within their contents as if directly accessing a running device—particularly useful during exploration or validation phases.
# Download latest version for iPhone11,2 (iPhone XS)
ipsw download ipsw -y --device iPhone11,2 --latest
# Mount an IPSW image as a filesystem using underlying apfs-fuse executable
ipsw mount fs <IPSW_FILE>
Challenges encountered
Database engine independence
The database schema was designed to remain engine-agnostic, with current support for SQLite and PostgreSQL. The goal is not to impose a particular technology, but to offer multiple compatible options so that each deployment can adapt to specific operational and security constraints.
The ORM used, sea_orm, facilitates this abstraction by encapsulating the concrete engine behind the DatabaseConnection enum, which implements the ConnectionTrait. This allows SQL queries to be executed via a unified interface, regardless of the backend. This approach ensures generic code while allowing for engine-specific optimizations.
Moreover, sea_orm also supports MySQL, which could eventually be offered as an alternative backend without major application code changes.
// sea_orm: src/database/db_connection.rs
pub enum DatabaseConnection {
/// Create a MYSQL database connection and pool
#[cfg(feature = "sqlx-mysql")]
SqlxMySqlPoolConnection(crate::SqlxMySqlPoolConnection),
/// Create a PostgreSQL database connection and pool
#[cfg(feature = "sqlx-postgres")]
SqlxPostgresPoolConnection(crate::SqlxPostgresPoolConnection),
/// Create a SQLite database connection and pool
#[cfg(feature = "sqlx-sqlite")]
SqlxSqlitePoolConnection(crate::SqlxSqlitePoolConnection),
/// Create a Mock database connection useful for testing
#[cfg(feature = "mock")]
MockDatabaseConnection(Arc<crate::MockDatabaseConnection>),
/// Create a Proxy database connection useful for proxying
#[cfg(feature = "proxy")]
ProxyDatabaseConnection(Arc<crate::ProxyDatabaseConnection>),
/// The connection to the database has been severed
Disconnected,
}
// sea_orm: src/database/connection.rs
pub trait ConnectionTrait: Sync {
/// Fetch the database backend as specified in [DbBackend].
/// This depends on feature flags enabled.
fn get_database_backend(&self) -> DbBackend;
/// Execute a [Statement]
async fn execute(&self, stmt: Statement) -> Result<ExecResult, DbErr>;
/// Execute a unprepared [Statement]
async fn execute_unprepared(&self, sql: &str) -> Result<ExecResult, DbErr>;
/// Execute a [Statement] and return a query
async fn query_one(&self, stmt: Statement) -> Result<Option<QueryResult>, DbErr>;
/// Execute a [Statement] and return a collection Vec<[QueryResult]> on success
async fn query_all(&self, stmt: Statement) -> Result<Vec<QueryResult>, DbErr>;
...
}
Thus, our code can simply depend on a DatabaseConnection, without ever needing to know the concrete type of the database used in the background. This abstraction ensures maximum portability of the code while maintaining a clear separation between application logic and the data storage layer.
Data optimization for storage
As of the release of iOS 26.0, there were1 (all models combined) more than 3875 iPhone firmwares, 6375 for iPads, 1500 for Macs, and 20 for Apple Vision Pro (VisionOS). It was therefore necessary to rethink and optimize the database schema to ensure that its size would not grow linearly with the number of processed files.
The most storage-intensive elements are:
- executables, identified by their full path on disk
- key/value entitlement pairs
- imported frameworks, also associated with their absolute path
To avoid duplicating this data across different OS versions, we set up several many-to-many relation tables, particularly between executables and OS versions, between executables and their entitlements, and between executables and the frameworks they use. This relational approach allows us to factorize information and save a significant amount of database space. On the other hand, queries become slightly more complex, requiring multiple joins to rebuild associations.
For example, the following query retrieves all OS versions in which a given executable is present:
SELECT osv.version AS "Versions"
FROM device d
LEFT JOIN operating_system_version osv ON osv.device_id = d.id
LEFT JOIN executable_operating_system_version eosv ON eosv.operating_system_version_id = osv.id
LEFT JOIN executable e ON e.id = eosv.executable_id
WHERE e.name = "launchd";
Model generation from migrations
Still on the topic of database management, sea_orm offers two approaches for model generation:
- Schema first: you write the migrations, and the library generates the models from the database (recommended approach if the schema changes frequently).
- Entity first: you declare your models, and sea_orm automatically generates table creation queries (but not migrations, which must be done manually). This approach is convenient for mostly stable schemas.
For our development, we opted for the recommended approach, allowing us to write migrations, apply them to our local database, then generate the associated models by connecting to the database (using the sea-orm-cli tool).
However, this approach raised an issue with SQLite (which is the database type we use in development). Since model generation relies on the concrete database schema, sea_orm offers a type mapping (full mapping available here):
| Rust Type | Database Type | SQLite Type | PostgreSQL Type |
|---|---|---|---|
| String | String | varchar | varchar |
| i32 | Integer | integer | integer |
| i64 | BigInteger | bigint | bigint |
| bool | Boolean | boolean | bool |
| Vec<u8> | Binary | blob | bytea |
Our primary keys are declared as PRIMARY KEY AUTOINCREMENT, which is only compatible with the INTEGER type.
CREATE TABLE devices (id BIGINTEGER PRIMARY KEY AUTOINCREMENT);
Parse error: AUTOINCREMENT is only allowed on an INTEGER PRIMARY KEY
The table schema must therefore reference INTEGER PRIMARY KEY AUTOINCREMENT, which are mapped to i32 by sea_orm, preventing us from having i64 as primary keys. A workaround was to let sea-orm-cli generate the models (thus i32), then replace i32 with i64 using sed. This is not an issue because in SQLite all INTEGER variants are mapped to 8 bytes according to SQLite’s data type documentation:
The INTEGER storage class, for example, includes 7 different integer datatypes of different lengths. This makes a difference on disk. But as soon as INTEGER values are read off of disk and into memory for processing, they are converted to the most general datatype (8-byte signed integer)
Use Cases
Setting up this tool makes it possible to address several recurring challenges encountered when performing large-scale analysis of Apple system images.
- Researching entitlements: by searching for an entitlement of interest (e.g.,
com.apple.private.security.no-container), the tool quickly lists all executables across all IPSW versions that request it. This makes it possible to identify which components benefit from special privileges. - Dependency analysis: by selecting a binary of interest, the researcher can view the list of imported frameworks and thereby understand its dependencies. Cross-referencing these dependencies across versions highlights evolutions in the OS architecture.
- Tracking OS version changes: by comparing the entitlements and dependencies of an executable between two IPSW versions, the analyst can detect changes (e.g., a new entitlement, or the disappearance of a framework).
- Correlation between platforms: by analyzing iOS, macOS, tvOS, and watchOS IPSWs, it becomes possible to study similarities and divergences between Apple platforms, particularly useful in vulnerability research contexts.
Thanks to its API, this tool can also be easily integrated into automated pipelines, for example to regularly index new IPSWs published by Apple and immediately detect changes of interest for security research.
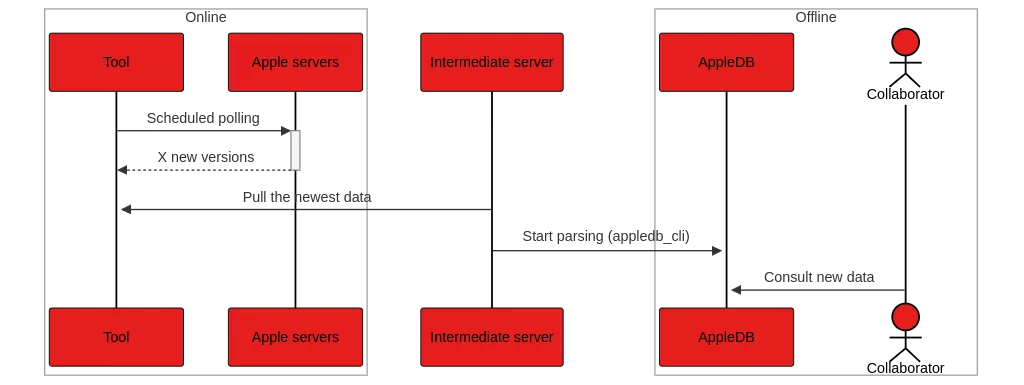
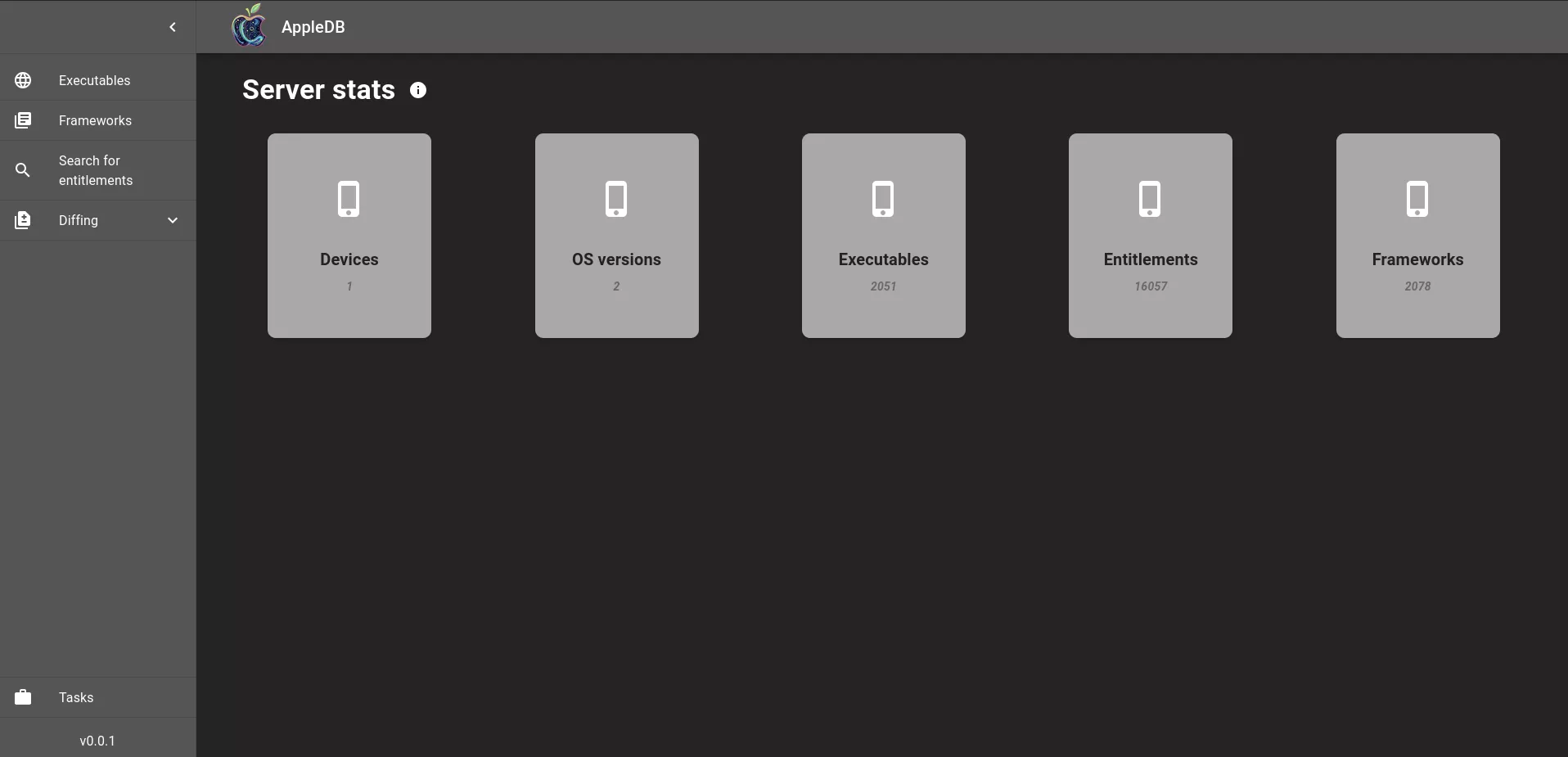
What’s next ?
Research on Apple platforms is becoming increasingly complex, particularly due to the multiplication of countermeasures and the size of system images. The appledb_rs project provides a concrete, open-source response to these challenges by offering a way to extract, structure, and explore the key information contained in IPSWs, while minimizing storage costs and facilitating analysis.
Beyond its direct use for entitlements and dependencies, this project opens the way to other applications, such as monitoring the evolution of binaries across versions, or building automated alerts as soon as new privileged components appear. By making this tool public, our goal is to provide the research community with a solid foundation that can be enriched with additional modules according to future needs.
- 1. figures retrieved using the ipsw.me API (https://api.ipsw.me/v4)